AI 驅動的客戶支援 — 從聊天機器人到智慧型系統
閱讀順序
LLM Foundations
下一章
尚無可用文章
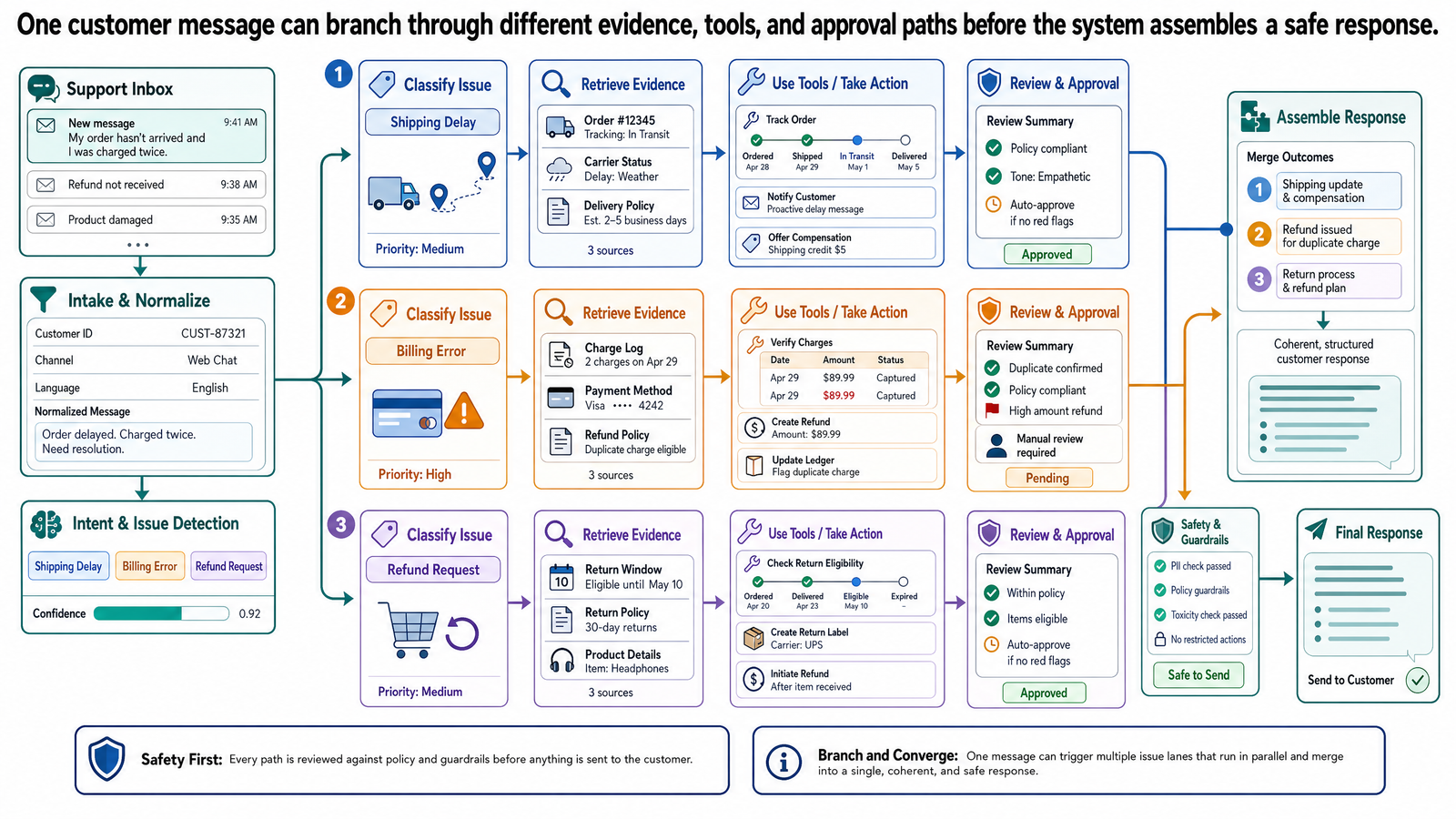
客戶支援是很適合收束基礎概念的範例,因為一則訊息可能同時需要檢索、工具使用、記憶、路由和核准邊界。
來看一位客戶寫給 Relay(一款專案管理 SaaS 產品)的訊息:
"I was charged twice for my Team plan last month, I can't access the new Gantt chart feature, and I need to downgrade before my renewal on Friday."
