為什麼 LLM 需要幫助 — 幻覺、Grounding,以及系統設計的必要性
閱讀順序
LLM Foundations
大型語言模型能產出流暢又自信的文字。而這份自信,正是問題所在。模型可以把一筆已經下架的房源、一個上一季才變動的稅率、一則三年前的學校評分,講得頭頭是道。它沒有任何機制去查核——本來就不是為查核設計的。它的工作是根據訓練資料預測下一個最合理的 token,而合理不等於正確。
這篇要講的是:這個落差為什麼存在、在實務上代表什麼,以及為什麼可靠的 AI 需要圍繞模型建系統,而不是期待模型本身就可靠。
自信卻錯誤的答案
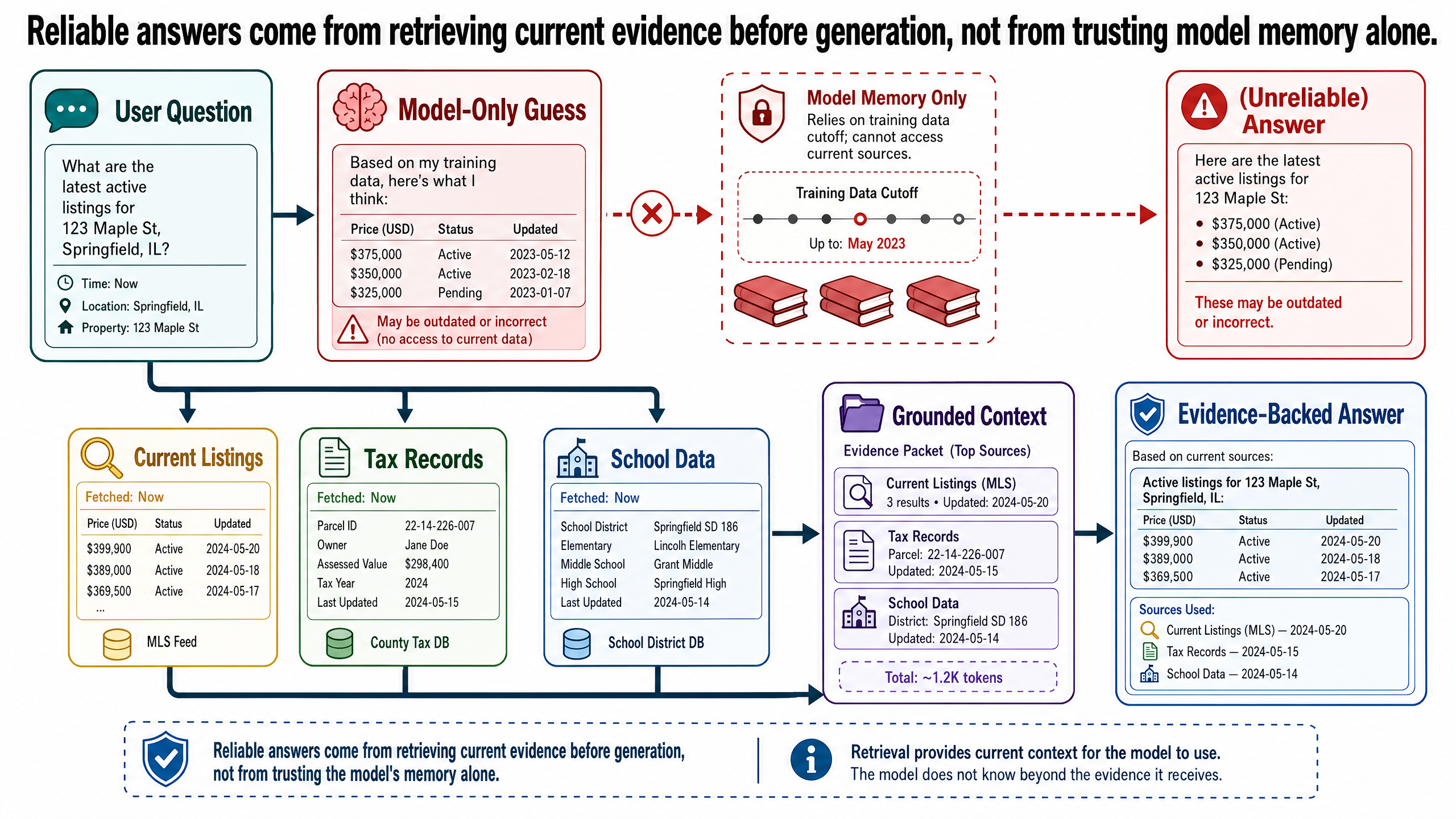
一位奧斯汀(Austin)的首購族問 AI 助理:
幫我在奧斯汀找三間兩房、低於 40 萬美元、附近有好學校的公寓。
助理回了三筆房源,每筆都附上地址、價格、學校評分、社區資訊,還有估算的每月房屋稅。結構清楚、細節具體,看起來就像經驗老到的房仲寫的。
但實際上呢:
第一筆房源八個月前就賣掉了,早就不在市場上。
第二筆房源引用的學校評分是 8/10,但那是 2022 年的資料,現在是 6。
第三筆房源把那個社區描述成單一住宅區,但分區規劃已經在 2024 年改成混合使用區了。
三筆的房屋稅估算用的稅率,跟那個郡目前公佈的不一樣。
這些錯誤都不是隨機的。每一個都是從訓練資料裡拉出來的、在某個時間點確實正確的合理細節。那位買家差一點就拿這些資訊去做財務決策了。這就是自信卻缺乏 grounding 的回答,在實務上的真正代價。
為什麼會發生這種事
直覺反應是把這些當品質問題——模型訓練好一點,提示詞寫仔細一點,或許就對了。但這個直覺是錯的。問題是結構性的。
回想前幾篇的內容:LLM 是根據訓練時學到的模式來預測文字。模型的參數編碼了訓練語料中的統計關係。你問奧斯汀的公寓,模型不會去搜資料庫——它生成的是跟訓練資料中奧斯汀公寓房源「在統計上長得像」的文字。
這代表三件事:
模型拿不到當前的事實。 它的知識是一張快照。訓練資料有截止日期,之後發生的事——房源賣掉了、稅率改了、區域重新劃分了——模型全看不到。
