AI-Powered Customer Support — From Chatbot to Intelligent System
Reading order
LLM Foundations
Next chapter
No adjacent chapter
Series complete!
Congratulations! You finished this series. Here are recommended next steps:
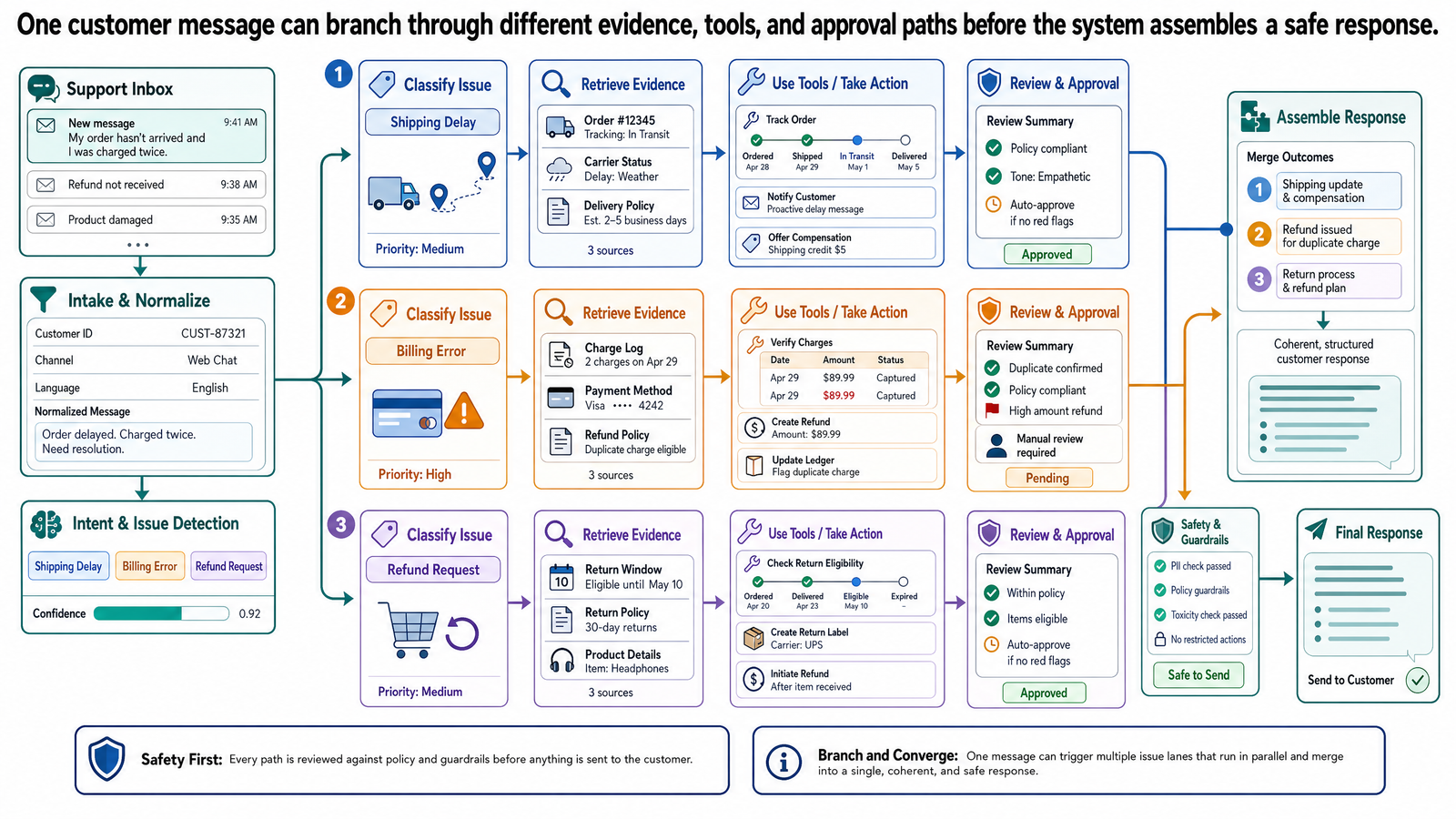
Table of Contents
- What a Basic Chatbot Does Wrong
- How Retrieval Fixes the Knowledge Problem
- How Tools Fix the Access Problem
- How Chain-of-Thought Structures the Work
- How the Autonomy Spectrum Applies
- How Memory Keeps the Conversation Coherent
- Where the System Must Stop and Ask a Human
- What the Customer Actually Experiences
- Why This Is a System, Not a Chatbot
- What This Post Is Not
- Where the Series Goes Next
- Sources and Further Reading
Customer support is a useful capstone example because one message can require retrieval, tool use, memory, routing, and approval boundaries at the same time.