(「我上個月的 Team 方案被重複扣款了,我用不了新的甘特圖功能,而且我得在週五續約之前降級。」)
一則訊息,三個問題。一筆帳務爭議、一個功能存取問題、一項距離截止日只剩兩天的帳戶變更。每個問題性質不同、需要的資料不同、風險也不同。基本款的聊天機器人——就是那種靠關鍵字比對回制式答案的——三個問題一個都處理不好。它可能回應其中一個、忽略另外兩個,或乾脆把三個混在一起丟出一個跟帳務沾邊的籠統答案。設計好的系統會分開處理每一個,因為它能辨識出這些是不同的問題。
這篇要展示的是:前四篇的每一個概念怎麼在一個產品裡匯聚。客戶支援系統是範例,但真正重點在架構——你學過的那些概念:生成、提示詞、上下文窗口、grounding、檢索、embedding、工具使用、記憶、自主性、核准邊界——它們不是各自獨立的觀念,而是在實際應用中一起運作的組件。
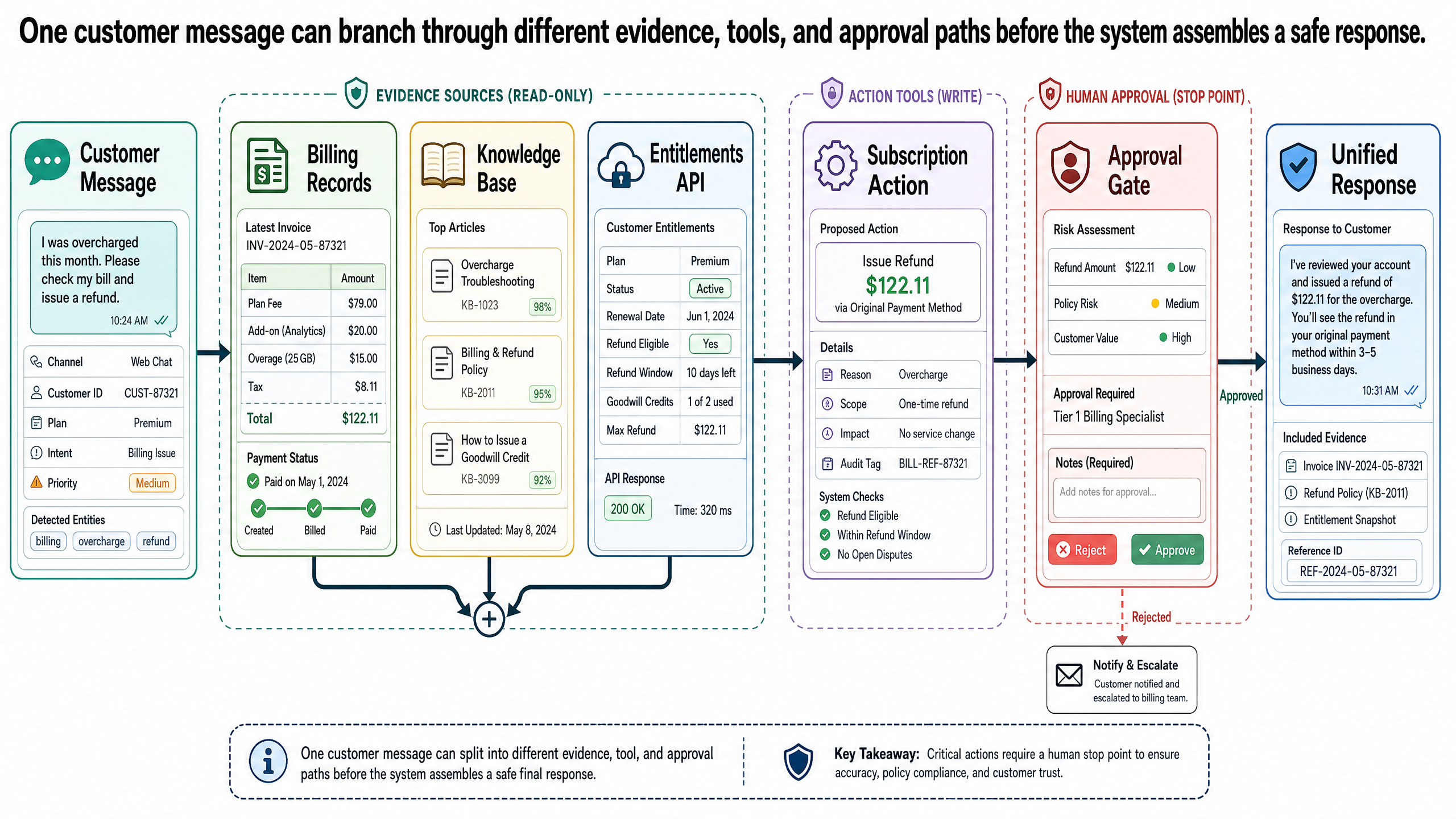
基本聊天機器人做錯了什麼
先從失敗案例看起,因為失敗最有啟發性。
關鍵字比對的聊天機器人看到「charged twice」(重複扣款),就把訊息路由到帳務常見問答,回一段制式段落:「若要查看您的帳單記錄,請前往設定 > 帳務。如果您認為有誤,請聯繫我們的帳務團隊。」它根本沒檢查是不是真的重複扣款了。甘特圖問題沒處理、降級請求也沒處理。它把整則訊息當一個問題,挑了辨識到的第一個關鍵字就交差。
稍微進階一點的聊天機器人——背後有語言模型但缺系統架構——犯的錯不一樣,但同樣嚴重。它生成了一段流暢、自信的三段式回覆。帳務那部分引用了一條退款政策。問題是:那條政策根本不存在。模型生成了「聽起來像退款政策」的文字,因為退款政策在訓練資料裡有可預測的模式。這就是幻覺(hallucination),跟文章 0-1 講的失敗模式一模一樣——模型預測的是統計上最可能的文字,不是事實上正確的文字。
甘特圖存取問題那部分,模型建議「清除瀏覽器快取再試一次」。聽起來像正常客服回覆,但它忽略了真正的原因:這位客戶的方案層級可能根本不含甘特圖功能。沒有比對訂閱方案跟功能權限矩陣,模型就是在猜。降級請求那部分,模型很開心地寫「我已將您的方案降級為 Individual」——但它根本沒有改訂閱的能力。它沒執行任何動作,只是生成了看起來像確認訊息的文字。