模型沒有驗證機制。 它沒辦法查 #4821 號房源還在不在市場上,也沒辦法去查郡級記錄。它只會產出內容,不會驗證內容。
模型不知道自己在編東西。 對它來說,生成一個事實陳述和生成一個聽起來合理的陳述,完全沒有差別。兩者都只是在它學到的機率分布下得分高的 token 序列。在 AI 領域,這叫幻覺(hallucination):模型產出了聽起來對、但實際上沒有任何可驗證來源作為依據的內容。
幻覺不是下一版模型就能修好的 bug,它是語言模型生成文字方式的結構性屬性。更好的模型在訓練資料大量涵蓋的主題上確實比較少幻覺,但任何基於下一 token 預測的架構都沒辦法保證事實準確——因為事實準確需要存取模型根本沒有的外部真實資料。
研究 LLM 幻覺率的文獻一致發現,就算最先進的模型,碰到特定事實、數字或近期事件的問題,還是會以不低的比率產出捏造的東西。Huang et al. (2023) 的綜述調查了幾十個模型的幻覺類型,發現事實捏造仍然是一個跟模型規模無關的持續性挑戰 (Huang et al., "A Survey on Hallucination in Large Language Models," arXiv:2311.05232)。
三種失敗型態
奧斯汀的案例展示了三類不同的失敗,各有不同的根因。
過時的知識
已售的房源和過期的學校評分,屬於時效性的失敗。訓練資料在某個時間點確實包含這些事實,但現實已經變了。房市、學校評分、稅率、分區——這些東西常常在變。就算是才六個月前訓練的模型,碰到事實頻繁變動的領域照樣會有過時的資訊。
光靠更多訓練解決不了。重新訓練一個大模型又貴又慢,就算每週重新訓練,模型的知識跟現實之間永遠會有落差。
私有與受控資料
房仲用的 MLS(Multiple Listing Service)資料庫不是公開訓練資料。郡級稅務記錄雖然技術上是公開的,但通常藏在沒有被收進訓練集的入口網站後面。學校評分資料庫由特定組織維護,有自己的更新節奏。
就算模型的訓練資料完全是最新的,它還是碰不到這些私有或受控的資料來源。資訊存在,但不在模型的參數裡。
缺乏來源標註
