What Large Language Models Actually Do
Reading order
LLM Foundations
Previous chapter
No adjacent chapter
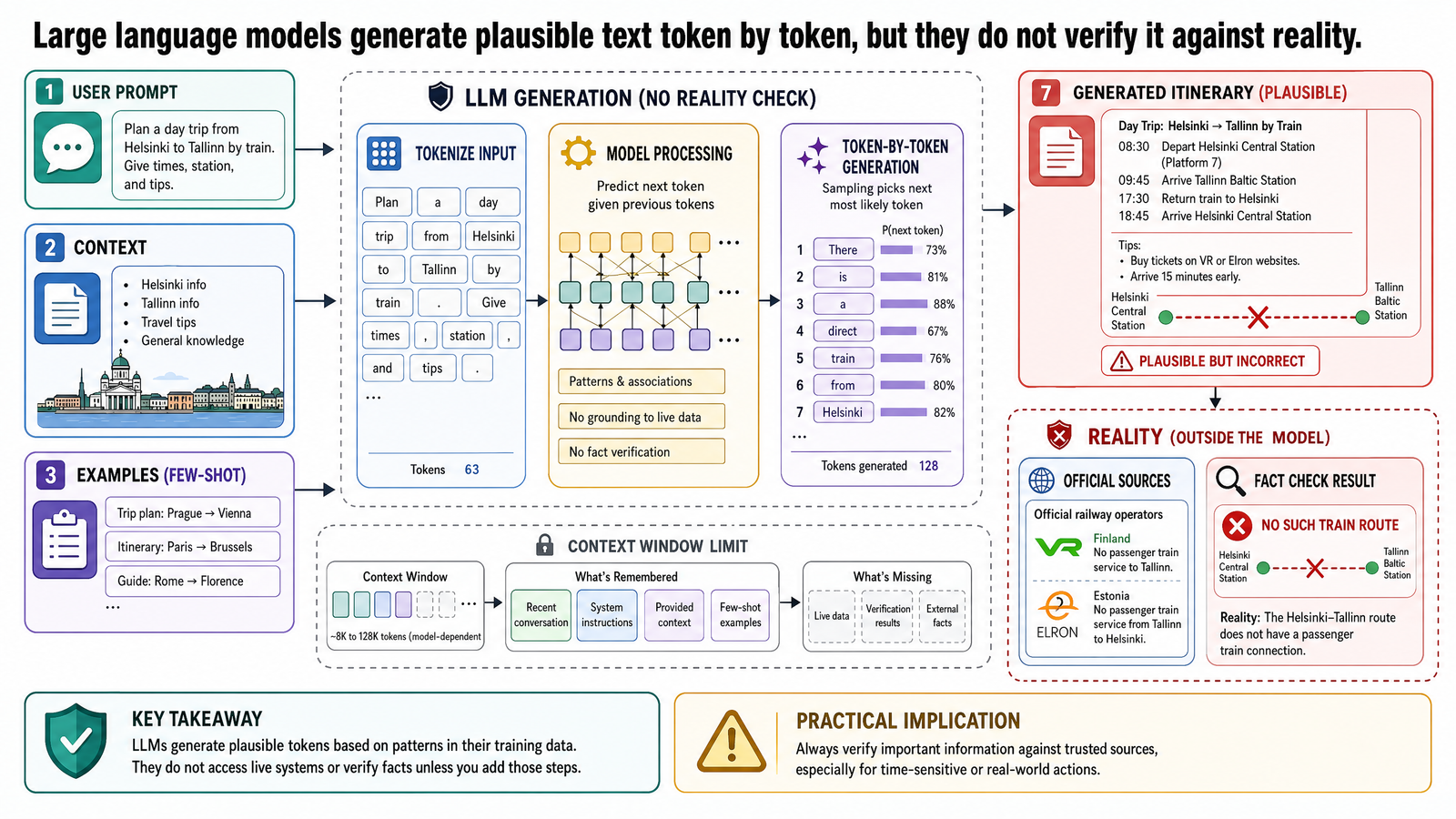
Table of Contents
- The Impressive Output
- The Cracks
- What a Neural Network Is (Conceptual)
- What "Training" Means
- What "Parameters" Are
- What a "Token" Is
- What "Inference" Means
- What "Generative" Means
- Why It Hallucinates
- The Training Cutoff Problem
- Putting the Vocabulary Together
- What This Means Practically
- Common Misconceptions
- Misconception: The model "knows" things
- Misconception: The model "understands" your question
- Misconception: Errors mean the model is "bad"
- Misconception: Bigger models do not hallucinate
- What This Post Is Not
- Where This Goes Next
- Sources and Further Reading
You type a sentence into an AI application. Seconds later, it returns several paragraphs of fluent, well-organized text that reads like it was written by a knowledgeable human. That experience is now routine. What is not routine — and what matters if you plan to build anything on top of these systems — is understanding what actually happened between your input and that output.
