Agent Loops in Practice: ReAct, Tools, and Failure Modes
Reading order
Building AI Systems
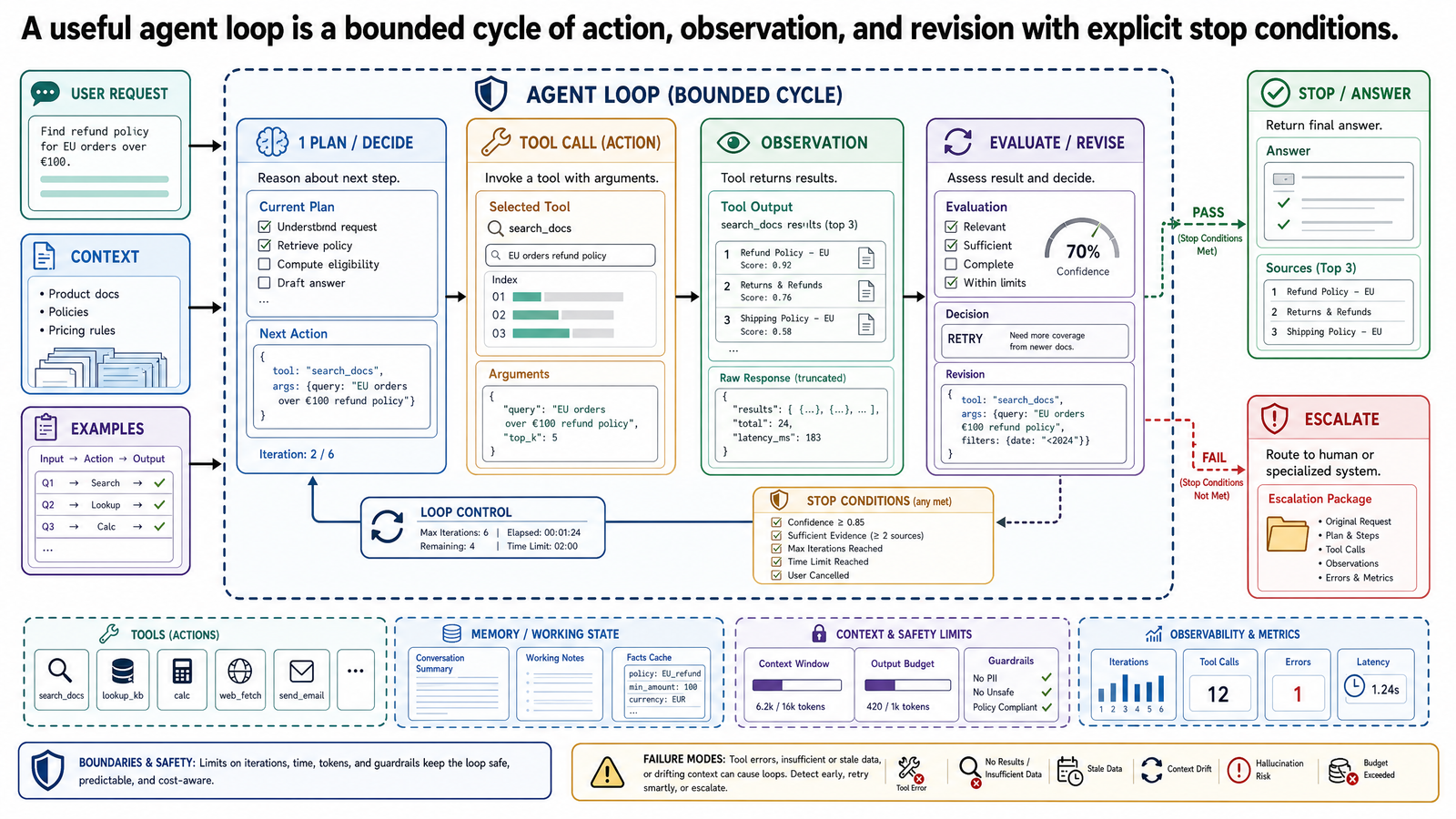
Table of Contents
- What This Post Is Not
- The Minimal Operational Loop
- A Bounded Example: Building A Complete Itinerary
- ReAct As A Reference Pattern, Not A Religion
- Tools Are Interface Contracts
- Observation Is Environment Feedback
- Planner-Executor Splits And When They Help
- Retry Is A Policy, Not A Reflex
- Escalation And Stop Conditions Are Part Of The Design
- Common Failure Modes In Agent Loops
- Invalid Tool Arguments
- Incorrect Tool Choice
- Tool-Result Parsing Errors
- Premature Synthesis
- Repeated Loops Without New Information
- Missing Escalation
- Compounding Error
- Practical Guidance For Operational Design
- Why This Matters More Than Agent Branding
- Bridge: When Basic RAG Stops Being Enough
- Source Notes
Most engineering discussions about agents start too early with the word agent and too late with the operational loop. In practice, the important design question is simpler: once a model can take more than one step, how does the system decide what to do next, what tools it may call, what it is allowed to infer from the result, and when it must stop?