三個問題,三次失敗。一次幻覺、一次缺乏 grounding、一次「生成文字」跟「採取行動」之間的落差。每個失敗都對應你已經認識的概念。
檢索如何解決知識問題
帳務問題——「我被重複扣款了」——需要的是事實。不是模型對帳務的一般性知識,而是這位客戶的實際帳單記錄,還有 Relay 的實際退款政策。
這是文章 0-3 講的 grounding 問題。模型的訓練資料不含 Relay 的內部退款政策;就算有,政策也會改。訓練截止點讓模型「記住」的任何政策都可能已經過時。解法就是檢索:在模型起草回覆之前,系統先從權威來源拿到相關資訊。
帳務問題需要兩次檢索。第一次,查帳務資料庫拿客戶近期交易——這是精確的結構化查詢,對帳務服務的 API 呼叫會回傳交易記錄,不是模糊搜尋。第二次,從 Relay 的內部知識庫撈當前退款政策。第二次就是 embedding 發揮作用的地方。
客戶寫的是「charged twice」。Relay 知識庫裡可能沒有標題叫「Charged Twice」的文章。但很可能有涵蓋「重複收費」、「帳務錯誤」、「退款資格」的文章。用 embedding 搜——跟文章 0-3 一樣的概念,把文字轉成數值表示讓相似含義聚在一起——即使用詞完全不同,也能把客戶的自然語言跟正確的政策文件配對。「I was charged twice」跟「duplicate charge refund policy」共享的是語意,不是關鍵字。Embedding 的相似性找到了匹配。
現在模型手上有它需要的東西了:實際帳單記錄顯示 3 月 3 日有兩筆 $49 扣款,實際退款政策說重複收費在 30 天內可自動退款。模型生成的回覆有了事實根據,不再是根據「退款政策通常怎麼寫」的統計模式在猜。
工具如何解決存取問題
第二個問題——「我用不了新的甘特圖功能」——性質不同。答案取決的不是政策文件,而是客戶目前的訂閱方案跟功能權限之間的關係。
光靠檢索的話,可能找到一篇甘特圖的說明文章。但那講的是功能的一般介紹。要回答這位客戶的具體問題,系統得查兩件事:這位客戶目前用什麼方案?哪些方案包含甘特圖?