A customer writes in to Relay, a project management SaaS product:
"I was charged twice for my Team plan last month, I can't access the new Gantt chart feature, and I need to downgrade before my renewal on Friday."
One message. Three problems. A billing dispute, a feature access issue, and an account change with a deadline two days away. Each problem has a different shape, different data requirements, and different stakes. A basic chatbot — the kind that pattern-matches keywords and returns canned responses — fumbles all three. It might address one, ignore two, or conflate them into a single generic answer about billing. A well-designed system handles each issue differently, because it recognizes that they are different.
This post shows how every concept from the previous four posts converges inside a single product. The customer support system is the example, but the lesson is architectural: the concepts you have learned — generation, prompts, context windows, grounding, retrieval, embeddings, tool use, memory, autonomy, and approval boundaries — are not isolated ideas. They are components that work together inside real applications.
What a Basic Chatbot Does Wrong
Start with the failure case, because it is instructive.
A keyword-matching chatbot sees "charged twice" and routes to a billing FAQ. It returns a generic paragraph: "To view your billing history, go to Settings > Billing. If you believe there is an error, please contact our billing team." It does not check whether a double charge actually occurred. It does not address the Gantt chart issue or the downgrade request. It treats the message as one problem and picks the first keyword it recognizes.
A slightly more sophisticated chatbot — one backed by a language model but without system architecture around it — does something different but also wrong. It generates a fluent, confident, three-part reply. For the billing issue, it quotes a refund policy. The problem is that the policy it quotes does not exist. The model generated text that sounds like a refund policy because refund policies follow predictable patterns in training data. This is hallucination, the same failure mode from Post 0-1. The model predicted statistically likely text, not factually accurate text.
For the Gantt chart access, the model suggests "clearing your browser cache and trying again." That is a plausible support response, but it ignores the actual cause: the customer's plan tier may not include Gantt charts. Without checking the customer's subscription against the feature entitlement matrix, the model is guessing. For the downgrade, the model cheerfully writes "I've downgraded your plan to Individual" — except it has no ability to modify a subscription. It performed no action. It generated text that looks like a confirmation.
Three issues, three failures. One from hallucination, one from lack of grounding, one from the gap between generating text and taking action. Each failure maps to a concept you already know.
