LLM Fundamentals
How large language models work, from tokens and context windows to prompting, hallucinations, and the case for building systems around models. These posts establish the foundational vocabulary every AI engineer needs before diving into system architecture or infrastructure.
5 篇文章
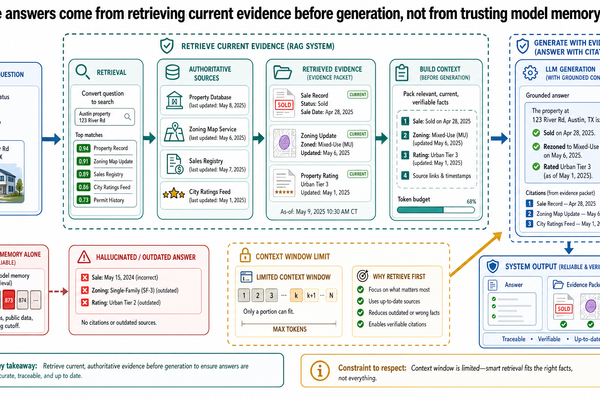
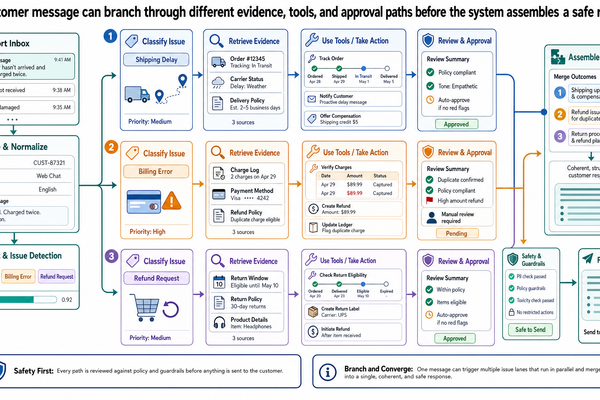
為什麼 LLM 需要幫助 — 幻覺、Grounding,以及系統設計的必要性
大型語言模型能產出流暢又自信的文字。而這份自信,正是問題所在。模型可以把一筆已經下架的房源、一個上一季才變動的稅率、一則三年前的學校評分,講得頭頭是道。它沒有任何機制去查核——本來就不是為查核設計的。它的工作是根據訓練資料預測下一個最合理的 token,而合理不等於正確。
Huang Tzu Lin
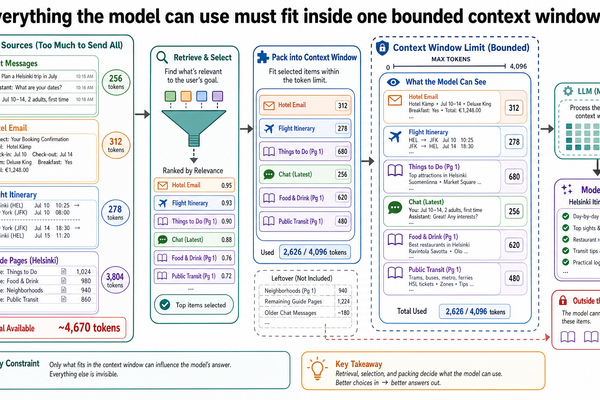
提示詞、上下文窗口,以及你如何與 LLM 對話
上一篇裡,我們丟了一句話給 LLM——「幫我規劃一趟赫爾辛基(Helsinki)之旅」——然後拿到一份細節滿滿的行程表:餐廳名、交通路線、一日遊安排。讀起來很順,看起來也合理,但好幾個細節事後被證實是錯的。模型沒壞,只是輸入沒給它什麼限制條件可以依循。
Huang Tzu Lin
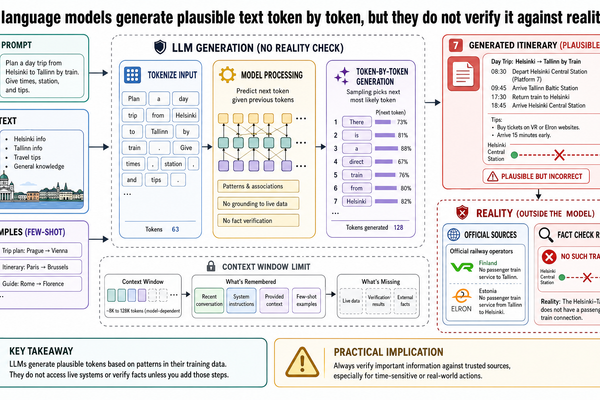
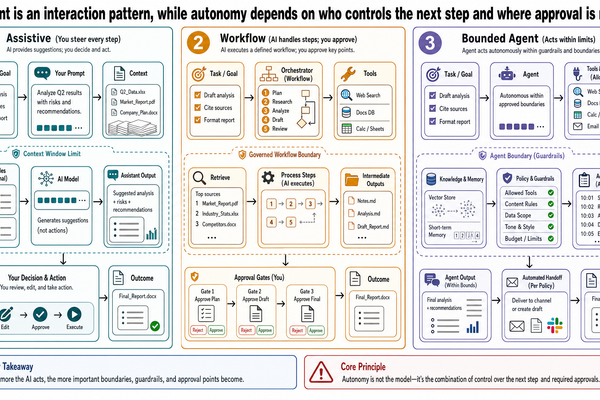
大型語言模型到底在做什麼
你在某個 AI 應用裡打了一段話,幾秒鐘後螢幕上跑出好幾段文字——流暢、有條理,讀起來像某個很懂的人寫的。這種事現在大家都習以為常了。但如果你打算在這些系統上面蓋東西,真正該理解的是:從你按下送出到那些文字出現,中間到底發生了什麼。
Huang Tzu Lin