模型說「這個郵遞區號的平均房價是 385,000 美元」。可能對,可能不對。但就算碰巧正確,光看模型的輸出也沒辦法驗證。沒有引用、沒有時間戳、沒有來源連結。使用者除了模型的自信程度外沒有任何判斷依據——偏偏模型不管對不對都一樣自信。
缺乏來源標註不只是不方便。涉及財務、法律、健康決策的場景,沒有來源的陳述在實務上根本用不了。房仲不能跟客戶說「AI 說的」來當 40 萬美元買房的依據。
什麼是 Grounding
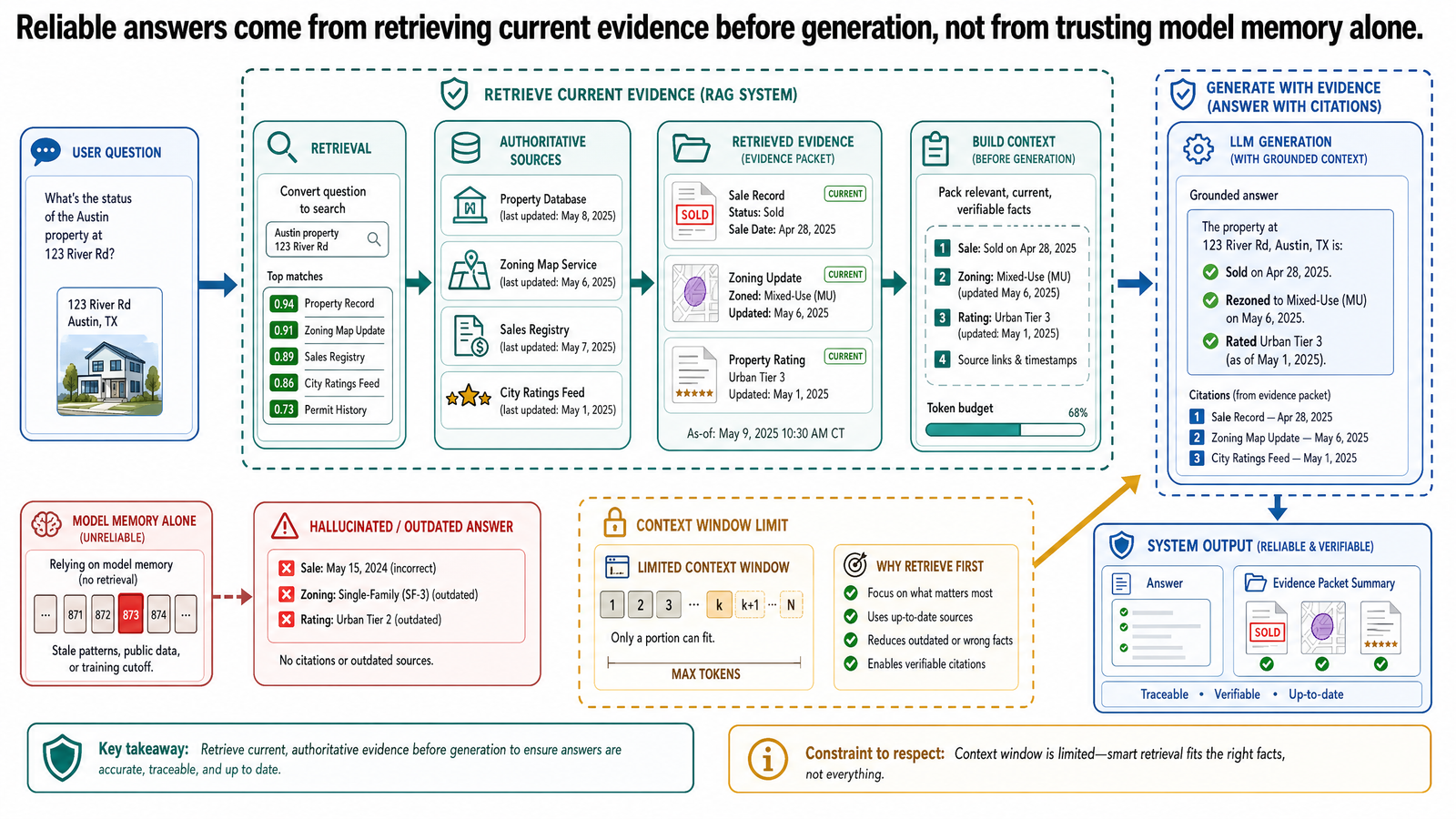
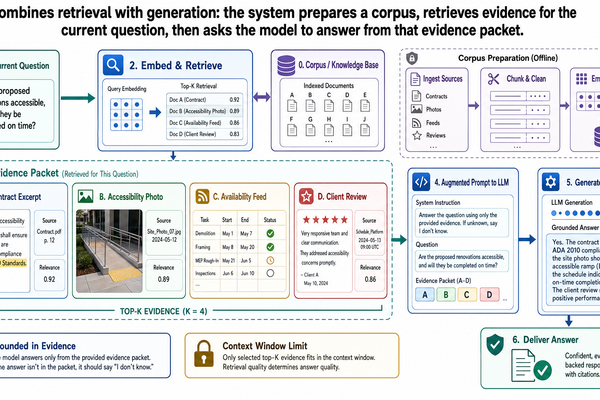
這三個問題的解法有一個名字:grounding——在生成回答之前,先把模型的輸出連到可驗證的外部資訊。
與其讓模型去回憶它「知道」的奧斯汀公寓,一個做了 grounding 的系統會這樣:
去 MLS 資料庫查當前房源。
去核對郡級稅務評估人員公佈的稅率。
從評分機構的資料庫抓當前的學校評分。
把這些驗證過的資訊連同使用者的問題一起提供給模型。
模型根據檢索到的事實來生成回應,而不是根據訓練資料。
原則很簡單:先查來源,再作答。 別靠模型對訓練資料裡公寓房源的記憶,去拿實際資料,然後交給模型當上下文。
Grounding 不會消除幻覺。模型還是可能誤解檢索到的資訊、忽略部分內容,或把東西拼錯。但 grounding 大幅降低了捏造事實的風險,因為模型是拿真實資料在運作,不是從訓練裡重建近似的模式。這個轉變,是從「憑記憶生成」變成「憑證據生成」。
檢索在最簡層級如何運作
檢索(retrieval)是讓 grounding 跑起來的機制。最簡單的形式下,檢索是三個步驟:
搜尋知識來源,找跟使用者問題相關的資訊。
選取最相關的結果。
傳遞這些結果連同原始問題給模型,讓它根據實際證據來生成回答。
用房地產的例子來說,檢索可能是:在 MLS 資料庫查奧斯汀低於 40 萬的兩房公寓、拿到最相關的結果,然後把這些房源資料放入給模型的提示中。模型接著用真實的房源資料來寫回應,不是憑空生成。