這就是工具呼叫——文章 0-4 的概念。系統呼叫訂閱服務 API 查客戶目前的方案(Team,月繳),再呼叫功能權限 API 看哪些方案含甘特圖。結果回來了:甘特圖需要 Business 方案或更高,這位客戶用的是 Team,不在涵蓋範圍內。
不過系統在起草回覆前還應該多查一件事:看看這是不是已知問題。也許 Team 方案使用者在某個已結束的測試期間曾被暫時授權,或有個 bug 導致功能看似無法使用。這就是對內部已知問題資料庫做 embedding 檢索的價值。客戶可能追問「那個圖表功能壞了」——模糊、不精確、完全沒提「甘特」。但 embedding 搜配對的是語意。「那個圖表功能壞了」在 embedding 空間裡會落在「甘特圖——存取要求與已知問題」附近,就像文章 0-3 裡「family-friendly neighborhoods」配對到「quiet residential area near light rail」一樣。有事故就浮上來,沒有的話就能有把握地把存取問題歸因於方案限制。
這就是模型用猜的(「試試清除快取」)跟系統實際去查的差別。模型的角色是綜合跟溝通,系統的角色是確保模型開口之前手上有正確的事實。
思維鏈如何結構化工作流程
客戶一則訊息塞了三個問題。系統得辨識出來,依各自性質分開處理。這就是思維鏈推理——文章 0-2 裡的逐步推理技巧——上場的地方。不過這裡不是使用者手動寫在提示詞裡的,而是內建在系統自身指令中的機制。
Relay 客服 agent 的系統提示詞可能長這樣:「當客戶訊息包含多個問題時,分別識別每個問題。依類別分類(帳務、存取、帳戶、技術、一般)。確定每個問題所需的資料來源和工具。獨立解決各問題後,再起草一份整合回覆。」
跟你在文章 0-2 看到的旅行規劃推理技巧是同一回事——在衝向最終答案前,先把複雜問題拆成明確步驟。不同的是,在正式環境裡這種推理結構是設計在系統提示詞中的,不是使用者即興發揮。甚至不同客戶層級可能對應不同的系統提示詞——企業客戶的給更廣的操作權限,免費層的有更嚴格的限制和更早觸發的上報。結果就是:系統不會把三個不同問題攪成一團,而是當三條獨立的解決路徑來處理,最後匯聚在一份回覆裡。
分類這步為什麼重要?因為它決定後續走哪條路。帳務問題觸發帳單記錄查詢和政策檢索。存取問題觸發訂閱和權限檢查。帳戶變更走一條完全不同的路——涉及核准邊界的路。
自主性光譜如何適用
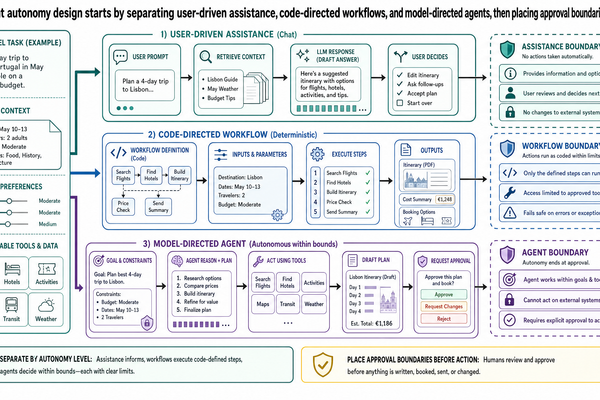
文章 0-4 介紹了自主性光譜:從固定流程、路由式工作流程,到輔助式,再到有邊界的 agent 和長時間執行的自主系統。客戶支援大概是最能看出「同一段對話裡,不同任務該落在光譜不同位置」的場景了。
帳務查詢——自動化。 查帳單記錄、比對退款政策,屬於低風險、高信心、容易驗證的任務。系統可以自己來。它檢索資料、確認重複扣款、引用政策,把結果寫進回覆。查詢和描述都不需要人類核准。
存取診斷——半自動化。 系統可以檢查方案、驗證功能矩陣、判斷甘特圖需要更高方案,也可以起草說明。但碰到模糊地帶——客戶曾參與測試計畫、有已知 bug、權限資料不一致——系統應該標記問題而不是猜答案。這就是文章 0-3 講的棄權(abstention)。系統有夠多證據描述情況,但還不夠確定診斷對不對。它要說清楚自己知道什麼、不知道什麼。
有截止日的降級——需要人類核准。 客戶想在週五續約前降級。這涉及修改訂閱,有財務和合約上的影響。即使系統可以存取訂閱管理 API,沒有人類核准就執行降級,跨越了一條重要的邊界。
這就是文章 0-4 的描述/建議/行動框架。降級這件事,系統該這樣處理:
描述:「您的 Team 方案將於週五 3 月 22 日續約。降級至 Individual 方案會將您的月費從 $49 降為 $19。」
建議:「根據您的要求,我可以為您準備降級的處理作業。」
行動: 只有在人類客服確認,或客戶透過經過驗證的操作(不是只靠聊天訊息)明確授權後才執行。
系統可以描述、可以建議,但不能自己動手改帳戶。這條邊界存在的原因很簡單:犯錯的代價——降錯帳戶、客戶其實不想降、處理了違反合約最低期限的變更——遠高於多等一下確認的代價。
記憶如何維持對話的連貫性
客戶的訊息是對話的開始,不是全部。系統得在整個互動中追蹤狀態。這就是文章 0-4 的記憶概念實際在發揮作用。
對話記憶保存即時交流的內容:客戶說了什麼、系統回了什麼、問了哪些後續問題。客戶回「不是,我說的是上週還看得到、但現在不見了的那個圖表功能」,系統需要原始訊息的上下文才能理解「那個圖表功能」指什麼。
任務狀態追蹤解決進度:問題一(帳務)已解決——重複扣款已確認、退款已建議。問題二(存取)處理中——方案已查、權限已驗證、等客戶確認。問題三(降級)待處理——已描述並建議、等核准。這個狀態跨訊息持續存在,防止系統遺漏「哪些問題做完、哪些還沒」。