This post explains the core mechanics of large language models using a single running example. The goal is not to impress you with what the technology can do. The goal is to give you an accurate mental model of how it works, so that its strengths and failures stop feeling surprising.

The Impressive Output
Consider this prompt, typed into a general-purpose AI assistant:
"Plan a trip to Helsinki."
The model returns a detailed itinerary. Day one: arrive, check into your hotel in Kluuvi, walk to Senate Square and Helsinki Cathedral. Lunch at Ravintola Sea Horse for classic Finnish fare. Day two: take the ferry to Suomenlinna fortress, explore the island, return for an evening sauna at Löyly. Day three: a day trip to Porvoo — take the VR train from Helsinki Central Station, about one hour, explore the Old Town with its red wooden shore houses and medieval cathedral. Day four: visit Hakaniemi Market Hall and the Design District. And so on, complete with restaurant names, transit directions, and timing suggestions.
The output is fluent. It is well-structured. It sounds authoritative. If you have never been to Helsinki, it looks like expert advice.
The Cracks
Now check the details.
The model suggests taking a VR train from Helsinki Central Station to Porvoo. There is no such train. No direct rail service to Porvoo exists — the only practical option is a bus from Kamppi Bus Station, about 55 minutes. The model also promises you will "experience the midnight sun" during a late-June visit. Helsinki is at 60.2°N — below the Arctic Circle. It gets roughly 19 hours of daylight in midsummer, but the sun does set; true midnight sun only occurs in Lapland, above 66.5°N. And the itinerary recommends an evening of northern lights viewing in October. Aurora is rare in Helsinki, requiring strong geomagnetic storms (Kp 4+); reliable sightings require traveling north to Lapland.
These errors are based on documented patterns in LLM outputs about Finland. Some surrounding details have been simplified for clarity, but the factual mistakes are real and verifiable.
None of these errors are random. They follow a pattern. The model produced text that is statistically consistent with what a Helsinki travel guide should sound like, but it did not verify any of its claims against current reality. Understanding why requires understanding what a large language model actually is.
What a Neural Network Is (Conceptual)
A large language model is built on a type of software system called a neural network. For this post, the important thing about a neural network is not its internal math. It is what the system does: it learns patterns from data.
Think of the model as a system that read every travel blog, restaurant review, city guide, forum post, and Wikipedia article about Helsinki that existed in its training data — millions of documents. It absorbed the patterns in that text: what words tend to appear near other words, what sentence structures follow what kinds of questions, what a "5-day itinerary" typically looks like. It learned that "traditional Finnish dining" is frequently followed by certain types of restaurant names, Finnish culinary terms, and neighborhood references.
But it never visited Helsinki. It has no sensory experience, no memory of meals eaten, no ability to check a bus timetable or verify that a train route exists. It is a system that learned the statistical shape of text about Helsinki, not the city itself.
What "Training" Means
The process by which a model learns these patterns is called training. During training, the model is exposed to enormous quantities of text and adjusts its internal structure to become better at a specific task: predicting what text comes next.