That is the real move from architecture concepts into operational agent design. A useful loop does not require a grand theory of autonomy. It requires a bounded cycle that can inspect the current state, choose the next action, observe the outcome, and either continue, escalate, or stop. If that cycle is vague, the system will fail in vague ways. If that cycle is explicit, the system becomes testable.
This post focuses on that loop. We will use a travel-planning copilot for OptiVerse Travel as the running example, and we will stay close to production concerns: tool contracts, observation handling, retry behavior, escalation rules, and failure modes. The goal here is operational loop design, not broader governance or auditability across the whole system.
Post 5 established the autonomy spectrum and introduced approval boundaries as a design concept. This post operationalizes that framing: once a system has bounded model-directed control, what does the runtime loop actually look like, and how does it fail?
What This Post Is Not
This is not a post about when to choose an agent over a workflow; that decision framework was covered in Post 5. It is not about advanced grounding or working-memory design; those come in Post 7. And it is not about full production governance or auditability; that belongs to the capstone in Post 10. This post owns the operational mechanics: loop structure, tool contracts, observation handling, retry policy, and stop conditions.
The Minimal Operational Loop
At the center of most agentic systems is a simple pattern:
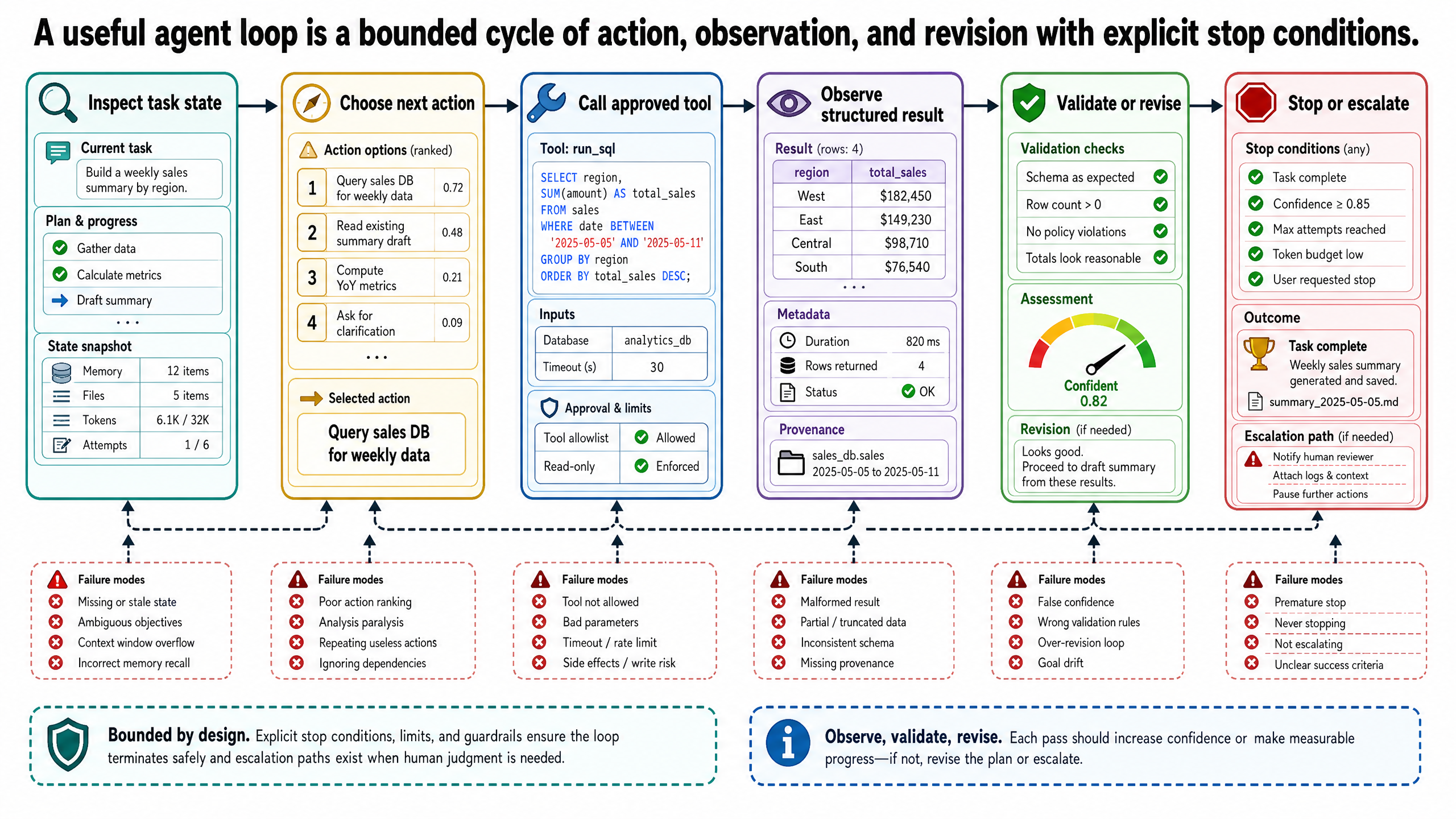
inspect the current task state
choose the next action
execute that action through a tool or controlled generation step
observe the result
revise the plan or stop
This is the practical core of a reason-act-observe loop. The model is not being treated as a magical autonomous worker. It is participating in a controlled cycle with an external environment. That environment includes tools, retrieved documents, validation checks, and explicit system state.