持久知識是系統依賴的穩定資訊:Relay 的退款政策、方案功能矩陣、訂閱管理規則。存在對話之外,不隨訊息改變。
你可能會想:如果客戶有很長的歷史紀錄呢?這就回到文章 0-2 講的上下文窗口限制。假設這位客戶有 47 張過往工單。上下文窗口——模型有限的工作記憶——裝不下全部。系統必須決定哪些跟這次對話有關。設計好的系統可能只拉最近三張工單的摘要,或只拉跟帳務和帳戶變更相關的。這是設計決策,不是模型能力問題。什麼東西被載入上下文,是系統架構師決定的——因為全部放入根本不是選項。
客戶的情緒狀態在這裡也很重要。訊息的語氣——三個問題、一個截止日、字裡行間的挫折感——是系統該捕捉到並在後續互動中延續的信號。客戶情緒升溫,系統不該重置為中性語氣。對話記憶保留了這個信號,系統提示詞可以指示模型在不帶防禦性的前提下承認客戶的挫折感。前提是:系統得提供夠多的對話上下文,這條指令才能發揮作用。
系統何時必須停下來請人類介入
不是每個動作都該自動化,也不是每個情況都有明確解法。文章 0-4 講的核准邊界,在客戶支援系統裡不是理論概念,而是實際在跑的機制。
系統應該在以下情況上報給人類客服:
動作有系統無法完全驗證的財務後果(處理退款、修改訂閱)
客戶的情況模糊,手上的資料不夠釐清(權限檢查回傳不一致的結果)
客戶明確要求跟真人對話
系統對自己的分類或解法信心低於閾值
在 Relay 的情境裡,降級就是明確該上報的案例。系統已經描述了情況、建議了行動。一位人類客服審查、確認客戶意圖,然後處理變更。客戶感受到的是一次簡短的交接——「我已準備好您的降級請求,一位團隊成員會在週五續約前確認並處理」——而不是遙遙無期的等待。
這條邊界不是系統的失敗,是刻意的設計。系統自己處理了三個問題中的兩個,並替第三個準備好高效的人類處理方案。接手的人類客服不需要從頭來。他們看得到系統的分類、帳務證據、權限檢查結果、建議的行動方案。他們要做的是驗證和執行,不是重新診斷。
研究也支持這種做法。AI 輔助客服的相關研究一致發現,混合系統——AI 處理例行問題、替人類準備好複雜案例——表現優於完全自動化和完全人工。關鍵不在最大化自動化,而在把自動化的邊界畫在對的位置。
客戶實際的體驗是什麼
退一步,先把架構放旁邊,從客戶的角度看。
他們帶著挫折感發了一則訊息,裡面塞了三個急的問題。幾秒鐘之內,系統回覆:
「我發現您的 Team 方案在 3 月 3 日有一筆 $49 的重複扣款。根據 Relay 的退款政策,重複收費有資格自動退款。我已標記此項進行處理,退款應會在 5-7 個工作日內出現在您的帳單上。 關於甘特圖功能:您目前的 Team 方案不包含甘特圖,此功能在 Business 方案中提供。我已檢查是否有已知的存取問題,目前沒有發現進行中的事故。如果您認為之前曾有存取權限,我可以將此標記給我們的團隊進一步調查。 關於您的降級請求:您的 Team 方案將於週五 3 月 22 日續約。降級至 Individual 方案會將您的月費從 $49 降為 $19。我已準備好這項變更,一位團隊成員會在您的續約日期前確認並處理。」
三個問題,三個回覆,每個都用適當的自主性層級處理。帳務用證據解決。存取給出明確原因並提供上報選項。降級請求被描述、建議,並排入人類確認的佇列。
客戶看不到架構。他們看到的是一個快速、準確、誠實的回覆——把他們的問題當獨立問題分別處理。這是系統設計的成果,不是某個更厲害的聊天機器人。
為什麼這是一個系統,而非聊天機器人
前四篇的每一個概念都出現在這個範例裡,而且沒有哪個能單打獨鬥。
生成(文章 0-1)用自然語言起草回覆。但沒有 grounding(文章 0-3),它會捏造退款政策。沒有工具使用(文章 0-4),它查不到客戶的實際方案。沒有思維鏈(文章 0-2),它會把三個問題混成一團。沒有記憶(文章 0-4),它會忘記哪些問題已解決。沒有核准邊界(文章 0-4),它要嘛做太多(擅自降級),要嘛做太少(連描述情況都不肯)。沒有審慎的上下文管理(文章 0-2),它要嘛塞滿不相關的歷史工單,要嘛丟掉客戶先前說過的話。
這個系統有效不是因為某個單一組件特別精密,而是因為組件被正確地組合在一起。檢索提供證據、工具提供資料、模型提供語言、提示詞提供結構、記憶提供連續性、核准邊界提供安全性。結果就是一個能對三合一訊息給出三個恰當回覆的產品——不是因為語言模型更聰明,而是因為圍繞它的系統經過設計。
這就是主系列文章 1 要正式講的複合式系統概念。能力來自組件的組合,不只是模型本身。
本文不是什麼
這篇不是「如何建構客服系統」的教學。不會講訊息佇列、webhook 架構或資料庫 schema,也不推薦特定供應商或 API。