Training data for large language models typically includes broad swaths of the internet (web crawls such as Common Crawl), digitized books, Wikipedia, academic papers, public code repositories, news articles, and forum discussions. The exact composition varies by model and is often not fully disclosed. What matters here is the scale — hundreds of billions to trillions of words — and the consequence: the model's entire knowledge comes from this text, frozen at the time training ended.
This is the training cutoff. If a restaurant closed six months after the training data was collected, the model has no way to know from its weights alone. A product can attach retrieval, browsing, or database tools around the model, but the base generation step is still working from patterns learned during training unless the surrounding system supplies fresh evidence.
What "Parameters" Are
During training, the model adjusts billions of internal numerical values to encode the patterns it learns. These values are called parameters — specifically, they are the learned weights of the neural network.
Parameters are not a database of facts. They do not store "Restaurant X is located at address Y" as a discrete record. Instead, they encode compressed statistical relationships: the patterns of which words, phrases, and structures tend to co-occur across the training data. When the model later produces text about Helsinki restaurants or train routes, it is reconstructing plausible-sounding text from these compressed patterns, not retrieving entries from a lookup table.
The scale of modern models is substantial, ranging from billions of parameters to hundreds of billions, with some mixture-of-experts architectures reporting still larger total parameter counts while activating only a fraction per token. Exact figures for many commercial models -- including GPT-4, Claude, and Gemini -- are not fully public. The important point is not the specific number. It is that larger models can often encode more nuanced patterns, at the cost of more computation, memory, and training data.
What a "Token" Is
Language models do not read and write individual characters or whole sentences. They operate on intermediate chunks called tokens.
A token is a piece of text that the model treats as a single unit. Common short words are often one token each. Longer or less common words get split into multiple tokens. Punctuation marks and spaces are also tokens. The exact tokenization depends on the model's tokenizer — a preprocessing step that converts raw text into the sequence of tokens the model actually processes.
For a rough sense of scale: "Helsinki" is one or two tokens depending on the tokenizer. "5-day itinerary" is roughly three to four tokens. A sentence like "Take the VR train from Helsinki Central Station to Porvoo" might be around ten to twelve tokens, depending on the specific tokenizer.
This matters because the model reads your input as a sequence of tokens and produces its output one token at a time. Everything the model does — from understanding your question to generating its answer — happens in this token-by-token framework.
What "Inference" Means
Training happens once (or periodically, when a model is updated). After training, the model's parameters are fixed. When you type a prompt and the model generates a response, that process is called inference. Inference is the act of running the trained model on new input. The model is not learning anything new during inference. It is applying the patterns it already learned during training to produce an output for your specific input.
This distinction matters because it clarifies a common confusion. When you interact with an AI assistant, you are not training it. Your prompts and its responses do not change the model's parameters. The model that answered your Helsinki query is the same model, with the same parameters, that answers the next user's question about something entirely different.
What "Generative" Means
The model produces the Helsinki itinerary through a process called generation, which is why these systems are called generative models. Generation works by next-token prediction: the model looks at all the tokens so far (your prompt, plus any tokens it has already generated) and predicts a probability distribution over what the next token should be. It selects a token from that distribution, appends it to the sequence, and repeats.
This is the core mechanism. The entire itinerary — every restaurant name, every transit direction, every day-by-day heading — was produced one token at a time, each token chosen based on the statistical patterns encoded in the model's parameters given everything that preceded it.
Next-token prediction is the foundation described in the original transformer architecture paper ("Attention Is All You Need," Vaswani et al., 2017) and refined through subsequent work on generative pre-trained models. The acronym GPT itself stands for Generative Pre-trained Transformer, naming this process directly: a model that is generative (produces text), pre-trained (learned its parameters before you use it), and built on the transformer architecture.
Understanding generation as next-token prediction explains a great deal about both the model's strengths and its failure modes.
Why It Hallucinates
Return to the Helsinki itinerary. The model wrote "take the VR train from Helsinki Central Station to Porvoo" as day-trip instructions. Why?
