提示詞、上下文窗口,以及你如何與 LLM 對話
閱讀順序
LLM Foundations
上一篇裡,我們丟了一句話給 LLM——「幫我規劃一趟赫爾辛基(Helsinki)之旅」——然後拿到一份細節滿滿的行程表:餐廳名、交通路線、一日遊安排。讀起來很順,看起來也合理,但好幾個細節事後被證實是錯的。模型沒壞,只是輸入沒給它什麼限制條件可以依循。
這篇要講的是:如果你更認真地跟模型溝通,結果會怎樣?輸入裡加上結構、限制條件、範例、推理指示,輸出會有什麼變化?同時我們也得面對一個硬限制——不管你怎麼精雕細琢輸入都躲不掉的——就是模型有限的工作記憶,也就是上下文窗口(context window)。理解這兩面——怎麼跟 LLM 有效溝通,以及就算溝通做到最好也解決不了什麼——是後面所有內容的基礎。
一樣用赫爾辛基旅行的例子,但這次旅行者比較認真。
同一個模型,兩種不同的輸入
這是文章 0-1 裡的原始提示詞(prompt):
幫我規劃一趟赫爾辛基之旅。
這是同一個人認真想過自己要什麼之後送出的:
我正在規劃六月下旬到赫爾辛基的五天旅行。我的預算大約是每天 120 歐元,包含餐飲和當地交通,但不含住宿。我吃素,比起搭計程車我更喜歡步行,而且我對新藝術風格和北歐古典主義建築特別感興趣。我想安排至少半天的波爾沃行程。三個具體問題:(1) 從卡利奧步行到芬蘭堡是否可行,還是應該搭渡輪?(2) 一週中哪一天去波爾沃最能避開人潮?(3) 你能推薦岩石教堂(Temppeliaukio Church)附近一家素食友善的午餐餐廳嗎?
模型的輸出明顯不一樣了。它開始圍繞步行路線來排每天的行程、標出前往芬蘭堡需要搭渡輪、把建築類景點集中安排,也試著回答那三個具體問題。它還是一個根據模式生成文字的 LLM,但它援引的模式,現在被有意義的限制條件引導了。
重點不是哪個比較聰明。模型在兩次請求之間沒有變聰明——它只是收到了更有用的輸入。
什麼是提示詞
提示詞(prompt)就是你提供給語言模型的文字輸入,是模型開始生成回應之前看到的全部東西。實務上,提示詞可以短到一句話,也可以長到幾千字的結構化指示、限制條件加範例。
有一點很關鍵:提示詞就是模型在這次請求中的整個世界。不像人類同事會從過去的對話、共同的背景知識來推測你要什麼,模型只知道提示詞裡寫的東西。預算沒寫進去,它就不知道有預算。飲食限制沒提,它就不會管。模型不是粗心——它就是沒有其他資訊來源。
所以提示詞的品質是一個工程問題,不只是寫作練習。提示詞是你的意圖和模型行為之間的介面。
系統提示詞與使用者提示詞
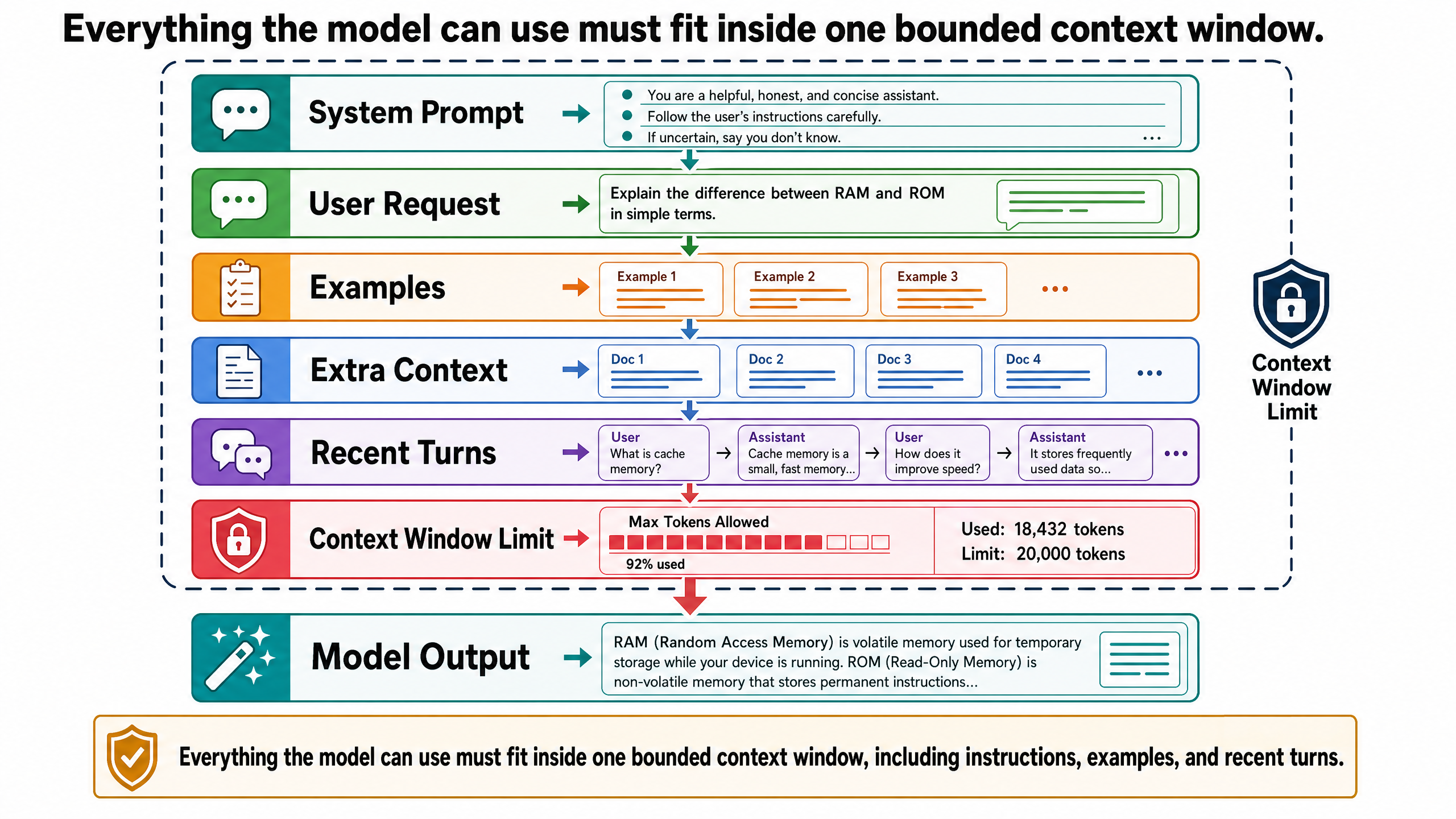
大多數 LLM 應用會把提示詞分兩層。
系統提示詞(system prompt,有時叫系統訊息)負責設定模型的角色、限制條件、行為規則。通常是開發者寫的,不是終端使用者。比方說:
你是一個旅行規劃助理。在地點之間始終包含預估步行時間。始終包含每日預算估計。推薦餐廳時,註明是否有素食選項。如果你對某個事實性聲明不確定,請明確說明而非猜測。
使用者提示詞(user prompt)就是實際用的人發出的請求:
規劃第三天圍繞卡利奧社區和芬蘭堡的行程。我想在上午參觀芬蘭堡要塞,下午步行探索卡利奧。
系統提示詞在整個對話中一直存在;使用者提示詞隨每則訊息改變。兩個加在一起,就是模型在任何一次回應中處理的完整輸入。這種分離的好處是:應用設計者可以確保一致的行為——每次回應都附預算估計、每次都標不確定性——不用依賴使用者自己記得要求。
你可能用過某些聊天機器人,覺得它「天生就知道」要用特定風格回話、遵守某些規則。那幾乎可以確定是你沒看到的系統提示詞在起作用。
提示詞工程:結構化的溝通
提示詞工程(prompt engineering)就是刻意結構化你的輸入來改善模型的輸出。聽起來很高深,其實大多數時候就是對你想要的東西具體、有條理、講清楚——本來就是讓任何技術溝通有效的好習慣。
赫爾辛基的例子裡可以看到幾個模式:
限制條件縮小輸出範圍。 「每天預算 120 歐元」排除了高檔餐廳和私人導覽。模型有了具體的篩選條件可以套用。
具體性引出細節。 「對新藝術風格和北歐古典主義建築感興趣」讓模型有理由提到赫爾辛基中央車站的花崗岩立面和新藝術風格細節,而不是列一堆一般景點。
直接的問題得到直接的回答。 三個編號問題幫回應建立了結構。模型會映射輸入的組織方式。
這些不需要特殊語法或內部知識。你要做的就是想清楚模型需要什麼資訊才能給出有用的結果,然後提供給它。
少樣本提示:用範例來教
有時候,與其解釋你要什麼,不如直接秀給它看。少樣本提示(few-shot prompting)就是在提示詞裡放一個或幾個輸入-輸出範例,讓模型去配對那個模式。
這個名字來自 Brown 等人 2020 年的一篇重要論文。那篇論文展示了 GPT-3 只要在提示詞裡看幾個範例,就能做新任務,完全不用重新訓練。「shots」就是範例:零樣本(zero-shot)沒有範例,單樣本(one-shot)一個,少樣本(few-shot)幾個。
用赫爾辛基的場景來說,少樣本提示可能長這樣:
以下是我希望每日行程的格式: 範例 — 斯德哥爾摩(Stockholm)第一天: - 09:00 — 瓦薩博物館 Vasa Museum(預留 2 小時;門票 190 瑞典克朗;無需預訂) - 11:30 — 步行至舊城區 Gamla Stan(20 分鐘,平坦地形) - 12:00 — 在 Södermalm 的 Hermans 午餐(素食自助;約 155 瑞典克朗) - 當日總計:約 45 歐元 現在用相同格式規劃赫爾辛基第一天。
模型不需要你說「加步行時間」或「標價格」或「用 24 小時制」。它自己從範例裡推出來了。少樣本提示在你期望的輸出有特定結構、而那個結構用範例展示比用文字描述更容易的時候,特別好用。
思維鏈提示:要求逐步推理