The loop matters because each step changes the next step. A one-shot assistant can only produce an answer from its current context. A looped system can gather evidence, detect gaps, revise its path, and decide that it should not continue.
That does not mean every system should be agentic. Many production tasks are better served by deterministic pipelines. But when the path to completion depends on intermediate observations, fixed workflows start to strain. That is where an agent loop becomes useful.
A Bounded Example: Building A Complete Itinerary
Consider a concrete task for the OptiVerse Travel copilot:
Build a 10-day accessible Japan itinerary for cherry-blossom season — family of four, wheelchair user, $13K–$15K budget (JPN-2026-0417).
This is a good agent-loop task because the system cannot assume in advance which flights, hotels, or rail options will be available. It may need to check flight inventory, inspect hotel accessibility details, verify rail-pass coverage, and then decide whether the plan is complete enough to present to the client.
A bounded version of the loop might look like this:
Search flight availability for the preferred departure date to Tokyo.
Review the returned options and identify whether the preferred date is sold out or whether accessible seating is unavailable.
If the preferred date is sold out, broaden the search to adjacent days and check those results for price and accessibility fit.
Compare the viable flight dates against hotel availability for wheelchair-accessible rooms in the target cities.
If hotel dates conflict with the adjusted flights, shift the hotel block and re-verify availability.
Check JR Pass coverage for the planned Shinkansen legs — the Nozomi is not included in the base JR Pass (a supplementary ticket option exists since October 2023, but adds cost), so the system defaults to Hikari or Sakura services and adjusts transit times accordingly, noting the Nozomi supplement as an alternative for the consultant to consider.