這個模式在 Lewis et al. 2020 年的論文 "Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks" 裡被正式提出。論文證明把檢索步驟跟語言模型結合,在知識密集型問題上的準確度顯著優於單用模型 (Lewis et al., 2020, arXiv:2005.11401)。這個方法現在被廣泛叫做檢索增強生成(RAG, Retrieval-Augmented Generation)。
基本的 RAG 設定裡,給模型的提示包含三部分:
一個指令,告訴模型根據提供的資訊來回答。
檢索到的內容——從知識來源拿到的實際資料。
使用者的問題。
模型看到驗證過的資訊跟問題擺在一起,然後基於那些資訊生成回應。這跟裸模型呼叫有根本性的不同——裸模型除了自己的參數之外什麼都沒有。
Embedding — 文字變數字,相似度變距離
檢索需要一種方法來判斷哪些文件或記錄跟問題相關。關鍵字匹配在簡單情境下夠用,但很快就不夠了。看個例子:
一位買家搜「適合家庭、交通便利的社區」。
一筆房源的描述寫著:「靠近輕軌站的寧靜住宅區,步行範圍內有多座公園和小學。」
這兩段文字明顯在講同一種地方,但幾乎沒有共同的關鍵字。「適合家庭」沒有出現在房源描述裡,「交通」也沒有。用關鍵字搜的話,會完全錯過這筆匹配。
這就是 embedding 登場的地方。背後的直覺很簡單,雖然數學比較複雜。
這樣想:假設你可以把每個句子放到一張地圖上。意思接近的句子靠在一起,意思不同的離得遠。在這張地圖上,「適合家庭、交通便利的社區」跟「靠近輕軌、有公園和學校的寧靜住宅區」會是鄰居,就算用的字完全不一樣。而「無住宅分區的工業倉儲區」就會在地圖上離很遠。
Embedding 就是一個句子在這張地圖上的地址。技術上來說,它是一串數字——通常幾百到幾千個——代表文字的語意。建立 embedding 的過程用一種叫 embedding 模型的專門模型,把文字轉成這種數值表示。
關鍵屬性是:相似的語意會產生相似的數字。兩個意思差不多的句子,embedding 在數值上會很接近。兩個意思截然不同的句子,embedding 就離很遠。這種接近程度用數學衡量,叫向量相似度(vector similarity)(因為這串數字在數學裡叫向量)。