思維鏈提示(chain-of-thought prompting)是要求模型在得出結論之前,先用明確的步驟來處理問題。Wei 等人 2022 年的論文正式提出這個方法,發現模型被提示「逐步思考」時,推理任務的表現顯著提升。
你可能會問:模型真的在「思考」嗎?我們需要精確理解這裡發生的事。思維鏈是一種提示技術——一種把輸入結構化,讓模型產生更審慎的中間工作。模型不是像人那樣在想,它在生成一串 token 序列,其中每個步驟都限制了後面的內容。這種序列結構有時會比直接跳到答案更好。
但在正式系統裡,不應該隨意要求模型輸出冗長的可見推理。這些文字可能冗長,也不一定可靠反映模型內部過程,更不一定適合直接給使用者看。更穩健的做法通常是要求模型在內部完成推理,最後輸出答案、精簡檢查清單、前提假設、使用的證據,或驗證摘要。
用行程規劃來說,思維鏈提示可能長這樣:
在建立當日計畫之前,請按照以下步驟進行: 1. 列出卡利奧和海濱一帶與新藝術風格和北歐古典主義建築相關的主要景點。 2. 估計每個景點通常需要多少參觀時間。 3. 估計每對景點之間的步行時間。 4. 檢查總時間是否能在一天之內完成(上午 9 點到下午 6 點)。 5. 現在建立行程表,並標記任何無法容納的項目。
模型的輸出現在包含可見的中間工作:一份有時間估計的景點清單、步行距離的計算,還有最終行程前的可行性檢查。這些中間工作讓錯誤變得容易發現。如果模型估計從卡利奧走到設計區只要 15 分鐘——那段路大概 3 公里,穿過市中心——這個錯會出現在過程裡,不會埋在一個充滿自信的最終答案裡。
思維鏈不會讓模型變聰明,可見推理文字也不是答案正確的證明。它只是處理複雜任務的一種提示模式。在教學範例裡,可見的中間工作能幫助讀者診斷輸出;在正式產品裡,精簡的理由、明確檢查項目和證據摘要通常比冗長推理稿更安全。
上下文窗口:模型的工作記憶
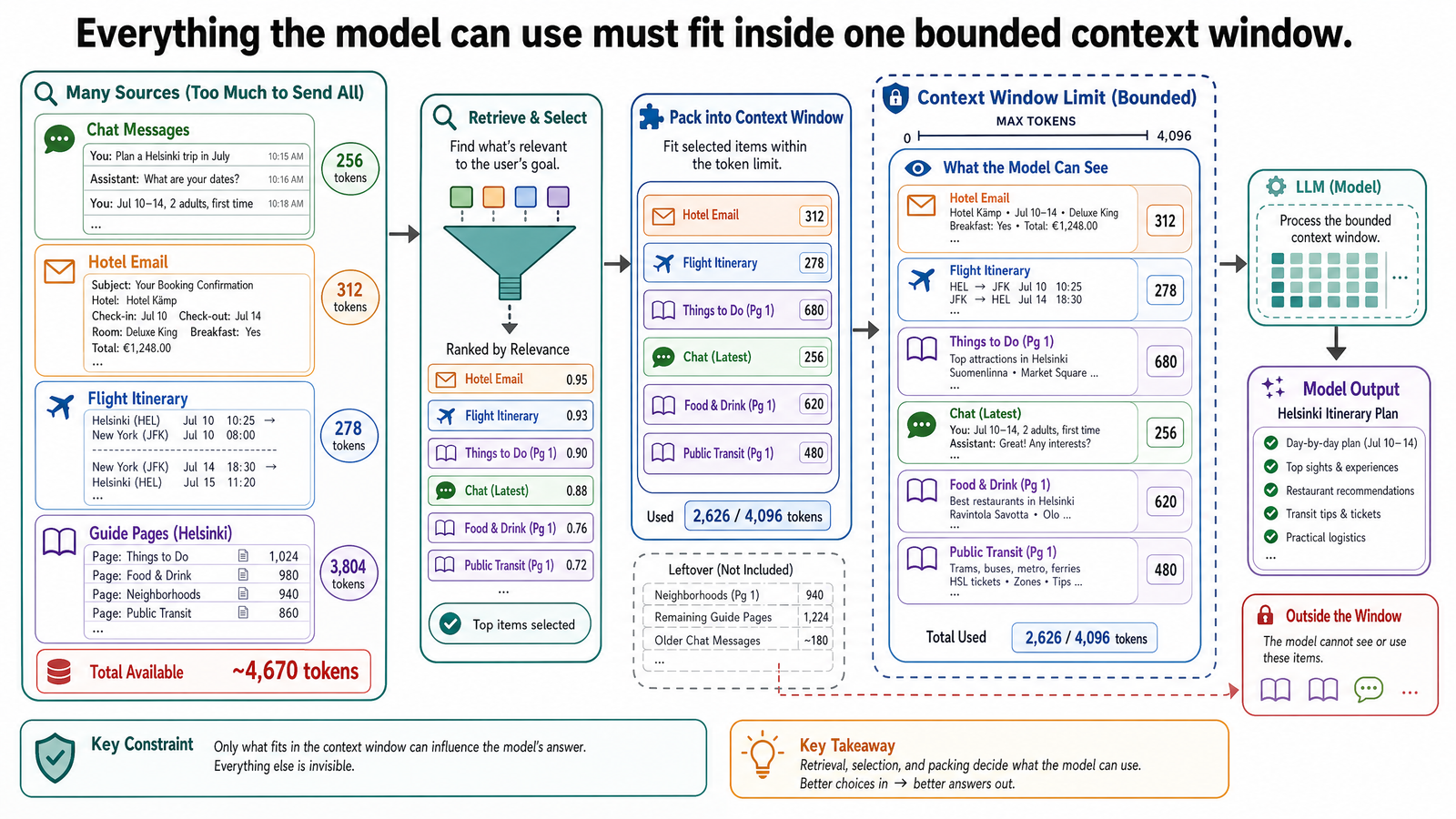
前面講的所有東西——系統提示詞、使用者訊息、範例、推理步驟——全部都得放入模型的上下文窗口(context window)。這是模型一次能處理的文字總量:輸入加輸出的總和。
你可以把上下文窗口想成一張固定大小的桌子。模型要處理的東西全得擺在這張桌子上:系統提示詞、對話歷史、你貼的文件,還有它正在生成的回應需要的空間。桌子滿了,就有東西得被拿掉。
早期的 LLM 上下文窗口很小——GPT-2 大約 1,000 個 token,GPT-3 大約 2,000,GPT-3.5-Turbo 拉到 4,000。到 2026 年 5 月,規模已經大幅擴展:
Anthropic 的 Claude 模型,例如 Opus 4.6 和 Sonnet 4.6,在 Claude API 中支援高達 100 萬個 token