Recheck the total budget against the $13K–$15K constraint. If the evidence is sufficient, present the revised itinerary with explicit notes on trade-offs. If the plan still exceeds budget or has unresolved conflicts after the allowed search attempts, stop and escalate.
What makes this an agent loop is not the number of steps. It is the fact that the next step depends on environment feedback from the previous one. The system is not following a rigid script. It is revising within a bounded task.
ReAct As A Reference Pattern, Not A Religion
The ReAct pattern is a useful reference because its core contribution is showing that explicit reasoning traces, generated by the model as text, improve action quality when interleaved with tool use. The paper demonstrated that models perform better when they generate a reasoning step before each action rather than acting without explanation or reasoning without acting. That insight helped shift agent discussions away from one-shot prompting and toward structured interaction with an external environment.
The important part is the interleaving of reasoning and action, not the branding. A production system does not need to expose a verbose chain of thought or imitate a research demo. It does need the same structural discipline:
the model should have a limited set of allowed actions
each action should produce a structured observation
observations should update task state
the loop should have explicit stop conditions
In some systems, the reasoning step is a short hidden planning state. In others, it is an explicit planner-executor split where one component proposes a step and another carries it out. Both can still be understood as reason-act-observe systems.
Tools Are Interface Contracts
Tool use is often described as if the model simply "has access" to a search API, a database, or a code runner. That framing is too loose. Tools are interface contracts.
For an agent loop, the tool contract usually includes:
a tool name
a description of when the tool should be used
an input schema
constraints on valid arguments
a result format
an error format
iteration or permission limits
These fields are not administrative details. They shape behavior. A vague tool description produces vague tool selection. A weak schema produces malformed calls. An inconsistent result format makes observation handling brittle.
Suppose the travel copilot has a flight-search tool like this:
{
"name": "search_flights",
"description": "Search available flights by origin, destination, date range, and accessibility requirements.",
"input_schema": {
"type": "object",
"properties": {
"query": { "type": "string" },
"date_range": { "type": "string" },
"accessibility": { "type": "string", "enum": ["wheelchair", "none"] },
"max_results": { "type": "integer", "minimum": 1, "maximum": 10 }
},
"required": ["query", "date_range"]
}
}Even this small schema encodes important operational boundaries. It tells the model what the tool is for, what fields are expected, and how much search breadth is allowed in one call. If max_results were unconstrained, the loop might waste time pulling too many options. If accessibility were undocumented, the model might guess a field value that the tool does not accept.
The same applies on the output side. If the tool sometimes returns raw text, sometimes a JSON object, and sometimes a vague error string, the loop becomes difficult to control. Observation handling works best when tool outputs are as structured as tool inputs.
Observation Is Environment Feedback
The observe step is where many explanations get fuzzy. Observation is not mystical introspection. It is environment feedback.
In an operational system, an observation may be:
a successful tool result
a validation failure
a missing field
a timeout
an access-control denial
an availability confidence score below threshold
a signal that no matching flights or hotels were found
Each of these outcomes should affect the next step differently.
If the flight-search tool returns several viable options on adjacent dates, the next step may be hotel-availability verification. If the tool returns zero results for the target date range, the loop may broaden the window once. If a hotel-accessibility check returns incomplete room data, the loop may retry with a different property or escalate to a human agent. If access to a partner booking API is denied, the loop should not keep trying with slight variations of the same forbidden request.
This is why observation handling belongs in the system design, not just in the prompt. The loop needs policy about how to interpret different classes of result. Otherwise the model is left to improvise recovery behavior from ambiguous evidence.
Planner-Executor Splits And When They Help
A single loop can be enough for compact tasks, but some systems benefit from splitting planning from execution. In a planner-executor pattern, one component decides the next subtask and another component performs it under tighter controls.
For the travel copilot, a planner might produce:
search flights to Tokyo for the target week, filtering for wheelchair-accessible seating
verify hotel availability and accessibility in Kyoto and Tokyo for the matching date window
check JR Pass rail coverage for the planned Shinkansen segments — default to Hikari or Sakura services (Nozomi requires a supplementary ticket beyond the base pass)
synthesize only if flights, hotels, and rail all fit within the $13K–$15K budget and accessibility constraints
The executor then carries out each step through tools and records observations. This split can improve clarity because the execution component does not need to invent the whole strategy on each turn. It only needs to complete the next bounded action.