Because given the preceding context — a paragraph about a Helsinki day trip — a sequence like "take the VR train from Helsinki Central Station" is statistically plausible. The model has seen thousands of texts mentioning Finnish rail travel. It has learned that VR (Finland's national railway) operates trains from Helsinki Central Station, and that Porvoo is a popular day-trip destination. Each individual fact is correct. But the model assembled them into a route that does not exist: there is no direct train to Porvoo.
It did not check whether this route exists. It cannot. It has no mechanism for verification. It has no access to VR's route database, no connection to a journey planner, no way to confirm that a rail service actually operates between two stations. It predicted the next tokens based on learned patterns, and those tokens formed a transit instruction that sounds right but is wrong.
This failure mode is called hallucination: the model generates text that is fluent and confident but factually incorrect. The term is worth understanding precisely. The model is not lying — lying implies intent and knowledge of the truth. The model is not guessing randomly — the output is shaped by real statistical patterns. It is doing exactly what it was trained to do: predicting likely next tokens. The problem is that "statistically likely text" and "factually accurate text" are not the same thing.
Hallucination is not a bug in the sense of a software defect to be patched. It is a direct consequence of the model's fundamental mechanism. A system that generates text by predicting probable continuations will sometimes produce text that is probable but false. This is especially likely for specific factual claims — proper nouns, dates, schedules, addresses — where the model's compressed statistical patterns do not preserve the precision that accuracy requires.
The Training Cutoff Problem
The midnight sun claim reveals a related but distinct problem. The model's training data contains countless texts about "Finland and the midnight sun." That association is strong enough that the model reproduces it confidently — but it does not encode the geographic precision to know that midnight sun requires latitude above the Arctic Circle, not just "Finland." Even if the training data contained that distinction, compressed statistical patterns do not preserve it reliably. The model's knowledge is frozen at its training cutoff, and any fact that changed after that date — a restaurant closing, a transit route revision, a landmark being renovated — is invisible to the model.
This is not a limitation that improves with scale. A model with ten times more parameters still cannot know about events that occurred after its training data was collected. The training cutoff is a structural boundary, not a performance one.
Putting the Vocabulary Together
At this point, the core terms are defined and connected. Here is how they relate through the Helsinki example:
A neural network learned patterns from text during training, producing billions of parameters — learned weights that encode compressed statistical relationships. When you submit a prompt, the system performs inference: it processes your input as a sequence of tokens and generates a response through next-token prediction, selecting each token based on the statistical patterns in its parameters. When those patterns produce text that sounds right but is factually wrong, the result is a hallucination. When the facts have changed since the training data was collected, the model is limited by its training cutoff.
Every term names one piece of the same underlying process. There is no separate "knowledge retrieval" step, no "fact verification" module, no "confidence assessment" in the base model. There is a text-prediction engine producing statistically likely continuations, one token at a time.
What This Means Practically
The Helsinki itinerary demonstrates both sides of this technology clearly.
What the model is good at. It produced a well-structured, fluent travel plan in seconds. The overall format is sensible. The general knowledge — that Suomenlinna is worth visiting, that Porvoo is a popular day trip, that Finnish sauna culture is central to the experience — is accurate, because those facts are so thoroughly represented in the training data that the statistical patterns reliably reproduce them. The model is excellent at synthesis, structure, and producing text that follows the conventions of a genre.
What the model is unreliable at. Specific factual claims — especially transit routes, geographic precision, current business information, and anything that requires distinguishing between related but distinct facts — are exactly where next-token prediction breaks down. The model has no mechanism to distinguish between a pattern that happens to correspond to a current fact and a pattern that produces a plausible-sounding fiction.
For anyone building on top of these systems, this distinction is operational, not theoretical. It tells you where you can trust the model's output and where you need additional mechanisms — verification, retrieval from current data sources, human review — to make the output reliable.
Common Misconceptions
Several misunderstandings about language models follow from not grasping the next-token prediction mechanism.