Google 的 Gemini API 模型表列出 Gemini 2.5 Pro、Gemini 2.5 Flash 與 Gemini 3 Pro Preview 的輸入上限為 1,048,576 個 token
OpenAI 目前的前沿模型,例如 GPT-5.5 和 GPT-5.4,在 OpenAI API 模型文件中列出約 100 萬個 token 的上下文
這些窗口都很大。一百萬 token 大致可以裝好幾本完整的書。但「很大」不等於「無限」,這個區別在實務上很重要。
Token:如何衡量上下文
Token 是語言模型處理的文字單位。文章 0-1 裡簡單介紹過,當時是把它當模型在推論時預測的單位。這裡,token 作為上下文窗口和成本的計量單位同樣重要。
Token 不是字詞。它們是分詞器(tokenizer)切出來的片段——一個把文字拆成模型能處理的單位的前處理步驟。英文裡,一個 token 大約 0.75 個單詞;反過來說,一個英文單詞大約 1.3 個 token。「architecture」是兩個 token。「Helsinki」看分詞器不同,一到兩個 token。標點、空格、格式都會吃 token。
這在兩個層面上很實際。
第一,它決定上下文窗口能塞多少東西。那份你想貼的 15 頁赫爾辛基旅遊指南?大概每頁 250 個字,3,750 個字,約 4,900 個 token。對 200,000 token 的窗口來說不算什麼。但加上系統提示詞(幾百個 token)、一整個下午來回規劃的對話歷史(可能好幾萬個 token),還有模型回應需要的空間,預算收緊的速度可能比你想的快。
第二,token 是 API 供應商算錢的依據。價格經常變動,所以精確數字應視為供應商設定,而不是長期有效的教學事實。穩定的原則是:輸入與輸出 token 通常分開計費,而且輸出 token 通常較貴,因為輸出必須逐 token 生成。
輸入 token: 提示詞、對話歷史、檢索文件、工具結果,以及其他送進模型的上下文
輸出 token: 模型生成的文字,通常費率高於輸入 token
一次赫爾辛基行程請求可能用掉 2,000 個輸入 token 和 1,000 個輸出 token——幾分錢而已。但一個服務幾千個使用者的正式應用,每個人都在多輪對話、貼各種文件,累積下來成本就很可觀。Token 計數不是理論問題,是營運問題。
上下文填滿時會發生什麼
回到赫爾辛基旅行者。前幾則訊息很順利:一個結構化的請求、一份不錯的行程、幾個關於波爾沃後勤的追問。對話很有成效。
然後旅行者開始貼東西了——飯店確認信、航班行程表、一份 15 頁的旅遊指南、朋友推薦的餐廳清單。每次貼都往對話歷史裡塞了幾千個 token。
二十則訊息之後,旅行者問:「記得嗎,我吃素——你能推薦我們飯店附近的晚餐選擇嗎?」
模型推薦了一家海鮮餐廳。