How Retrieval Fixes the Knowledge Problem
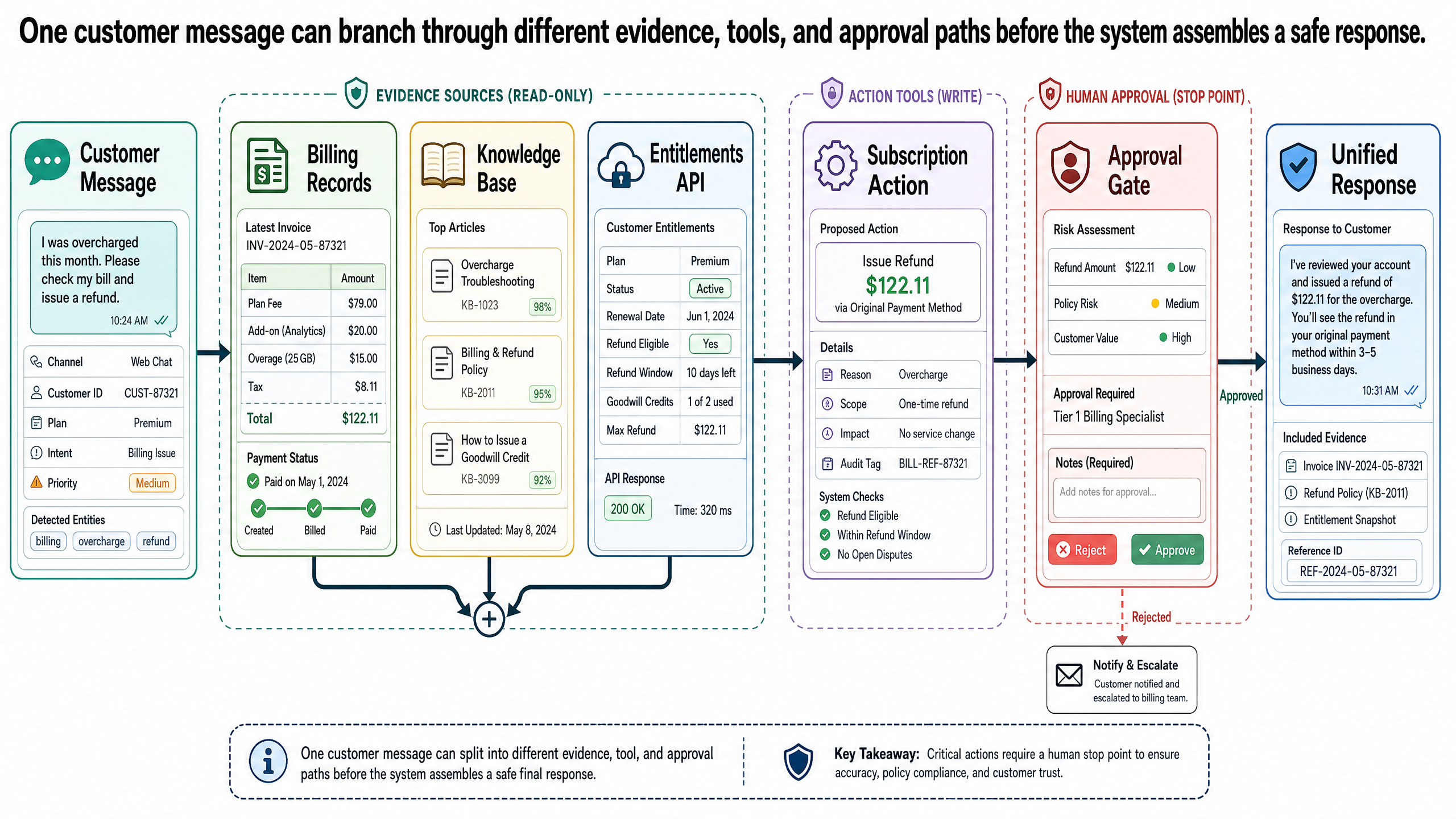
The billing question — "I was charged twice" — requires facts. Not the model's compressed patterns about billing in general, but this customer's actual billing record and Relay's actual refund policy.
This is the grounding problem from Post 0-3. The model's training data does not contain Relay's internal refund policy, and even if it did, policies change. The training cutoff makes any policy the model "remembers" potentially outdated. The solution is retrieval: before the model drafts a response, the system fetches the relevant information from authoritative sources.
For the billing question, the system needs two retrievals. First, it queries the billing database for the customer's recent charges. That lookup is precise and structured — an API call to the billing service returns transaction records, not a fuzzy search. Second, it retrieves the current refund policy from Relay's internal knowledge base. This second retrieval is where embeddings become relevant.
The customer wrote "charged twice." Relay's knowledge base might not have an article titled "Charged Twice." But it likely has articles covering "duplicate charges," "billing errors," and "refund eligibility." An embedding-based search — the same concept from Post 0-3, where text is converted to numerical representations and similar meanings cluster together — can match the customer's natural language to the right policy document even when the exact words differ. "I was charged twice" and "duplicate charge refund policy" share meaning, not keywords. Embedding similarity finds the match.
