When RAG Is Not Enough: CAG, Hybrid Retrieval, and Working Memory
Reading order
Building AI Systems
Next chapter
No adjacent chapter
Series complete!
Congratulations! You finished this series. Here are recommended next steps:
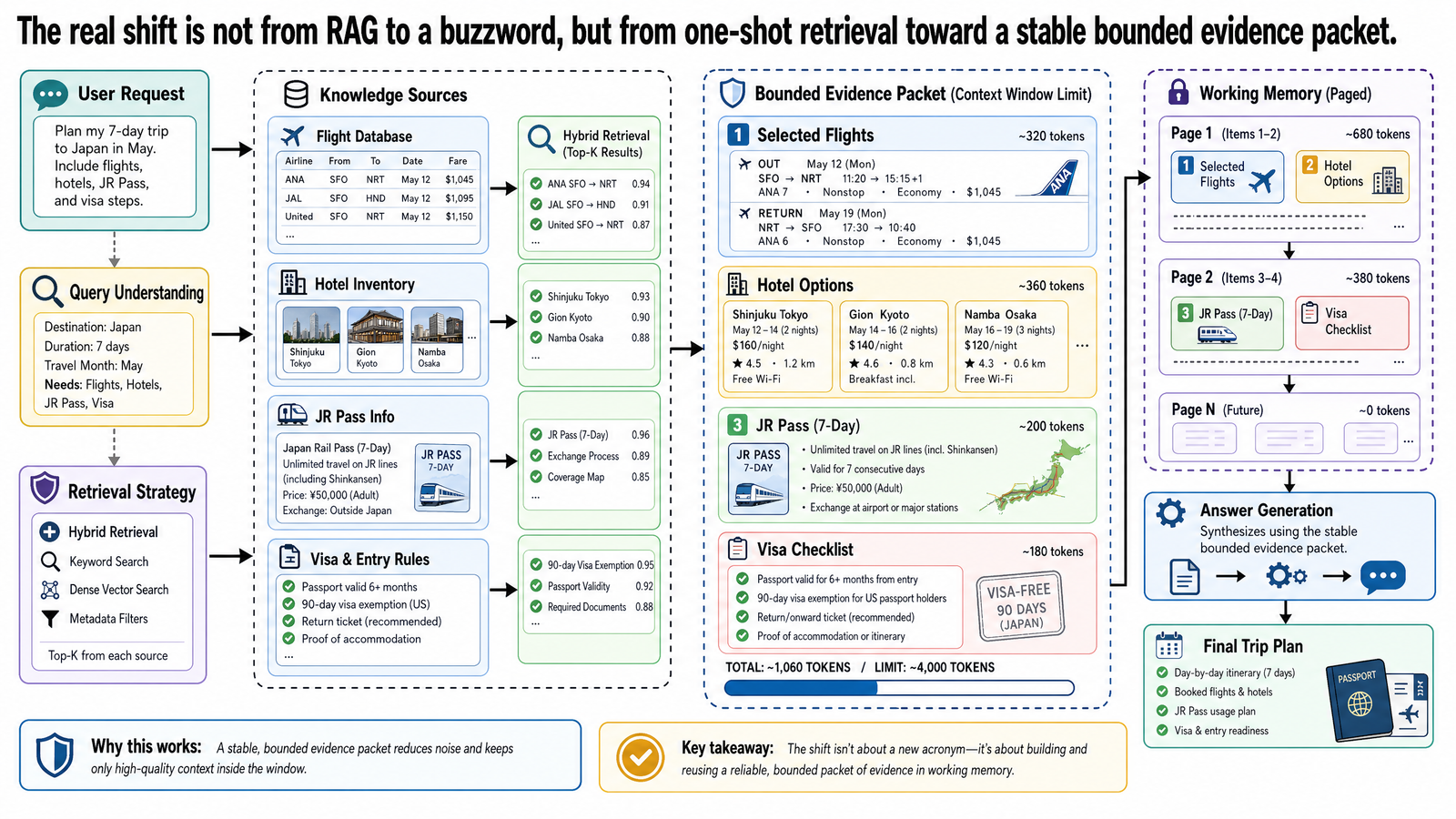
Table of Contents
- Why Basic RAG Is Still the Default
- Where Standard RAG Starts to Strain
- What CAG Actually Means
- Long Context Is Not Free Intelligence
- Prompt Caching Is Not the Same Thing
- Working Memory Is Temporary, Not Durable
- Hybrid Grounding: Retrieve Broadly, Reason Locally
- Decision Criteria: RAG, CAG-Leaning, or Hybrid
- What This Post Is Not
- Common Misconceptions
- Failure Modes to Design Around
- Practical Guidance for Engineers
- The Bridge to Document Intelligence
- Source Notes
Basic retrieval-augmented generation, or RAG, is still the default grounding pattern for most production systems. If you have a large corpus, frequent updates, and a need to show where an answer came from, retrieval remains the cleanest starting point. But there is a practical limit case where simple RAG begins to strain: the system can find the right documents, yet the task now depends on sustained reasoning across a bounded set of evidence and several follow-up questions about that same case.