也不是在主張 AI 應該取代人類客服。前面的範例以一位人類確認降級作為收尾,那次交接是刻意的。系統處理它擅長的部分,替它處理不了的部分準備好讓人類高效接手。
目的更聚焦:展示你在文章 0-1 到 0-4 學到的概念不是學術練習,它們是真實產品的構建基石。如果你能看到生成、grounding、檢索、工具使用、記憶和核准邊界怎麼在一個客服系統裡匯聚,你就能在任何其他應用中認出相同的模式。
接下來,我們要換個場景了
回頭看這五篇,你已經走了不少路。
你學了 LLM 在做什麼、為什麼會幻覺。你看到提示詞、上下文窗口和逐步推理怎麼塑造模型行為。你理解了模型為什麼需要 grounding——檢索、embedding、外部知識——才能產出可靠的答案。你探索了自主性光譜:從簡單的助理,經過工作流程,到有工具使用、記憶和核准邊界的有邊界 agent。而在這篇裡,你看到所有概念在一個產品中匯聚。
一路走來,你規劃了一趟赫爾辛基之旅、研究了奧斯丁的房地產,還替一個 SaaS 產品診斷了一張客服工單。每個範例都在前一個的基礎上引入新概念。
現在,系列要轉彎了。
接下來的十篇會往深處走——複合 AI 系統架構、正式環境等級的流程、進階檢索、agent 迴圈機制、文件智慧,還有多模態證據處理。範例也會換:一個為 OptiVerse Travel 打造的 AI 副駕駛(copilot),服務對象是一家中型旅行社,正在規劃一趟複雜的日本無障礙旅行。你在 Level 0 規劃了一趟個人的赫爾辛基之旅——接下來你會看到,要打造一個能專業地、大規模地、在真實限制條件下完成同樣事情的系統,到底需要什麼。
你不需要從頭開始。你需要的,其實你已經有了:一套關於 AI 系統如何建構的工作詞彙。
先盤點一下你手上有哪些工具——
# — 概念 — 首次出現 — 一句話說明
1 — 生成(Generation) — 文章 0-1 — 語言模型根據機率預測產出文字,流暢不等於正確
2 — 幻覺(Hallucination) — 文章 0-1 — 模型自信地輸出事實上錯誤的內容,是機率生成的固有風險
3 — 提示詞工程(Prompt engineering) — 文章 0-2 — 透過指令設計引導模型行為,是控制輸出品質的第一道槓桿
4 — 上下文窗口(Context window) — 文章 0-2 — 模型的工作記憶上限,超過就會遺忘或忽略資訊
5 — 思維鏈(Chain-of-thought) — 文章 0-2 — 讓模型逐步推理,拆解複雜問題以提升準確度
6 — Grounding — 文章 0-3 — 將模型輸出錨定在可驗證的外部資料上,而非靠訓練記憶
7 — 檢索(Retrieval) — 文章 0-3 — 在生成前從外部知識來源取得相關資訊
8 — Embedding — 文章 0-3 — 將文字轉為數值表示,讓語意相近的內容在向量空間中靠近
9 — 工具使用(Tool use) — 文章 0-4 — 語言模型判斷何時呼叫外部 API 並格式化請求的能力
10 — 記憶(Memory) — 文章 0-4 — 對話記憶、任務狀態、持久知識——三種不同存續期的資訊層
11 — 自主性光譜(Autonomy spectrum) — 文章 0-4 — 五個層級,描述系統對自身執行的掌控程度
12 — 核准邊界(Approval boundary) — 文章 0-4 — 描述、建議、行動——劃定系統能自主到哪裡、哪裡要人類拍板
13 — 複合式系統(Compound system) — 文章 0-5 — 能力來自組件的組合,而非單一模型的獨角戲
這十三個概念不是清單上的打勾項目,而是你接下來讀主系列時的工具箱。每篇新文章都會用到好幾個,放進更深、更具體的技術脈絡裡。
準備好了嗎?我們出發。
參考資料與延伸閱讀
Zaharia, M., Khattab, O., Chen, L., et al. (2024). "The Shift from Models to Compound AI Systems." *Berkeley AI Research Blog.* Introduces the compound AI systems framework -- the architectural perspective that capability comes from composing multiple components, not from a single model call. This framing underpins the distinction between chatbot and system made throughout this post. bair.berkeley.edu/blog/2024/02/18/compound-ai-systems