這個概念的早期研究,像 Word2Vec (Mikolov et al., 2013),證明連單個詞都可以表示成保留語意關係的向量:「king」的向量減掉「man」再加上「woman」,會得到接近「queen」的向量。現代 embedding 模型,像 Sentence Transformers,把這個方法擴展到整個句子和段落,在更豐富的層次上捕捉語意。
回到房地產的例子:搜「適合家庭、交通便利」可以匹配到描述為「靠近輕軌、有公園和學校」的房源——不是因為字面重疊,而是因為語意在 embedding 空間裡很接近。
向量資料庫的功能
如果 embedding 是語意地圖上的地址,向量資料庫(vector database)就是讓這張地圖可以大規模搜尋的基礎設施。
實務上的運作方式:
索引建立: 每筆房源描述、學校簡介、社區摘要或其他文字記錄,都被轉成 embedding,連同原始文字一起存進資料庫。
查詢: 使用者提問時,問題也用同一個 embedding 模型轉成 embedding。
相似度搜尋: 資料庫找出跟查詢 embedding 最接近的已儲存 embedding——也就是語意上跟問題最像的記錄。
回傳: 匹配的記錄(原始文字,不只是數字)被回傳,可以當上下文提供給語言模型。
這就是語意檢索能跑起來的原因。系統配對的不是關鍵字,是概念。一個關於「安全區域中的可負擔首購宅」的查詢,可以找到描述為「低犯罪率社區中價格親民的公寓」的房源,因為它們的 embedding 彼此接近。
市面上有好幾種向量資料庫——Pinecone(全託管)、Weaviate 和 Chroma(開源,可選託管方案)等等。選哪個會影響正式環境的工程考量(效能、擴展、成本),但底層原理一樣:把文字用 embedding 存起來、依語意搜尋、回傳相關結果。
系統何時應該說「我不知道」
Grounding 和檢索降低了捏造答案的風險。但如果檢索沒找到相關東西呢?如果目前的 MLS 資料裡根本沒有奧斯汀低於 40 萬的兩房公寓?或者唯一的匹配很勉強——一筆 41 萬的,或套房而非兩房?