That is the point where teams often start using overloaded language. Some call the next step "long-context AI." Some call it "memory." Some call it "CAG." The terms are not interchangeable, and the architecture choices are not cosmetic. This post is not another general memory explainer. It is about advanced grounding once a task needs a stable evidence packet across repeated follow-up. If the goal is a reliable grounded system, it helps to separate five different things: standard RAG, large context windows, emerging CAG terminology, hybrid retrieval patterns, and temporary working memory.
This post starts from that boundary case. The question is not whether RAG is obsolete. It is when a retrieval-only interaction stops being the whole design and when it makes sense to add a bounded evidence packet that the model can work over repeatedly. Agent loops are one place this shows up, but the deeper issue is broader: repeated investigative workflows need more stable grounding than fresh top-k retrieval can always provide.
Why Basic RAG Is Still the Default
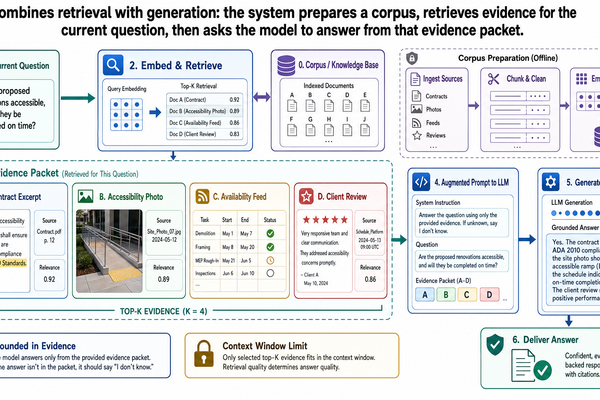
RAG remains the baseline because it solves a common production problem well. A model needs access to information that is too dynamic, too large, or too organization-specific to rely on model weights alone. A retriever searches the corpus, returns a focused set of passages, and the model answers from that material rather than from unsupported recall.
That architecture has several practical advantages:
it scales better than stuffing a whole corpus into every prompt
it can reflect fresh data without retraining the model
it gives you a path toward provenance and answer attribution
it creates a clean boundary between knowledge storage and answer generation
For the travel copilot used throughout this series, standard RAG is a natural fit for questions like: "Have we previously booked accessible ryokans in Kyoto during cherry-blossom season?" The relevant evidence may live across supplier contracts, past itineraries, accessibility audit reports, and seasonal availability feeds. The corpus is too broad and too changeable to preload wholesale, so retrieval is the correct first move.
That baseline matters because many teams skip it too quickly. If the workload is mostly one-shot question answering over a large, changing corpus, basic RAG is usually still enough. The more complex patterns in this post are for the cases where retrieval is necessary but no longer sufficient on its own.
Where Standard RAG Starts to Strain
A simple RAG loop often assumes a narrow interaction:
receive the query
retrieve the top evidence
generate the answer
That works well when the answer can be grounded in a small retrieved set and the user is unlikely to push much further. It works less well when the user wants to interrogate the same evidence repeatedly, compare many fragments across documents, or ask follow-up questions that depend on the exact same packet of context.
Consider this task from the travel copilot:
For booking JPN-2026-0417, assemble the trip file: compare our three shortlisted flight options with four hotel candidates rated for wheelchair accessibility, then cross-reference the two tour packages, the JR Pass analysis, and the visa checklist so the agent can answer follow-up questions about trade-offs.