Now the model has what it needs: the actual billing record showing two charges of $49 on March 3rd, and the actual refund policy stating that duplicate charges are eligible for automatic refund within 30 days. The model generates a response grounded in evidence, not in statistical patterns about what refund policies typically say.
How Tools Fix the Access Problem
The second issue — "I can't access the new Gantt chart feature" — is a different kind of problem. The answer depends not on a policy document but on the relationship between the customer's current subscription plan and the feature's entitlement requirements.
A retrieval-only approach might find a help article about Gantt charts. But the article would describe the feature in general. To answer this customer's specific question, the system needs to check two things: what plan is this customer on, and which plans include Gantt chart access?
These are tool calls, the concept from Post 0-4. The system calls the subscription service API to look up the customer's current plan (Team, monthly billing). It calls the feature entitlements API to check which plans include Gantt chart access. The result comes back: Gantt charts require the Business plan or above. This customer is on the Team plan. The feature is not available at their tier.
But the system should do one more thing before drafting a response. It should check whether this is a known issue — perhaps Team plan users were temporarily granted access during a beta period that has since ended, or there is a bug causing the feature to appear unavailable. This is where embedding-based retrieval against the internal known-issues database adds value. A customer might follow up with "the chart thing isn't working" — vague, imprecise, no mention of "Gantt." But embedding-based search matches meaning, not keywords. "The chart thing isn't working" lands close to "Gantt chart — access requirements and known issues" in embedding space, the same way "family-friendly neighborhoods" matched "quiet residential area near light rail" in Post 0-3. If there is a current incident, the system surfaces it. If not, it can confidently attribute the access problem to plan limitations.
This is the difference between a model guessing ("try clearing your cache") and a system that checks. The model's role is synthesis and communication. The system's role is making sure the model has the right facts before it communicates.
How Chain-of-Thought Structures the Work
The customer sent one message with three problems. The system needs to recognize this and handle each issue on its own terms. This is where chain-of-thought reasoning — the step-by-step technique from Post 0-2 — appears not as something a user types into a prompt, but as something built into the system's own instructions.
The system prompt for Relay's support agent might include an instruction like: "When a customer message contains multiple issues, identify each issue separately. Classify each by category (billing, access, account, technical, general). Determine the required data sources and tools for each issue. Resolve issues independently before drafting a combined response."
This is the same reasoning technique you saw applied to trip planning in Post 0-2 — breaking a complex problem into explicit steps before attempting a final answer. The difference is that in a production system, this reasoning structure is designed into the system prompt rather than improvised by the user. Different customer tiers might even receive different system prompts — enterprise customers get prompts with broader action authority, while free-tier users get prompts with tighter constraints and earlier escalation triggers. The result: the system does not merge three distinct problems into one muddled answer. It processes them as three separate resolution paths that converge in a single response.
The classification step matters because it determines what happens next. A billing issue triggers a billing record lookup and policy retrieval. An access issue triggers subscription and entitlement checks. An account change triggers a different path entirely — one that involves approval boundaries.
How the Autonomy Spectrum Applies
Post 0-4 introduced the autonomy spectrum: the range from fixed pipelines and routed workflows through assistive systems (system helps, human drives) to bounded agents and long-running autonomous systems. A customer support system is one of the clearest places to see why different tasks within the same conversation belong at different points on that spectrum.
Billing lookup — automated. Checking a billing record and matching it against a refund policy is low-risk, high-confidence, and easily verified. The system can do this autonomously. It retrieves the data, confirms the duplicate charge, references the policy, and includes the finding in its response. No human needs to approve the lookup or the description of what happened.