這不是文章 0-1 裡講的那種訓練資料層面的幻覺(hallucination),而是上下文窗口的問題。飲食限制是在第三則訊息提的。到第二十三則,中間貼的那些文件已經把第三則訊息推出上下文窗口了。模型真的看不到——它不是在忽略限制條件,是根本看不見。
這就是上下文限制在實務上的樣子。模型對你的對話沒有持久記憶,它只有一個固定大小的窗口,裝著最近的部分。資訊一旦落在窗口外面,對模型來說就消失了——無聲無息,沒有任何警告。
有些應用會把舊訊息做摘要,或把關鍵事實(像飲食限制)抽出來放入系統提示詞來緩解。但那些是圍繞模型建的系統層級方案,不是模型自己的能力。基本行為就是:不在窗口裡的東西,等於不存在。
溫度:為什麼輸出會變化
問模型兩次岩石教堂(Temppeliaukio Church)附近的餐廳推薦,你可能會拿到不同答案。這不是 bug,是語言模型生成文字方式的必然結果。
就像文章 0-1 講的,LLM 透過計算整個詞彙表上的機率分布來預測下一個 token。「traditional」可能有 12% 的機率是下一個詞,「popular」可能 9%,「excellent」可能 6%。模型不會每次都挑機率最高的那個——它從這個分布裡取樣,所以就有了變化。
溫度(temperature)就是控制這個變化程度的參數。技術上說,它在原始分數(logits)丟進 softmax 函數(把分數轉成機率)之前,先對分數做縮放。溫度低(接近 0),分布變尖,最高機率的 token 幾乎一定被選中。溫度高(接近 1 或更高),分布變平,低機率的 token 也有比較大的機會被選到。
實務上怎麼用:
低溫度(0.0-0.3): 輸出更確定、更重複。適合一致性和準確性很重要的任務,像提取結構化資料或回答事實性問題。
中等溫度(0.4-0.7): 在一致性和多樣性之間取平衡。大多數一般任務適用。
高溫度(0.8-1.0+): 更有創意但也更不可預測。適合腦力激盪或生成多元選項,但更容易出現意外或不連貫的輸出。
旅遊推薦用中等溫度合理——你想要建議之間有變化,但不想看到虛構的餐廳名。從飯店確認信提取日期?溫度越接近零越好。任務決定正確的設定。
大多數終端使用者不會自己調溫度,是應用開發者根據任務來設的。但知道有這個東西,就能解釋一個常見的困惑:「我問了同樣的問題卻得到不同答案。」那是模型按設計在運作,不是壞掉了。
那堵牆:即使完美的提示詞也解決不了的問題
赫爾辛基旅行者現在學會寫結構化的提示詞、給範例、要求逐步推理,也在謹慎管理上下文。行程比文章 0-1 的通用版本好太多了。但有些問題不管怎樣都解決不了:
「岩石教堂(Temppeliaukio Church)這個星期四有開嗎?」模型沒辦法查當前的開放時間。訓練資料有截止日期,模型也連不上即時網站。
「坎皮(Kamppi)到波爾沃目前的巴士時刻表是什麼?」模型查不了今天的時刻表。它可以告訴你坎皮巴士站有頻繁班次,但確認不了具體發車時間。
「幫我在那家素食餐廳訂今晚七點的位子。」模型沒辦法跟外部系統互動。它不能訂位、不能發 email、也進不了訂位平台。