The first half of that task still looks like RAG. The system must search a larger knowledge base to find the relevant flight inventories, hotel contracts, accessibility reviews, and supplier terms. But once that evidence is found, the challenge changes. The model is no longer answering from a few isolated snippets. It now has to reason across a trip file:
three flight-option comparisons with layover and accessibility details
four hotel candidates with wheelchair-accessibility ratings and pricing
two tour-package proposals covering day excursions
JR Pass cost-benefit analysis, visa checklist, and accessibility notes tied to the same booking
If each follow-up question triggers a fresh retrieval cycle with a different top-k slice, several problems appear:
evidence can fragment across separate retrieval results
small ranking changes can produce inconsistent answers between turns
the system may spend time rediscovering the same trip-file material
citations can drift because each answer is assembled from a slightly different subset
This is the practical edge where teams start looking beyond plain retrieval. The issue is not that retrieval failed. The issue is that the active task now needs a stable, bounded working set.
What CAG Actually Means
CAG, short for cache-augmented generation in the Chan et al. paper, should be treated as emerging terminology rather than settled industry doctrine. The paper's core idea is narrower than many online summaries suggest: if the relevant knowledge resources are limited and manageable in size, you can preload them into the model's context, precompute the key-value (KV) cache for that knowledge-augmented prompt, and reuse that cached state for subsequent queries rather than performing real-time retrieval each time. The KV cache precomputation is the specific mechanism that makes this practical: subsequent queries skip both retrieval and prompt processing for the knowledge portion, paying only the cost of encoding the new query against the already-cached prefix.
Infrastructure perspective. This post treats KV cache as an application-level optimization -- precomputing cached state for bounded corpora. For the GPU memory management view of KV cache (how it's physically allocated, why it fragments, and how PagedAttention solves it), see Infrastructure Post I-02: Paged KV Cache.
That framing is useful, but it has boundaries.
First, CAG in this sense is not a universal replacement for RAG. It assumes a corpus that is bounded enough to fit the design. Second, it is not the same thing as "the model has a huge context window." Long context is a capability. CAG is an architectural pattern built around using that capability under constrained conditions. Third, the term itself is not yet a stable category across the industry. Many systems that behave similarly will not use the name at all.
The easiest way to think about it is this:
RAGasks: how should I fetch the right evidence from a larger store?CAGasks: when the relevant knowledge is bounded, should I preload it and reuse that loaded state?
That distinction matters because it keeps the decision grounded in corpus properties instead of branding. A small product-manual assistant with rare updates might be a plausible CAG-leaning case. A large legal research corpus with constant updates is not.
Long Context Is Not Free Intelligence
The availability of larger context windows has encouraged a lazy design reflex: if retrieval is hard, just put more text into the prompt. That is not a reliable substitute for evidence selection.
Long-context models still have to attend to the right material inside that window. The Lost in the Middle results (Liu et al., 2024) are a useful warning here: performance can degrade when relevant information is buried within a long input, especially when important details sit away from the beginning or end. The severity of this effect varies across models and appears to have been reduced in some newer architectures, so it should be treated as an empirically observed tendency rather than an iron law. Still, the underlying lesson holds: a bigger window does not remove the need to curate and structure context.
That leads to two practical consequences.
The first is quality. If you dump an oversized packet into context, the model may miss the crucial rate column in a hotel comparison, over-weight a repeated cancellation clause, or fail to connect the right accessibility note with the right property listing. Larger windows raise the ceiling on what can be included, but they do not guarantee disciplined use of that material.
The second is economics. Large prompts have real prefill cost and latency. Even when the model technically accepts the context, the system may become too slow or too expensive if it keeps rebuilding that prefix. Any claim that long context is "faster" has to be read with an amortization caveat: it only becomes compelling when the same large prefix is reused enough times to justify the initial cost.
This is why "put the whole knowledge base into context" is usually a category error. It may work for a bounded corpus or a tightly scoped task, but it is not a general grounding strategy.
Prompt Caching Is Not the Same Thing
Prompt caching adds another source of confusion. Vendor prompt caching is a runtime optimization that can reduce cost and latency when a prompt prefix is reused. It does not, by itself, define how a system chooses knowledge, updates evidence, or separates durable stores from temporary context.
That distinction is easy to blur because a system may use both:
an architecture that assembles a bounded evidence packet
a platform feature that caches the repeated prefix for later calls
Those are complementary, not equivalent. Prompt caching does not turn a bad evidence packet into a good one. It does not improve retrieval recall. It does not make stale material fresh. It is best understood as an execution optimization layered underneath a higher-level grounding design.
