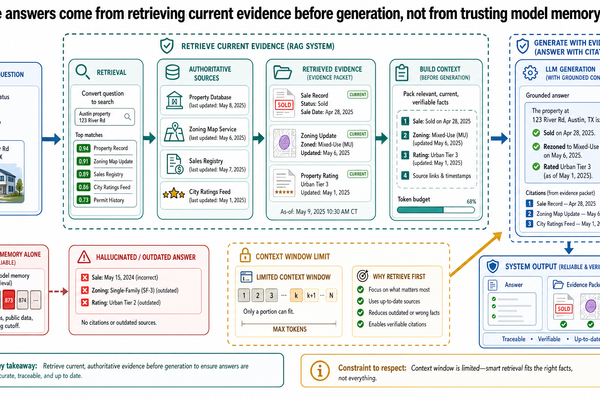
為什麼 LLM 需要幫助 — 幻覺、Grounding,以及系統設計的必要性
大型語言模型能產出流暢又自信的文字。而這份自信,正是問題所在。模型可以把一筆已經下架的房源、一個上一季才變動的稅率、一則三年前的學校評分,講得頭頭是道。它沒有任何機制去查核——本來就不是為查核設計的。它的工作是根據訓練資料預測下一個最合理的 token,而合理不等於正確。
Huang Tzu Lin
4 posts
大型語言模型能產出流暢又自信的文字。而這份自信,正是問題所在。模型可以把一筆已經下架的房源、一個上一季才變動的稅率、一則三年前的學校評分,講得頭頭是道。它沒有任何機制去查核——本來就不是為查核設計的。它的工作是根據訓練資料預測下一個最合理的 token,而合理不等於正確。
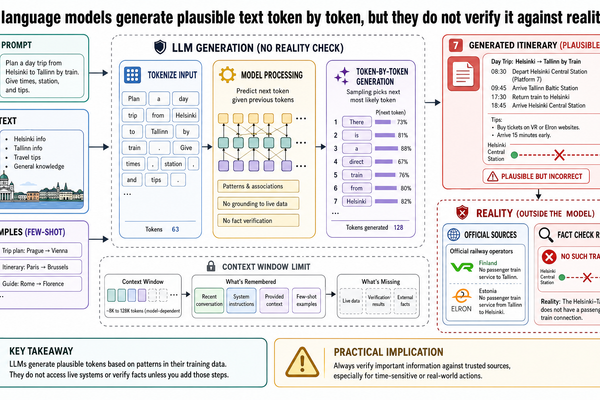
你在某個 AI 應用裡打了一段話,幾秒鐘後螢幕上跑出好幾段文字——流暢、有條理,讀起來像某個很懂的人寫的。這種事現在大家都習以為常了。但如果你打算在這些系統上面蓋東西,真正該理解的是:從你按下送出到那些文字出現,中間到底發生了什麼。
Large language models produce fluent, confident text. That confidence is the problem. A model can sound authoritative about a property listing that no longer exists, a tax rate that changed last quarter, or a school rating from three years ago. It has no mechanism to check. It was not designed to...
You type a sentence into an AI application. Seconds later, it returns several paragraphs of fluent, well-organized text that reads like it was written by a knowledgeable human. That experience is now routine. What is not routine — and what matters if you plan to build anything on top of these sys...