Misconception: The model "knows" things
The model does not store knowledge in the way a database does. It encodes statistical patterns that can reproduce text resembling knowledge. For well-attested facts (the capital of Finland is Helsinki), the pattern is strong enough that the output is reliably correct. For less common or recently changed facts, the pattern may produce something that merely sounds correct.
Misconception: The model "understands" your question
The model processes your input as a token sequence and generates a statistically likely continuation. Whether that constitutes "understanding" is a philosophical question this post does not need to settle. What matters practically is that the model can fail in ways that no system with genuine comprehension would — such as confidently recommending a train route that does not exist, in direct response to a request for reliable recommendations.
Misconception: Errors mean the model is "bad"
Hallucination is not evidence that a model is poorly made. It is a predictable consequence of the generation mechanism. A model that never hallucinated would need to have either perfect factual knowledge (impossible given finite training data and a training cutoff) or a reliable internal mechanism for distinguishing fact from plausible fiction (which next-token prediction alone does not provide). Recognizing this shifts the conversation from "the model made a mistake" to "this task requires more than a model alone."
Misconception: Bigger models do not hallucinate
Larger models with more parameters tend to hallucinate less on well-attested facts, because they encode patterns at higher fidelity. But they still hallucinate, particularly on specific claims, recent events, and domains underrepresented in training data. Scale reduces the frequency of some errors. It does not eliminate the structural cause.
What This Post Is Not
This post does not cover how to mitigate hallucination or make language model outputs more reliable. Those are system-design questions — involving retrieval, grounding, validation, and human oversight — and they belong in later posts in this series.
This post does not explain the internal mathematics of transformer models. The attention mechanism, positional encoding, and layer architecture are important engineering topics, but they are not necessary to understand what a language model does at the level this post addresses.
This post does not discuss agents, tools, or multi-step AI systems. Those concepts build on the foundation established here, but they are separate architectural ideas.
Where This Goes Next
The model produced a detailed Helsinki itinerary from a single sentence. The output was impressive in structure but unreliable in specifics. That gap — between fluent generation and factual accuracy — is the central design challenge for anyone building applications on top of language models.
The next question is what happens on the input side. The model produced this itinerary from a single sentence. What happens when you give it better instructions, more context, or ask it to think step by step? That is the subject of Post 0-2.
Beyond the application layer. This series continues with Post 00-2, building toward system design. If you're also curious about what happens inside the inference engine when your API call reaches the GPU, the Infrastructure Track branches from Post 00-2 into serving architecture.
Sources and Further Reading
Vaswani, A., Shazeer, N., Parmar, N., et al. (2017). "Attention Is All You Need." *Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS).* The foundational paper introducing the transformer architecture that underlies modern large language models. arXiv:1706.03762
Radford, A., Narasimhan, K., Salimans, T., and Sutskever, I. (2018). "Improving Language Understanding by Generative Pre-Training." *OpenAI.* The original GPT paper establishing the generative pre-training approach to language models. OpenAI Research
Bender, E. M., Gebru, T., McMillan-Major, A., and Shmitchell, S. (2021). "On the Dangers of Stochastic Parrots: Can Language Models Be Too Big?" *Proceedings of FAccT 2021.* A critical examination of risks in large language models, including discussion of training data composition and the distinction between fluency and understanding.
Ji, Z., Lee, N., Frieske, R., et al. (2023). "Survey of Hallucination in Natural Language Generation." *ACM Computing Surveys, 55(12).* A comprehensive survey of hallucination in language models, covering taxonomy, causes, and mitigation approaches. DOI:10.1145/3571730
Shanahan, M. (2024). "Talking About Large Language Models." *Communications of the ACM, 67(2).* A careful philosophical and technical analysis of what language models do and do not do, clarifying common anthropomorphic misattributions. arXiv:2212.03551
Huang Tzu Lin
With over five years in autonomous robotics, there's a strong passion for incorporating cutting-edge technologies and innovative approaches. Dedicated to transforming the latest research and insights into practical applications, this journey pushes the limits of possibility.
Related Posts
Stay Updated
Get the latest technical insights delivered to your inbox.