Xu, A., Liu, Z., Guo, Y., et al. (2017). "A New Chatbot for Customer Service on Social Media." *Proceedings of the 2017 CHI Conference on Human Factors in Computing.* An early empirical study of AI chatbots in customer service, demonstrating the gap between user expectations and chatbot capabilities, and establishing patterns for intent classification and handoff to human agents. research.ibm.com/publications/a-new-chatbot-for-customer-service-on-social-media
Brynjolfsson, E., Li, D., and Raymond, L. (2023). "Generative AI at Work." *National Bureau of Economic Research, Working Paper 31161.* Studies the deployment of a generative AI assistant for customer support agents, finding significant productivity gains for less-experienced agents and improved customer sentiment. Demonstrates the hybrid human-AI pattern described in this post. nber.org/papers/w31161
Gangadharaiah, R. and Narayanaswamy, B. (2019). "Joint Multiple Intent Detection and Slot Labeling for Goal-Oriented Dialog." *Proceedings of NAACL-HLT 2019*, pages 564-569. Shows why single-intent assumptions are weak for real-world dialog and proposes an attention-based model for jointly detecting multiple intents and labeling slots within a single message -- the classification challenge underlying the multi-issue triage described in this post. aclanthology.org/N19-1055
Zendesk. (2024). "CX Trends 2024: Unlock the Power of Intelligent CX." *Zendesk Global Research Report.* Industry survey data on AI adoption in customer support and operational patterns around automation, routing, and escalation. zendesk.com/newsroom/articles/cx-trends-2024
Huang Tzu Lin
With over five years in autonomous robotics, there's a strong passion for incorporating cutting-edge technologies and innovative approaches. Dedicated to transforming the latest research and insights into practical applications, this journey pushes the limits of possibility.
相關文章
訂閱最新資訊
將最新技術洞察直接送到您的信箱。