The trade-off is complexity. A planner-executor system introduces another interface, another state representation, and another place for errors to accumulate. Many teams add this separation too early. The more defensible approach is to start with the minimal loop and only split roles when the task structure clearly benefits from it.
Retry Is A Policy, Not A Reflex
Once tools are in the loop, failures become normal. A booking API may time out. A hotel-availability check may fail on one property. A tool call may be rejected because the model passed the wrong field. The design question is not whether failures happen. It is what kinds of failure deserve a retry.
Retry should be selective and bounded.
A reasonable policy for the travel copilot might look like this:
retry once if the tool call failed because of malformed arguments and the correction is obvious
retry once with a broader date window if the original flight search returned no results for the preferred date
do not retry indefinitely when the tool reports
no availabilitydo not retry access-denied operations unless the workflow includes a human approval path
stop retrying when repeated attempts do not add new information
This matters because repeated tool use can create the illusion of diligence while actually compounding error and cost. A loop that searches five times with slightly adjusted date ranges but never changes its constraint set is not reasoning. It is stalling.
Some agent systems also include reflective revisions after a failed step. That can be useful when the failure contains actionable feedback. But the recovery loop still needs limits. A system that always tries one more revision can wander indefinitely.
Escalation And Stop Conditions Are Part Of The Design
A practical loop needs more than a success path. It also needs explicit exits.
The three most important exits are:
complete: the task has enough evidence to produce the requested outputabstain: the task cannot be completed reliably with the available evidence and permissionsescalate: the task requires human review, approval, or interpretation
These outcomes should be designed in advance, not invented at the last minute.
For the travel copilot, stop conditions might include:
stop and synthesize when flights, accessible hotels, and rail options all align within the budget and date window
stop and abstain if no viable flight-and-hotel combination is found after the search budget is exhausted
escalate if a hotel's accessibility data is ambiguous or contradictory and cannot be resolved by tool queries alone
escalate if the task would require issuing a booking, charging a client card, or overriding a travel advisory
stop if the loop exceeds its maximum number of tool calls or latency budget
Notice that these conditions combine evidence sufficiency, risk, and operational budget. That combination is important. A system can fail not only by being wrong, but also by taking too long, costing too much, or acting past its authority boundary.
Common Failure Modes In Agent Loops
Once loops are introduced, failures become sequential rather than isolated. One bad observation can distort the next action. One weak retry policy can produce an expensive spiral. Some of the most common failure modes are straightforward:
Invalid Tool Arguments
The model calls a tool with the wrong field names, the wrong types, or impossible parameter combinations. Strong schemas help, but they do not remove the problem. The system still needs argument validation and a clear response path when validation fails.
Incorrect Tool Choice
The loop calls flight search when it should check hotel availability, or calls a rail-coverage lookup before verifying that the base flights are even bookable. This often comes from weak tool descriptions or from prompts that overemphasize acting over evidence gathering.
Tool-Result Parsing Errors
Even a correct tool call can fail downstream if the observation is parsed badly. If the loop misreads an empty array as a hard failure or ignores an availability confidence score in the result, the next step may be inappropriate.
Premature Synthesis
This is one of the most damaging failure modes. The loop gathers partial evidence, then generates a polished itinerary before the task has actually been grounded. The output looks finished, but the underlying evidence trail is thin or inconsistent.
Repeated Loops Without New Information
The system keeps searching, re-checking, or adjusting dates with no meaningful change in state. This wastes tokens, increases latency, and can falsely signal that the loop is "working hard."
Missing Escalation
The loop encounters ambiguity or a permissions boundary but lacks a formal path to hand off control. Instead, it keeps trying to solve a task that should have moved to human review.
Compounding Error
An early mistake in flight search or hotel verification carries forward into planning and synthesis. Because later steps depend on earlier observations, looped systems can amplify a small error into a misleading final itinerary.