正確的行為是棄權(abstention):系統應該承認自己答不了,而不是硬擠出一個聽起來合理的回應。「我找不到符合您條件的當前房源」遠比三筆捏造的房源有用——後者只會浪費買家的時間、侵蝕信任。
但有個重要前提:你不能靠模型自己決定要不要棄權。語言模型被訓練成要產出有幫助的回應,它的預設是回答而非拒絕。就算被指示在不確定時說「我不知道」,模型還是常常會硬擠一個答案出來,特別是問題屬於訓練資料大量涵蓋的領域。
可靠的棄權需要系統設計,光靠提示詞工程不夠。你需要明確的檢查機制:
檢索分數門檻: 如果向量資料庫的相似度分數低於門檻,系統就判定沒有找到夠相關的資訊,直接導向棄權回應,不把低品質結果提供給模型。
信心門檻: 系統評估檢索到的資訊是否確實回答了使用者的問題,不是有檢索到就算數。
覆蓋率檢查: 如果使用者問了三個條件(價格、房數、學校品質),但檢索到的資料只涵蓋其中一個,系統可以標記覆蓋不完整,而不是讓模型用想像力來填空。
這些都是架構決策,發生在模型外部的系統層,不是模型內部。模型可以被指示棄權,但系統可以被設計成強制執行棄權。
為什麼可靠的 AI 是系統設計問題
回到奧斯汀買家一開始的問題。要可靠地回答它,應用需要:
即時 MLS 存取來檢索當前房源(不是靠訓練資料裡對舊房源的記憶)。
郡級稅務記錄查詢來驗證實際稅率。
學校評分 API來從權威來源拿當前評分。
基於 embedding 的搜尋來把買家的自然語言偏好配對到房源描述。
檢索分數檢查來判斷結果好不好到值得呈現。
棄權邏輯來在資料不夠時優雅地拒答。
語言模型來把驗證過的資訊整合成清楚、有幫助的回應。
模型是這個清單裡的一個元件——負責把結構化的證據轉成自然語言回答。這很有價值,但它不是負責檢索房源、驗證稅率、或決定什麼時候該說「我不知道」的元件。那些是模型外部的系統在做的事。
這是這篇的核心論點:可靠的 AI 是系統設計問題,不是模型選擇問題。 更強的模型可能寫出更好的文字,但它不會產出當前的 MLS 資料。更好的提示可能在某些問題上減少幻覺,但它不會去驗證郡級稅務記錄。這些能力來自專門為那些工作設計的系統元件。
RAG 讓來源標註變得*可能*,因為系統知道它檢索了哪些文件,可以把它們跟回答一起呈現。但引用的*忠實度*——生成的文字是否確實反映了所引用來源的內容——是一個需要額外系統設計的獨立問題:要檢查的是模型的陳述是否被檢索到的證據支持,不只是放在一起而已。來源標註是架構特性。忠實的來源標註是評估問題。
常見的誤解
誤解:幻覺是品質問題,更好的模型會解決它
幻覺的比率會隨模型進步而降低,但不會降到零。任何靠統計模式而非驗證過的資料來生成文字的系統,偶爾都會產出聽起來合理的捏造內容。比率會降,但結構性的根因不會消失。對準確性至關重要的應用,不管用什麼模型,架構層面的緩解措施(grounding、檢索、驗證)都是必要的。
誤解:Grounding 可以消除幻覺
Grounding 靠給模型真實資料來運作,降低了捏造事實的風險,但不會完全消除幻覺。模型還是可能誤解檢索到的資料、過度解讀薄弱的證據,或把事實拼錯。Grounding 把失敗模式從「捏造資料」轉成「誤用資料」——顯著改善,但不是完整的解決方案。
誤解:只要用 RAG,就自動有引用
RAG 讓系統能存取來源文件,引用在機制上變成可能。但模型可能生成的陳述並沒有準確反映所引的來源,也可能用誤導的方式混合多個來源。忠實的引用——生成的文字正確呈現了來源實際說的內容——需要明確的評估跟檢查,不是有檢索就夠了。
本文未涵蓋的內容
這篇不是 RAG 的實作教學。不會講分塊策略(chunking)、重新排序(reranking)、檢索工程或流程最佳化。那些是工程主題,後面的文章會處理。
也不講 embedding 模型怎麼訓練、向量資料庫內部怎麼做索引、或怎麼評估檢索品質。這篇的目標是建立詞彙和動機:理解這些元件*為什麼*存在、它們*解決什麼問題*,讓後面文章的工程細節有清楚的基礎。
接下來的方向
Grounding 解決了知識的問題。模型不用再猜公寓房源,因為系統會去檢索真實的。不用再捏造稅率,因為系統會去查。
但如果買家說:「比較這三個物件,查每個的分區規劃,按當前利率算每月還款額,告訴我哪個是最好的投資。」
這已經不是一個檢索問題了。系統沒辦法一次搜尋就完成。它需要查三筆不同的分區記錄、呼叫房貸計算器、從多個面向比較多個物件,然後綜合出建議。這需要規劃、工具使用、還有多步驟的決策能力。
那就是下一篇的主題。
本文引入的關鍵術語
術語 — 定義
幻覺(Hallucination) — 模型產出聽起來正確但實際上沒有任何可驗證資訊作為依據的內容。是文字生成的結構性屬性,而非 bug。
Grounding — 在生成回應之前,將模型的輸出連接到可驗證的外部資料。降低但不消除捏造風險。
