AI 助理、AI Agent,以及兩者之間的一切
閱讀順序
LLM Foundations
一個有用的 AI 系統,關鍵不在於它被稱為助理還是 Agent,而在於它對下一步擁有多少控制權。
來看一位購屋者對不動產研究工具提出的需求:
「比較這三間房產,查詢每間的學區,以目前的房貸利率估算每月還款金額,標記任何分區問題,然後推薦最適合有兩個小孩的家庭的選項。」
一個請求,五項子任務。要好好回答,系統得做多次資料查詢、一次財務計算、多面向交叉比較,最後還要根據買家的偏好做判斷。單純的「你問我答」無法處理。但一條僵化的腳本也可能漏掉關鍵資訊——比如一項進行中的分區重劃,可能直接翻轉推薦結果。
這類請求逼我們面對一個核心問題:系統到底該自己處理多少?
答案不是二選一。不是「助理還是 agent」這麼簡單,而是一道自主性光譜(autonomy spectrum)。光譜上的正確位置取決於任務本身、風險高低,和可用工具的品質。理解這道光譜,比死記標籤有用得多。
同一個任務,三種做法
要看光譜為什麼重要,最直接的方式就是拿同一個請求,用三種不同的系統自主性層級跑一遍。買家的問題一樣,變的只是系統掌控的程度。
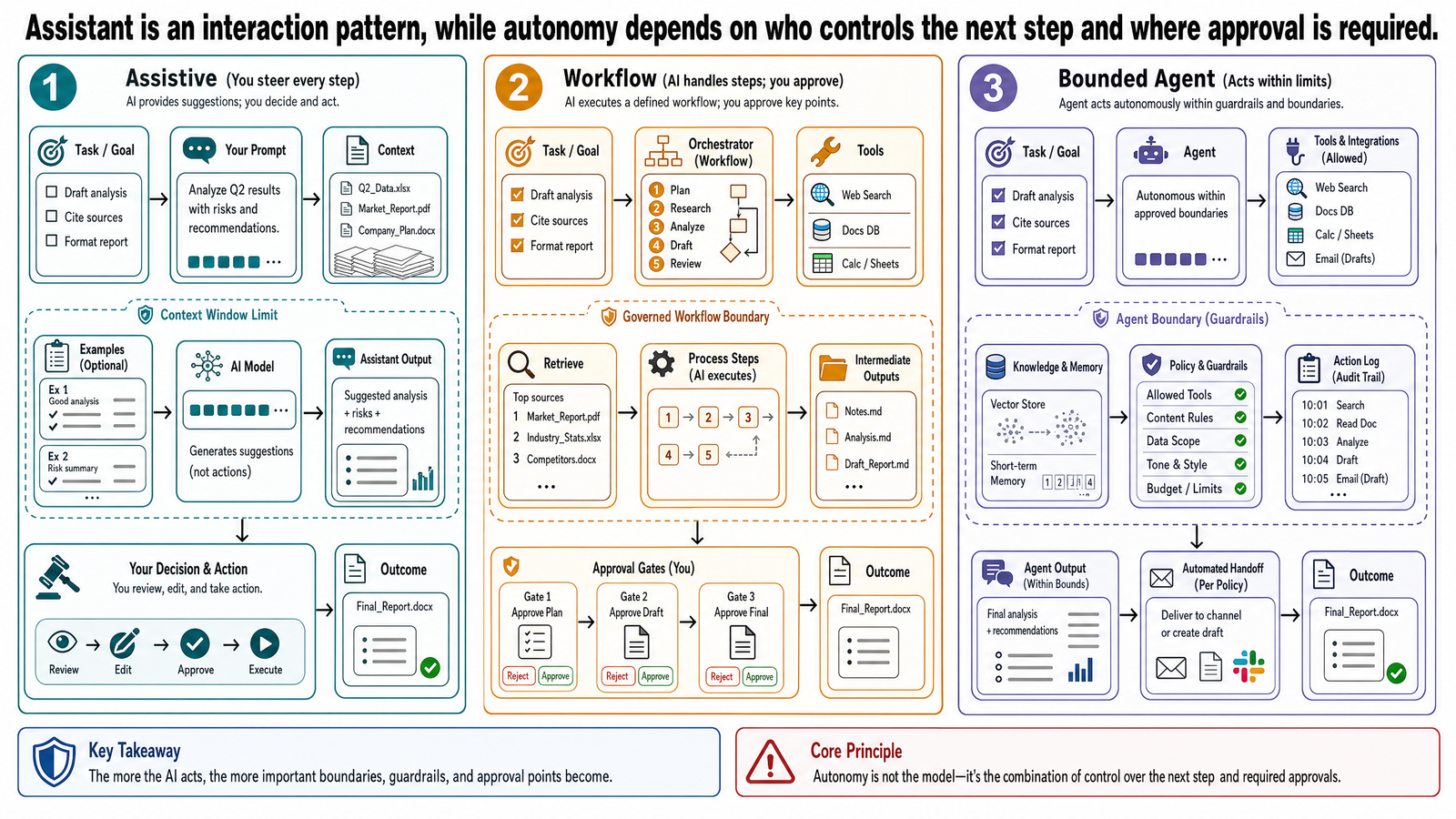
版本一——輔助式(Assistive)
系統每一步都等你下指令。
買家要求比較,系統回:
「這是您選的三筆房源。要不要我先查第一間的學區?」
買家說好。系統查完房產 A 的學區資料,秀出來,然後又停:
「準備好查第二間的學區了嗎?」
就這樣一步一步。每個子任務都得等買家點頭、看結果、再指示下一步。系統絕不自己決定接下來做什麼。叫它才動,做完就停。
這就是輔助式——人類主導,系統幫忙。簡單、低風險的查詢沒問題。但碰到五步驟的比較任務就很煩:買家得自己在腦中管整個工作流程(workflow),哪些查過、哪些沒查、怎麼拼起來——全靠自己記。