For technical decision-makers, this is a useful sanity check. If a proposal says "we do not need retrieval because the platform caches prompts," it is collapsing two different layers of the system. One is about runtime efficiency. The other is about knowledge architecture.
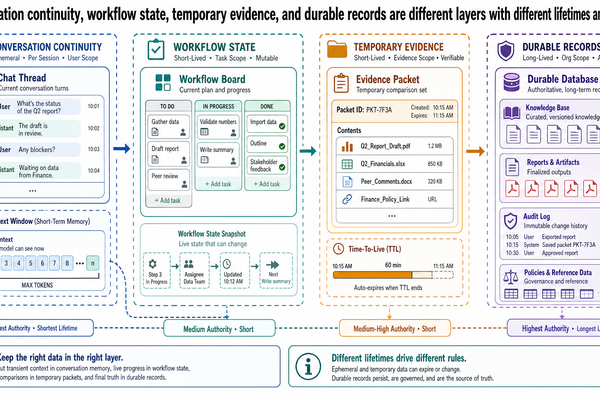
Working Memory Is Temporary, Not Durable
The term "working memory" is a better fit for many real systems than "memory" alone. It describes the active material the model is currently using for a task, not a durable store of truth and not a long-term record of organizational knowledge.
In the JPN-2026-0417 trip file, a bounded evidence packet can serve as working memory for the current case:
the three shortlisted flight options with layover and accessibility details
the four hotel comparisons with wheelchair-accessibility ratings
the two tour-package proposals
the JR Pass analysis and visa checklist
the current question and intermediate notes about what has already been compared
That packet can support an initial itinerary recommendation and several follow-up questions. But it should still be treated as temporary state. It is not a replacement for the source repositories. It is not automatically reusable for another booking. And if it becomes stale or incomplete, the right fix is to reassemble the packet from authoritative sources, not to pretend the temporary context has become durable knowledge.
This separation matters operationally. Teams get into trouble when they treat active task context as if it were a curated knowledge base. The result is often silent drift: old fare quotes remain in the packet, newer supplier availability is never pulled in, and the system answers confidently from yesterday's working set.
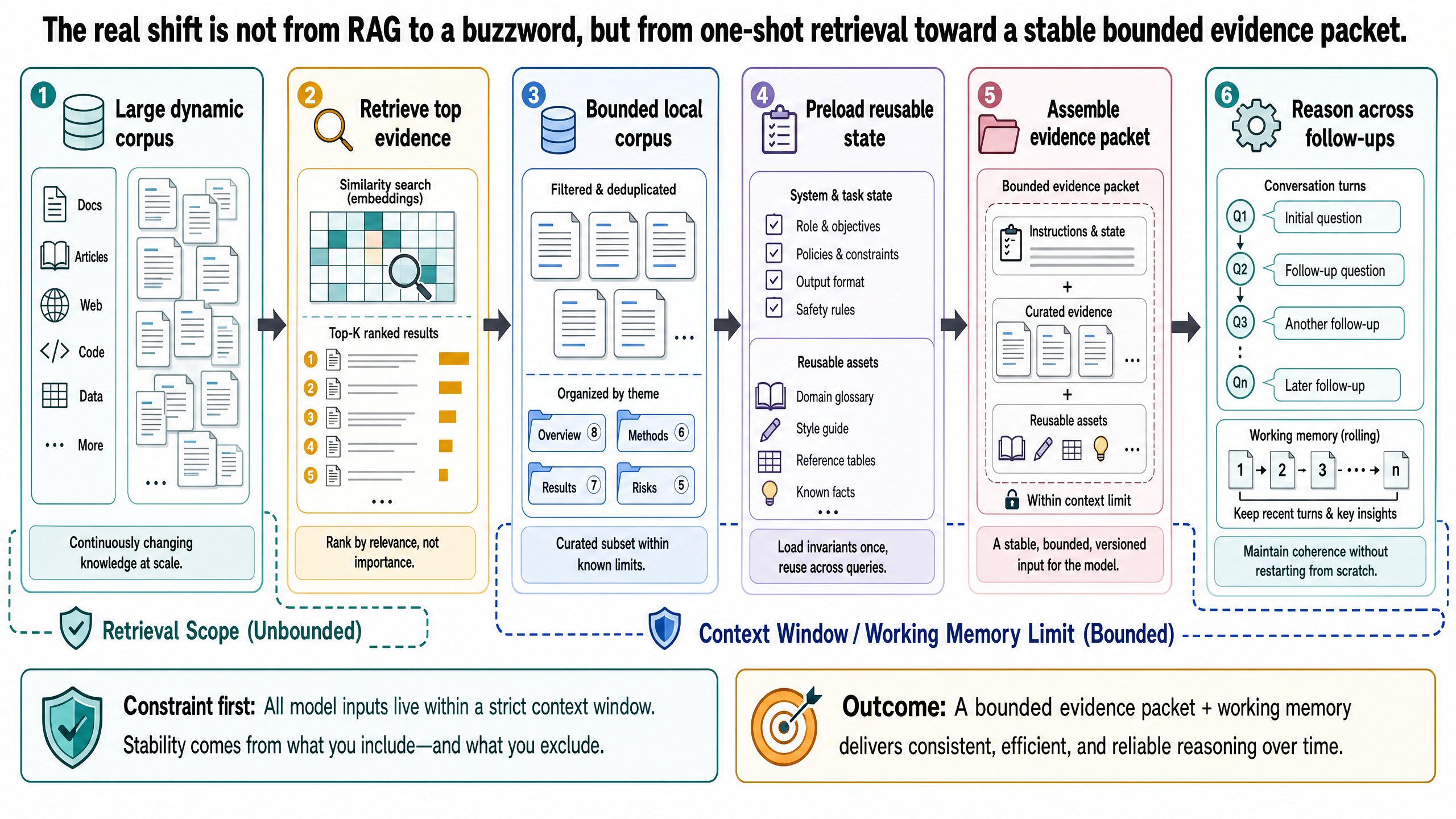
Hybrid Grounding: Retrieve Broadly, Reason Locally
The most practical pattern in many advanced systems is not "RAG versus CAG." It is a hybrid: retrieve broadly from the larger corpus, then reason locally over a bounded evidence packet.
This is best treated as a design pattern, not a buzzword. The architecture is straightforward:
search the large and dynamic corpus with retrieval
assemble the task-specific evidence packet
place that packet into the model's active context as temporary working memory
answer the main question and follow-up questions from that bounded packet
refresh or rebuild the packet when the task changes or the evidence becomes stale
For the travel copilot, that means retrieval still does the hard work of locating the right flight inventories, hotel contracts, accessibility audits, and supplier terms across a broad knowledge base. But once the system has isolated the JPN-2026-0417 trip file, the model can stay grounded in that local packet across several analytical turns.