「我的飯店確認號碼是否正確?」模型可以讀上下文窗口裡的確認信,但沒辦法拿去跟飯店的實際系統核對。
這些都不是提示詞的問題。再怎麼重新結構化、加範例、用思維鏈,都沒辦法讓模型存取即時資料、對外部系統做驗證、或在真實世界採取行動。這些是單一模型在靜態上下文上運作的架構限制。
這個區別很關鍵,因為它告訴你精力該花在哪。如果輸出含糊或結構不好,更好的提示詞幫得上忙。但如果輸出需要即時資訊、外部驗證、或跟其他系統互動,更好的提示詞就沒用了。問題不在你怎麼跟模型對話,而在模型本身就不具備這個任務需要的能力。
常見的誤解
誤解:更長的提示詞總是更好的提示詞
提示詞裡加更多文字,只有在內容相關且結構良好的時候才有用。你只需要波爾沃的資訊卻貼整本旅遊指南進去,會浪費 token、增加成本,實際上還可能讓輸出變差——模型可能被不相關的上下文帶偏,對跟問題無關的資訊給太多權重。簡潔有針對性的提示詞,往往比放入過多資訊的效果好。
誤解:模型會「記住」你之前的對話
沒有記憶這回事。它有的是一個裝著近期對話歷史的上下文窗口。對話歷史超過窗口大小,舊的訊息就被丟了。感覺像記憶的東西,其實是系統每次都在重新讀對話紀錄——而那份紀錄有大小限制。
誤解:思維鏈意味著模型在「思考」
思維鏈提示會產出看起來像推理的文字。但模型是根據機率分布依序生成 token,不是在思考。這招有效是因為生成中間步驟會以有用的方式限制後續的生成。它是一種提示策略,不是認知的證據。
誤解:溫度為零會給出「正確」答案
溫度為零讓輸出變確定——每次都選最高機率的 token。但最高機率不等於正確。如果訓練資料有誤,或正確答案在訓練中代表性不足,溫度為零的回應會一致且確定地出錯。溫度控制的是變異性,不是準確性。
這篇文章不是什麼
這篇不講怎麼建構克服上面那些限制的系統。檢索增強生成(RAG)、工具使用、外部資料存取和 grounding 都是針對那些問題的架構解法,那些是文章 0-3 要講的。
這篇也不碰微調(fine-tuning)、基於人類回饋的強化學習(RLHF),或其他修改模型本身的技術。焦點嚴格限在你透過跟一個固定模型之間的介面能做到的事:提示詞、上下文窗口和生成設定。
接下來的方向
更好的提示詞確實讓行程好了很多。結構、限制條件、範例、明確的推理指示,讓同一個模型變得實用許多。但模型還是沒辦法驗證事實、存取即時資料、或引用來源。那些不是提示詞問題,是架構問題。
下一篇會講系統怎麼補上這些缺口:用檢索把模型連到外部知識、給它工具的存取權、讓它的輸出建立在可驗證的證據上。模型還是核心,但它不再是整個應用程式。
參考資料與延伸閱讀