Access diagnosis — semi-automated. The system can check the customer's plan, verify the feature matrix, and determine that Gantt charts require a higher tier. It can draft an explanation. But if there is ambiguity — the customer was in a beta program, or there is a known bug, or the entitlement data is inconsistent — the system should flag the issue rather than guess. This is abstention, from Post 0-3. The system has enough evidence to describe the situation but not enough to guarantee the diagnosis. It says what it knows and what it does not.
Downgrade with a deadline — requires human approval. The customer wants to downgrade before Friday's renewal. This involves modifying a subscription, which has financial and contractual implications. Even if the system has access to the subscription management API, acting on a downgrade request without human approval crosses an important boundary.
This is the describe/recommend/act framework from Post 0-4. For the downgrade, the system should:
Describe: "Your Team plan renews on Friday, March 22. A downgrade to the Individual plan would reduce your monthly charge from $49 to $19."
Recommend: "Based on your request, I can prepare the downgrade for processing."
Act: Only after a human agent confirms the downgrade, or the customer explicitly authorizes it through a verified action (not just a chat message).
The system can describe the situation and recommend a course of action. It cannot unilaterally execute an account change. That boundary exists because the cost of an error — downgrading the wrong account, downgrading when the customer actually wanted something else, processing a change that violates a contractual minimum — is higher than the cost of waiting for confirmation.
How Memory Keeps the Conversation Coherent
The customer's message is the beginning of a conversation, not the entirety of it. The system needs to track state across the interaction. This is where the memory concepts from Post 0-4 become operational.
Conversation memory holds the immediate exchange: what the customer said, what the system responded, what follow-up questions were asked. When the customer replies "No, I mean the chart feature I could see last week but now it's gone," the system needs the context of the original message to understand what "the chart feature" refers to.
Task state tracks the resolution progress: issue one (billing) resolved — duplicate charge confirmed, refund recommended. Issue two (access) in progress — plan checked, entitlement verified, awaiting customer acknowledgment. Issue three (downgrade) pending — described and recommended, awaiting approval. This state persists across messages and prevents the system from losing track of which problems have been addressed and which have not.
Durable knowledge is the stable information the system draws on: Relay's refund policy, the plan feature matrix, the subscription management rules. This information exists outside the conversation and does not change from message to message.
Now consider the context window constraint from Post 0-2. Suppose this customer has 47 past support tickets. The context window — the model's finite working memory — cannot hold all of them. The system must decide what context matters for this conversation. A well-designed system might retrieve summaries of the three most recent tickets, or only tickets related to billing and account changes. This is a design decision, not a model capability. The system architect decides what gets loaded into context, because fitting everything is not an option.
The customer's emotional state matters here too. The tone of the message — three problems, a deadline, implied frustration — is something the system should register and carry forward. If the customer escalates, the system should not reset to a neutral tone. Conversation memory preserves that signal, and the system prompt can instruct the model to acknowledge frustration without being defensive. But the system has to supply the conversational context that makes that instruction actionable.
Where the System Must Stop and Ask a Human
Not every action should be automated, and not every situation has a clear resolution path. The approval boundaries from Post 0-4 are not theoretical in a customer support system. They are operational.
The system should escalate to a human agent when:
The action has financial consequences the system cannot fully verify (processing a refund, modifying a subscription)
The customer's situation is ambiguous and the available data does not resolve it (the entitlement check returns inconsistent results)
The customer explicitly asks for a human
The system's confidence in its classification or resolution falls below a threshold
For the Relay scenario, the downgrade is the clear escalation case. The system has described the situation and recommended the action. A human agent reviews, confirms the customer's intent, and processes the change. The customer experiences a brief handoff — "I've prepared your downgrade request. A team member will confirm and process it before your Friday renewal" — not an indefinite wait.
This boundary is not a failure of the system. It is a design feature. The system handled two of three issues autonomously and prepared the third for efficient human resolution. The human agent who picks up this ticket does not start from scratch. They see the system's classification, the billing evidence, the entitlement check, the recommended action. Their job is to verify and execute, not to re-diagnose.