This pattern has a few concrete advantages:
search and scalability stay tied to the external corpus rather than to context-window size alone
follow-up answers can stay more consistent because they draw from the same packet
the system can structure the packet deliberately instead of relying on a fresh top-k result each turn
runtime caching may help if the same packet is reused, without changing the architectural boundary
Just as importantly, hybrid grounding has real failure modes:
the initial retrieval can still miss critical evidence
the packet can become too large and recreate the same long-context problems it was meant to solve
citations can become less faithful if synthesis spans too many loosely organized fragments
teams may stop refreshing the packet even when the source corpus changes
So hybrid does not mean "more text." It means a two-stage design with explicit roles: retrieval for broad search, bounded context for local reasoning.
Decision Criteria: RAG, CAG-Leaning, or Hybrid
The cleanest way to choose among these patterns is to look at four variables: corpus size, update frequency, follow-up depth, and tolerance for preloading cost.
Choose a RAG-first design when:
the corpus is large or continuously changing
each question may need a different slice of evidence
provenance and freshness are primary requirements
most interactions are one-shot or shallow follow-ups
Choose a CAG-leaning design when:
the relevant knowledge resource is genuinely limited and manageable
updates are infrequent enough that preloading is operationally reasonable
the same loaded context will be reused enough times to justify its cost
the system does not depend on open-ended search across a much larger store
Choose a hybrid design when:
the corpus is too large or too dynamic to preload wholesale
the active task narrows to a bounded case file after retrieval
users ask several follow-up questions over the same evidence packet
consistency across turns matters more than re-running retrieval every time
This is also the right place to state a misconception directly: these are not mutually exclusive categories. Many production systems are RAG-first at the outer layer and CAG-like only inside a local task boundary.
What This Post Is Not
This is not a second memory post. Post 4 separated conversation memory, task state, working memory, and durable knowledge. This post takes working memory as given and focuses on how to fill it: when standard retrieval is enough, when bounded preloading helps, and when hybrid grounding is the right pattern. It is also not a document-intelligence post; the structural challenges of tables, layout, and cross-document matching come in Post 8.
