
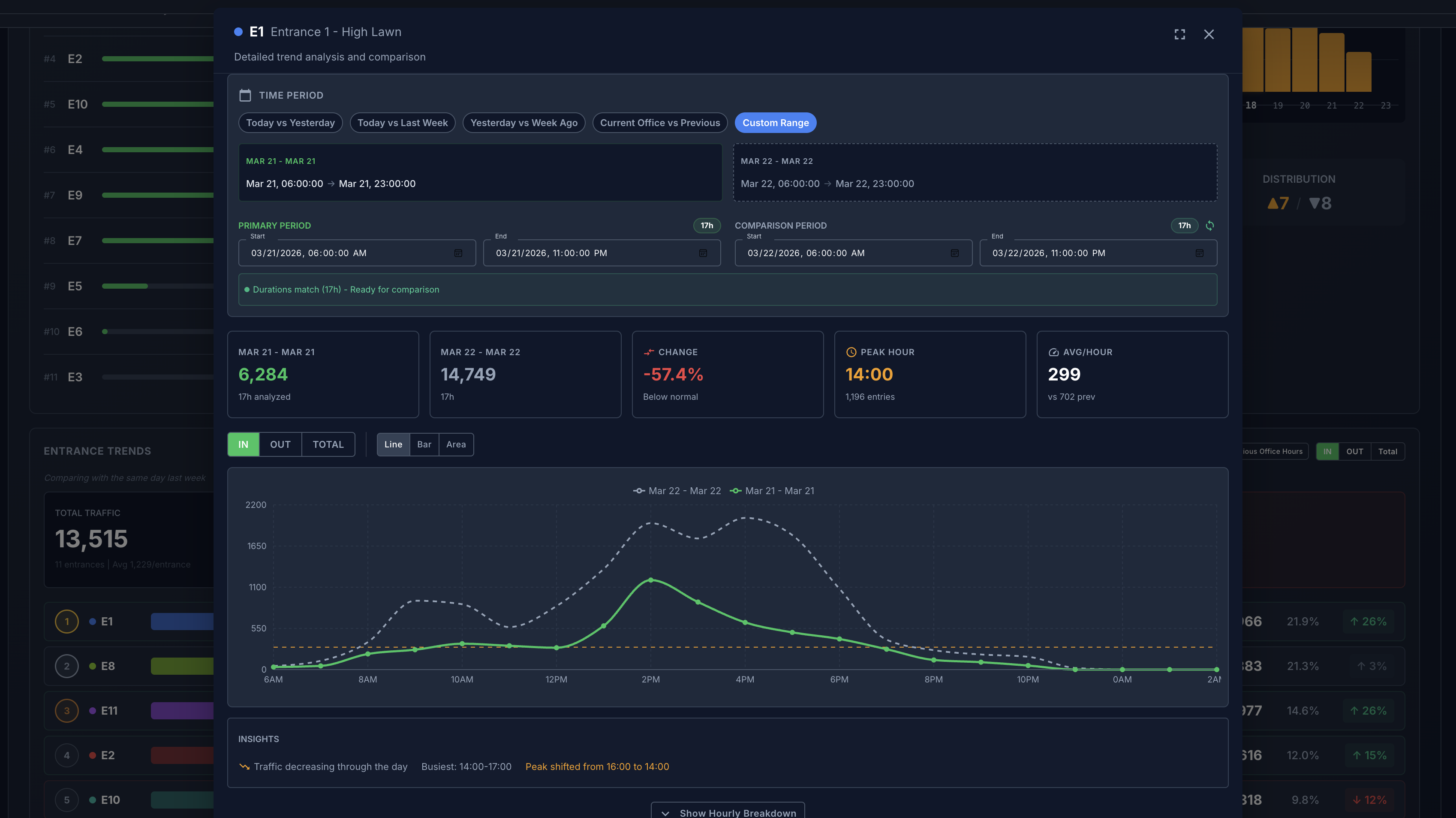
Footfall trend
Track peaks, lulls, and time-of-day demand for staffing, campaigns, and store comparison.
Demand pulse 84
Real-Time Sensing, Proactive Alerts, Data Analytics






End-to-end solutions for critical environments and intelligent decision-making.
Purpose-built LiDAR intrusion detection for railway safety. Monitors track corridors and platform zones, detecting obstacles and hazards to ensure operational safety.