檢索(Retrieval) — 搜尋外部知識來源、選取相關結果,並將其作為上下文傳遞給模型以供生成。
Embedding — 文字的數值表示(一串數字),其中相似的語意會產生相似的數字。使得依語意而非關鍵字進行搜尋成為可能。
向量相似度(Vector similarity) — 衡量兩個 embedding 之間有多接近的數學度量,用於判斷兩段文字是否具有相似的語意。
向量資料庫(Vector database) — 一種可搜尋的索引,將文字以 embedding 形式儲存並支援相似度搜尋——找出語意與查詢最接近的記錄。
棄權(Abstention) — 系統在缺乏足夠已驗證資訊時拒絕回答。需要系統層級的設計(分數門檻、覆蓋率檢查),而非僅靠模型提示。
檢索增強生成(RAG, Retrieval-Augmented Generation) — 一種結合外部知識來源檢索與語言模型生成的架構,由 Lewis et al. (2020) 正式提出。
參考資料與延伸閱讀
Lewis, P., Perez, E., Piktus, A., Petroni, F., Karpukhin, V., Goyal, N., Kuttler, H., Lewis, M., Yih, W., Rocktaschel, T., Riedel, S., & Kiela, D. (2020). "Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks." *arXiv:2005.11401*. https://arxiv.org/abs/2005.11401 — 提出 RAG 框架的奠基性論文。
Huang, L., Yu, W., Ma, W., Zhong, W., Feng, Z., Wang, H., Chen, Q., Peng, W., Feng, X., Qin, B., & Liu, T. (2023). "A Survey on Hallucination in Large Language Models: Principles, Taxonomy, Challenges, and Open Questions." *arXiv:2311.05232*. https://arxiv.org/abs/2311.05232 — 針對大型語言模型幻覺類型與比率的全面綜述。
Mikolov, T., Chen, K., Corrado, G., & Dean, J. (2013). "Efficient Estimation of Word Representations in Vector Space." *arXiv:1301.3781*. https://arxiv.org/abs/1301.3781 — Word2Vec 論文,展示了 word embedding 如何捕捉語意關係。
Reimers, N. & Gurevych, I. (2019). "Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks." *arXiv:1908.10084*. https://arxiv.org/abs/1908.10084 — 引入了高效的句子層級 embedding,使實用的語意搜尋成為可能。
Zaharia, M., Khattab, O., Chen, L., Davis, J. Q., Gu, H., Ghodsi, A., Ratner, A., Jordan, M. I., Liang, P., Stoica, I., & Re, C. (2024). "The Shift from Models to Compound AI Systems." *Berkeley AI Research Blog*. https://bair.berkeley.edu/blog/2024/02/18/compound-ai-systems/ — 主張最先進的 AI 成果日益來自元件系統,而非單一模型。
Huang Tzu Lin
With over five years in autonomous robotics, there's a strong passion for incorporating cutting-edge technologies and innovative approaches. Dedicated to transforming the latest research and insights into practical applications, this journey pushes the limits of possibility.
相關文章
訂閱最新資訊
將最新技術洞察直接送到您的信箱。