These failure modes are not arguments against agent loops. They are arguments for disciplined loop design.
Practical Guidance For Operational Design
If you are moving from agent concepts to implementation, a few design rules go a long way.
First, keep the action space small. The model should have only the tools it actually needs for the task. Extra tools increase ambiguity and error surface.
Second, make tool schemas strict and outputs structured. The interface should be easy to validate before and after execution.
Third, store observations as explicit task state rather than leaving the model to reconstruct history from raw conversation. This makes the loop more inspectable and reduces accidental drift.
Fourth, separate recoverable failures from terminal ones. A malformed argument may justify one retry. An access-control denial usually does not.
Fifth, define stop conditions early. Evidence thresholds, maximum iterations, latency budgets, and approval boundaries should be part of the initial design.
Sixth, evaluate the loop as a system. It is not enough to ask whether the final answer sounds reasonable. You need to inspect the trajectory: which tools were called, what observations came back, where retries occurred, and whether the loop should have stopped sooner.
Why This Matters More Than Agent Branding
Teams often spend too much time debating whether a product "counts" as an agent and too little time specifying the loop contract. That is backwards.
From an engineering standpoint, the meaningful questions are operational:
what decisions can the model make on its own
what tools can it call
what observations will it receive
what state persists between steps
what triggers a retry
what triggers escalation
what forces a stop
Those questions determine reliability far more than the label on the architecture. A modest system with a narrow action space, clean tool contracts, and explicit stopping rules will usually outperform a more ambitious loop that is underspecified.
Bridge: When Basic RAG Stops Being Enough
A simple reason-act-observe loop is often enough to retrieve evidence, inspect results, and produce a grounded answer. But some tasks break the assumptions behind basic retrieval. The system may need to reason over a larger bundle of evidence across multiple steps, preserve a working set of documents and intermediate findings, or balance fresh retrieval against longer-lived context assembled for the current task.
That is where the next design layer appears. Agent loops are one place this problem shows up, but they are not the only one. More generally, once repeated investigative work needs a stable case packet instead of a fresh top-k retrieval on every turn, you have to think carefully about hybrid grounding, working memory, and when standard RAG no longer gives the system enough stable context to operate well.
That is the bridge to the next post. We will look at what changes when simple RAG is not enough, and why hybrid retrieval and working-memory patterns matter once a grounded system needs to reason over the same evidence repeatedly rather than merely fetch it.
Source Notes
This post draws on the following primary and official sources:
Yao, S., Zhao, J., Yu, D., et al. "ReAct: Synergizing Reasoning and Acting in Language Models." Core reference for interleaving reasoning, actions, and observations. arxiv.org/abs/2210.03629
Schick, T., Dwivedi-Yu, J., Dessi, R., et al. "Toolformer: Language Models Can Teach Themselves to Use Tools." Reference for learned tool-use decisions. arxiv.org/abs/2302.04761
Shinn, N., Cassano, F., Gopinath, A., et al. "Reflexion: Language Agents with Verbal Reinforcement Learning." Reference for bounded verbal feedback and revision loops without weight updates. arxiv.org/abs/2303.11366
Anthropic. "Building effective agents." Practitioner reference for simple composable agent patterns and the case against unnecessary framework complexity. anthropic.com/engineering/building-effective-agents
Anthropic. "Tool use with Claude." Official reference for tool schemas, result handling, and iteration limits. docs.anthropic.com/en/docs/agents-and-tools/tool-use/overview
National Institute of Standards and Technology. "Artificial Intelligence Risk Management Framework: Generative Artificial Intelligence Profile." Reference for bounded control, testing, and governance language. nist.gov/publications/artificial-intelligence-risk-management-framework-generative-artificial-intelligence
Tags
Huang Tzu Lin
With over five years in autonomous robotics, there's a strong passion for incorporating cutting-edge technologies and innovative approaches. Dedicated to transforming the latest research and insights into practical applications, this journey pushes the limits of possibility.
Related Posts
Stay Updated
Get the latest technical insights delivered to your inbox.