Research supports this pattern. Studies on AI-assisted customer support consistently find that hybrid systems — where AI handles routine resolution and prepares complex cases for human agents — outperform both fully automated and fully manual approaches. The key is not maximizing automation. It is placing the automation boundary in the right place.
What the Customer Actually Experiences
Step back from the architecture and consider the customer's perspective.
They sent one frustrated message with three urgent problems. Within seconds, the system responds:
"I found a duplicate charge of $49 on your Team plan on March 3rd. Under Relay's refund policy, duplicate charges are eligible for automatic refund. I've flagged this for processing, and the refund should appear on your statement within 5-7 business days. Regarding the Gantt chart feature: your current Team plan does not include Gantt charts, which are available on the Business plan. I checked for any known access issues and did not find an active incident. If you believe you previously had access, I can flag this for our team to investigate further. For your downgrade request: your Team plan renews on Friday, March 22. A downgrade to the Individual plan would reduce your monthly charge from $49 to $19. I've prepared this change and a team member will confirm and process it before your renewal date."
Three problems, three responses, each handled at the appropriate level of autonomy. The billing issue is resolved with evidence. The access issue is explained with a clear reason and an offer to escalate. The downgrade is described, recommended, and queued for human confirmation.
The customer does not see the architecture. They see a fast, accurate, honest response that treats their problems as distinct and handles each one appropriately. That is the product of system design, not of a better chatbot.
Why This Is a System, Not a Chatbot
Every concept from the previous four posts is present in this example, and none of them work in isolation.
Generation (Post 0-1) drafts the response in natural language. But without grounding (Post 0-3), it hallucinates a refund policy. Without tool use (Post 0-4), it cannot check the customer's actual plan. Without chain-of-thought (Post 0-2), it merges three problems into one. Without memory (Post 0-4), it loses track of which issues are resolved. Without approval boundaries (Post 0-4), it either does too much (processing a downgrade it should not) or too little (refusing to describe the situation). Without careful context management (Post 0-2), it either stuffs the context window with irrelevant ticket history or drops the customer's earlier statements.
The system is not intelligent because any single component is sophisticated. It is effective because the components are composed. Retrieval supplies evidence. Tools supply data. The model supplies language. Prompts supply structure. Memory supplies continuity. Approval boundaries supply safety. The result is a product that handles a three-problem message with three appropriate responses — not because the language model is smarter, but because the system around it is designed.
This is the compound system idea that Post 1 of the main series will formalize. Capability is a property of the composition, not just of the model.
What This Post Is Not
This post is not a tutorial on building a customer support system. It does not specify message queues, webhook architectures, or database schemas. It does not recommend specific vendor platforms or APIs.
This post is also not an argument that AI should replace human support agents. The example above ends with a human confirming the downgrade. That handoff is intentional. The system handles what it can handle well and prepares what it cannot for efficient human action.
The purpose is narrower: to show that the concepts you learned across Posts 0-1 through 0-4 are not academic. They are the building blocks of a real product. If you can see how generation, grounding, retrieval, tool use, memory, and approval boundaries converge in a customer support system, you can recognize the same patterns in other applications.
Where the Series Goes Next
Over these five posts, you have learned what large language models do and why they hallucinate. You have seen how prompts, context windows, and step-by-step reasoning shape model behavior. You have understood why models need grounding — retrieval, embeddings, and external knowledge — to produce reliable answers. You have explored the autonomy spectrum, from simple assistants through workflows to bounded agents with tool use, memory, and approval boundaries. And in this post, you have seen all of those concepts converge inside a single product.
Along the way, you planned a trip to Helsinki, researched real estate in Austin, and diagnosed a customer support ticket for a SaaS product. Each example introduced concepts that build on the ones before.
Now the series shifts gears.
The next ten posts go deeper — into compound AI system architecture, production-grade pipelines, advanced retrieval, agent loop mechanics, document intelligence, and multimodal evidence handling. The running example changes too: an AI copilot for OptiVerse Travel, a mid-size travel agency planning a complex accessible trip to Japan. You planned a personal trip to Helsinki in Level 0 — now you will see what it takes to build the system that does this professionally, at scale, with real constraints.