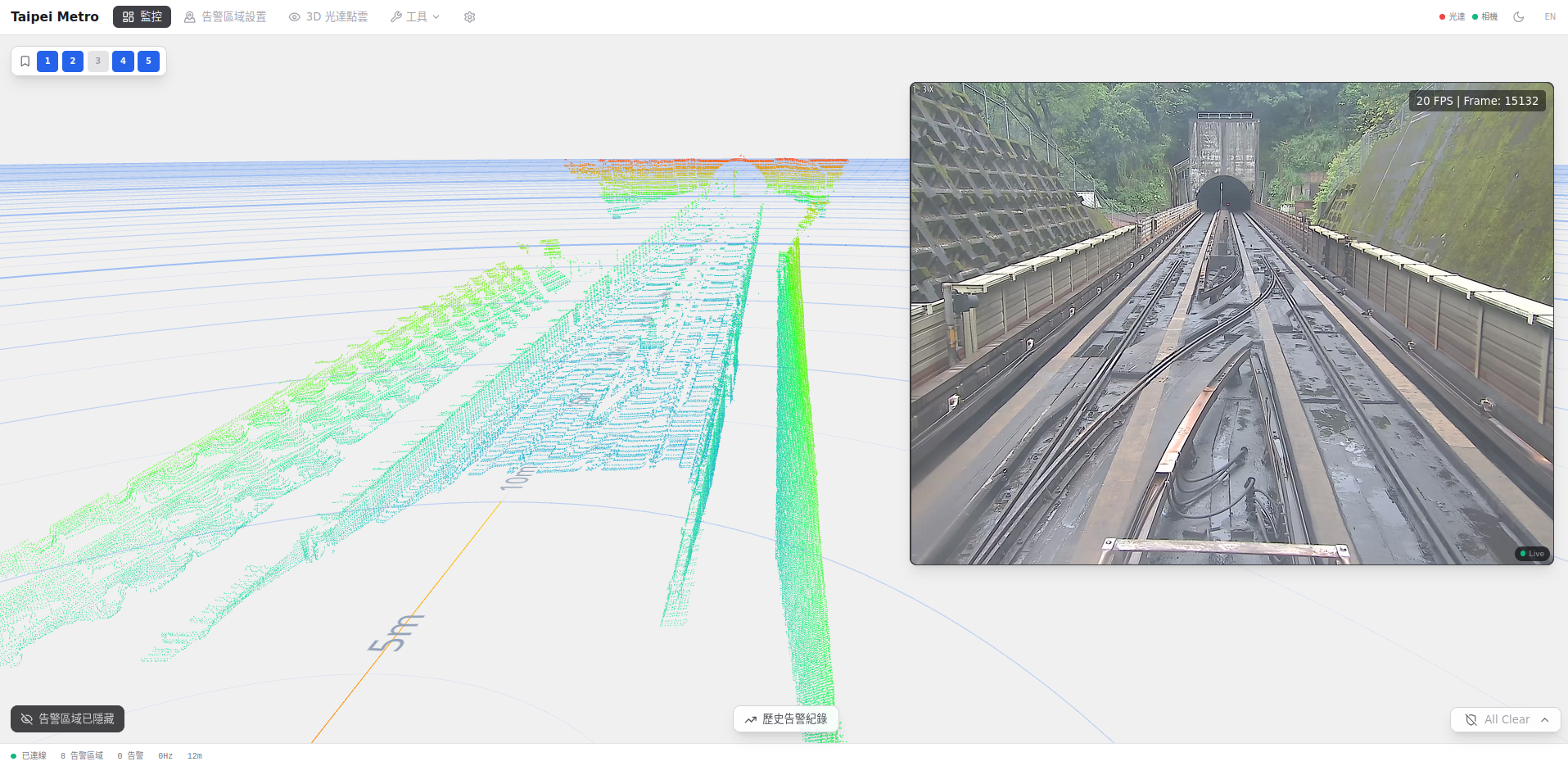
Get the latest insights on LiDAR perception and intelligent field management.
OptiVerse turns traffic, dwell, queues, and staff support into measurable store operating insight.
See where customers move, wait, and engage.
Turn peaks, staff coverage, and service gaps into staffing and floor decisions.
Compare zone dwell, cross-zone paths, and notable visits to find repeatable sales patterns.
From live perception to store decisions, OptiVerse turns movement into measurable, comparable, and actionable retail intelligence.
Track peaks, lulls, and time-of-day demand for staffing, campaigns, and store comparison.
Surface long dwell, cross-zone browsing, and journeys that may need service support.
Compare product-zone engagement to understand fixture, category, and assisted-sale impact.
Review how close staff presence is to real customer demand and reduce service gaps.
Built for retail operations, not just dashboard viewing.
Ingest live traffic, zones, dwell, and staff movement.
Insights are grounded in actual store motion and historical playback, not static mock data.
Calculate footfall trends, notable visits, dwell, and coverage gaps.
Customers, staff, and product zones appear in one operating view.
Deliver concise action summaries for stores, operations, and HQ.
Metrics translate into staffing, merchandising, coverage, and store-comparison decisions.