Brown, T. B., Mann, B., Ryder, N., Subbiah, M., et al. (2020). "Language Models are Few-Shot Learners." *Advances in Neural Information Processing Systems 33 (NeurIPS 2020).* 以 GPT-3 展示少樣本提示的論文,證明大型語言模型僅透過提示詞中的少量範例即可執行新任務,無需重新訓練。 arXiv:2005.14165
Wei, J., Wang, X., Schuurmans, D., Bosma, M., et al. (2022). "Chain-of-Thought Prompting Elicits Reasoning in Large Language Models." *Advances in Neural Information Processing Systems 35 (NeurIPS 2022).* 正式提出思維鏈提示,並證明要求模型生成中間推理步驟,能顯著提升算術、常識與符號推理任務的表現。 arXiv:2201.11903
Anthropic. (2026). "1M context is now generally available for Opus 4.6 and Sonnet 4.6." 記錄目前 Claude API 模型的 100 萬 token 上下文窗口。 claude.com/blog/1m-context-ga
OpenAI. "Models." 目前 OpenAI API 模型的上下文窗口與能力參考。 developers.openai.com/api/docs/models
Google AI for Developers. "Gemini models." 目前 Gemini API 模型的輸入與輸出 token 上限參考。 ai.google.dev/gemini-api/docs/models
Schulhoff, S., Ilie, M., Balepur, N., et al. (2024). "The Prompt Report: A Systematic Survey of Prompting Techniques." 提示技術的全面綜述,涵蓋少樣本提示、思維鏈提示及其各種變體。 arXiv:2406.06608
Huang Tzu Lin
With over five years in autonomous robotics, there's a strong passion for incorporating cutting-edge technologies and innovative approaches. Dedicated to transforming the latest research and insights into practical applications, this journey pushes the limits of possibility.
相關文章
訂閱最新資訊
將最新技術洞察直接送到您的信箱。