You do not need to start from scratch. You need what you already have: a working vocabulary for how AI systems are built.
Here is your toolkit so far:
# — Concept — First appeared — One-line summary
1 — Generation — Post 0-1 — Language models produce text via probabilistic prediction — fluency does not equal correctness
2 — Hallucination — Post 0-1 — The model confidently outputs factually incorrect content — an inherent risk of probabilistic generation
3 — Prompt engineering — Post 0-2 — Structuring inputs to guide model behavior — the first lever for output quality
4 — Context window — Post 0-2 — The model's working memory ceiling — information beyond it is silently lost
5 — Chain-of-thought — Post 0-2 — Step-by-step reasoning that decomposes complex problems to improve accuracy
6 — Grounding — Post 0-3 — Anchoring model output to verifiable external data instead of training-data memory
7 — Retrieval — Post 0-3 — Fetching relevant information from external knowledge sources before generation
8 — Embeddings — Post 0-3 — Numerical representations of text where similar meanings produce similar numbers
9 — Tool use — Post 0-4 — The model's ability to decide when to call an external API and format the request
10 — Memory — Post 0-4 — Conversation memory, task state, durable knowledge — three information layers with different lifetimes
11 — Autonomy spectrum — Post 0-4 — Five levels describing how much control the system has over its own execution
12 — Approval boundary — Post 0-4 — Describe, recommend, act — where the system may proceed and where humans must approve
13 — Compound system — Post 0-5 — Capability comes from composing components, not from a single model call
These thirteen concepts are not checklist items — they are your toolkit for the main series. Every subsequent post will draw on several of them in deeper, more specific technical contexts.
Sources and Further Reading
Zaharia, M., Khattab, O., Chen, L., et al. (2024). "The Shift from Models to Compound AI Systems." *Berkeley AI Research Blog.* Introduces the compound AI systems framework -- the architectural perspective that capability comes from composing multiple components, not from a single model call. This framing underpins the distinction between chatbot and system made throughout this post. bair.berkeley.edu/blog/2024/02/18/compound-ai-systems
Xu, A., Liu, Z., Guo, Y., et al. (2017). "A New Chatbot for Customer Service on Social Media." *Proceedings of the 2017 CHI Conference on Human Factors in Computing.* An early empirical study of AI chatbots in customer service, demonstrating the gap between user expectations and chatbot capabilities, and establishing patterns for intent classification and handoff to human agents. research.ibm.com/publications/a-new-chatbot-for-customer-service-on-social-media
Brynjolfsson, E., Li, D., and Raymond, L. (2023). "Generative AI at Work." *National Bureau of Economic Research, Working Paper 31161.* Studies the deployment of a generative AI assistant for customer support agents, finding significant productivity gains for less-experienced agents and improved customer sentiment. Demonstrates the hybrid human-AI pattern described in this post. nber.org/papers/w31161
Gangadharaiah, R. and Narayanaswamy, B. (2019). "Joint Multiple Intent Detection and Slot Labeling for Goal-Oriented Dialog." *Proceedings of NAACL-HLT 2019*, pages 564-569. Shows why single-intent assumptions are weak for real-world dialog and proposes an attention-based model for jointly detecting multiple intents and labeling slots within a single message -- the classification challenge underlying the multi-issue triage described in this post. aclanthology.org/N19-1055
Zendesk. (2024). "CX Trends 2024: Unlock the Power of Intelligent CX." *Zendesk Global Research Report.* Industry survey data on AI adoption in customer support and operational patterns around automation, routing, and escalation. zendesk.com/newsroom/articles/cx-trends-2024
Tags
Huang Tzu Lin
With over five years in autonomous robotics, there's a strong passion for incorporating cutting-edge technologies and innovative approaches. Dedicated to transforming the latest research and insights into practical applications, this journey pushes the limits of possibility.
Related Posts
Stay Updated
Get the latest technical insights delivered to your inbox.