Common Misconceptions
One common mistake is to assume that if documents fit into context, the architecture problem is solved. It is not. Relevance selection, evidence ordering, and packet structure still matter.
Another mistake is to treat CAG as a mature umbrella term that cleanly classifies the industry. It does not. The concept is useful, but the label is still emerging and should be used carefully.
A third mistake is to think hybrid grounding means dumping more data into the prompt. The actual pattern is selective: broad retrieval first, then a bounded packet designed for the current task.
The last recurring mistake is to treat a case packet as long-term memory. Working memory is temporary. Durable knowledge still belongs in governed source systems and indexed stores.
Failure Modes to Design Around
Advanced grounding strategies tend to fail in predictable ways.
Stale context is one. A preloaded manual, an old evidence packet, or a reused prefix can quietly diverge from the source of truth.
Middle-context loss is another. Even if the right fact is technically present, the model may not use it well if the packet is oversized or poorly organized.
Amortization assumptions also fail in practice. A large prefix only pays off if it is reused enough times. If every turn rebuilds a different packet, the expected latency benefit disappears.
Growth can break bounded-corpus assumptions. A pattern that works for a small manual or a narrow product catalog may stop working when the corpus expands or update frequency rises.
Finally, citation quality can degrade under synthesis pressure. When a model reasons across many fragments, it becomes easier to produce an answer that sounds grounded while blurring which source actually supports which claim. That is a system design problem, not just a model problem.
Practical Guidance for Engineers
Start by assuming plain RAG is enough until the workload proves otherwise. The burden should be on the more complex architecture to justify itself.
When simple RAG starts to strain, look for a specific symptom rather than for a trend label. Are users asking repeated follow-ups over the same evidence? Is retrieval returning the right documents but not preserving a stable case context? Is latency dominated by repeated reconstruction of the same prefix? Those are concrete reasons to consider a bounded working-memory layer.
If you adopt a hybrid pattern, make the boundaries explicit:
what retrieval system chooses the packet
what goes into the packet and in what structure
how long the packet lives
when it must be refreshed
how citations are preserved back to the source records
That explicitness is what keeps "hybrid grounding" from becoming empty language. It is only useful if each layer has a clear responsibility.
The Bridge to Document Intelligence
This post has treated evidence mostly as text plus extracted structured data. That simplification is about to break.
In real travel and enterprise systems, many of the hardest retrieval problems are not just about finding the right document. They are about finding the right rate table, accessibility certificate, cancellation clause, layout region, and cross-page relationship inside the document. Once the evidence packet includes supplier PDFs, comparison charts, property floor plans, and visual structure, assembling working memory becomes a document-intelligence problem as much as a retrieval problem.
That is the bridge to the next post. Before a system can build a reliable evidence packet for long-context reasoning, it has to understand how documents are structured in the first place.
Source Notes
This post draws on the following primary and official sources:
Lewis, P., Perez, E., Piktus, A., et al. "Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks." Baseline reference for RAG as retrieval-conditioned generation with external memory. arxiv.org/abs/2005.11401
Chan, C.-M., Xu, C., Yuan, R., et al. "Don't Do RAG: When Cache-Augmented Generation is All You Need for Knowledge Tasks." Reference for CAG as a bounded-corpus pattern; this post treats the term as emerging rather than settled. arxiv.org/abs/2412.15605
Liu, N. F., Lin, K., Hewitt, J., et al. "Lost in the Middle: How Language Models Use Long Contexts." Reference for the caution that larger context windows do not remove evidence-selection problems. aclanthology.org/2024.tacl-1.9
OpenAI. "Prompt caching." Official reference used to distinguish runtime prompt-cache optimization from retrieval, memory policy, or knowledge architecture. developers.openai.com/api/docs/guides/prompt-caching
Anthropic. "Context windows." Reference for context as bounded working memory rather than unlimited reliable knowledge. docs.anthropic.com/en/docs/build-with-claude/context-windows
Huang Tzu Lin
With over five years in autonomous robotics, there's a strong passion for incorporating cutting-edge technologies and innovative approaches. Dedicated to transforming the latest research and insights into practical applications, this journey pushes the limits of possibility.
Related Posts
Stay Updated
Get the latest technical insights delivered to your inbox.