版本二——固定工作流程(Fixed Workflow)
這次系統照一條預設流程跑。買家送出請求,系統依序執行:
擷取三間房產的房源細節。
查每間的學區。
算每間的預估月付金額。
依一組標準面向做跨房產比較。
產出摘要表格。
效率高多了。買家不用手動推每一步就能拿到結構化的比較結果。但流程是死的——不管途中發現什麼,都走同樣步驟、同樣順序。
問題來了。假設房產 B 坐落在一個有待決重新分類的區域——一項商業分區重劃,可能兩年內讓這條住宅街出現貨車車流。固定流程裡沒有「檢查分區標記」這步,因為它本來就不是為了應對意外設計的。比較表格漂漂亮亮,但漏掉了一個關鍵事實。
版本三——有邊界的 Agent(Bounded Agent)
這次系統有了規劃能力。收到買家請求,自己拆子任務、開始執行——但在明確的邊界內運作。
它擷取三筆房源、查學區。處理到房產 B 時,注意到郡政府記錄裡有個標記:一份待決的分區重劃申請。這不在原始計畫裡。系統決定拉出分區記錄、讀申請細節,發現重新分類可能允許相鄰地塊做輕度商業使用。
它據此調整了比較結果。房產 B 學區很強,但分區風險對重視穩定住宅環境的家庭來說是個大問題。系統更新分析、加入分區發現,呈現結果——但不會擅自做最終推薦:
「根據學區、每月費用和社區穩定性,房產 C 似乎最適合有兩個小孩的家庭。不過,房產 B 擁有評等最高的學區。注意:房產 B 有一份待決的分區重劃申請(案號 #2025-RZ-0482),可能允許相鄰地塊進行輕度商業使用。建議您在做決定前檢視分區細節。需要我調出完整的申請書嗎?」
注意這裡:系統自己規劃步驟、做了臨場調適、用了原本沒被指定的工具,而且知道什麼時候該上報而不是逕行行動。這就是有邊界的 agent 行為——有夠多的自主性處理複雜狀況,又有夠強的約束在高風險決定前踩煞車。
自主性光譜(Autonomy Spectrum)
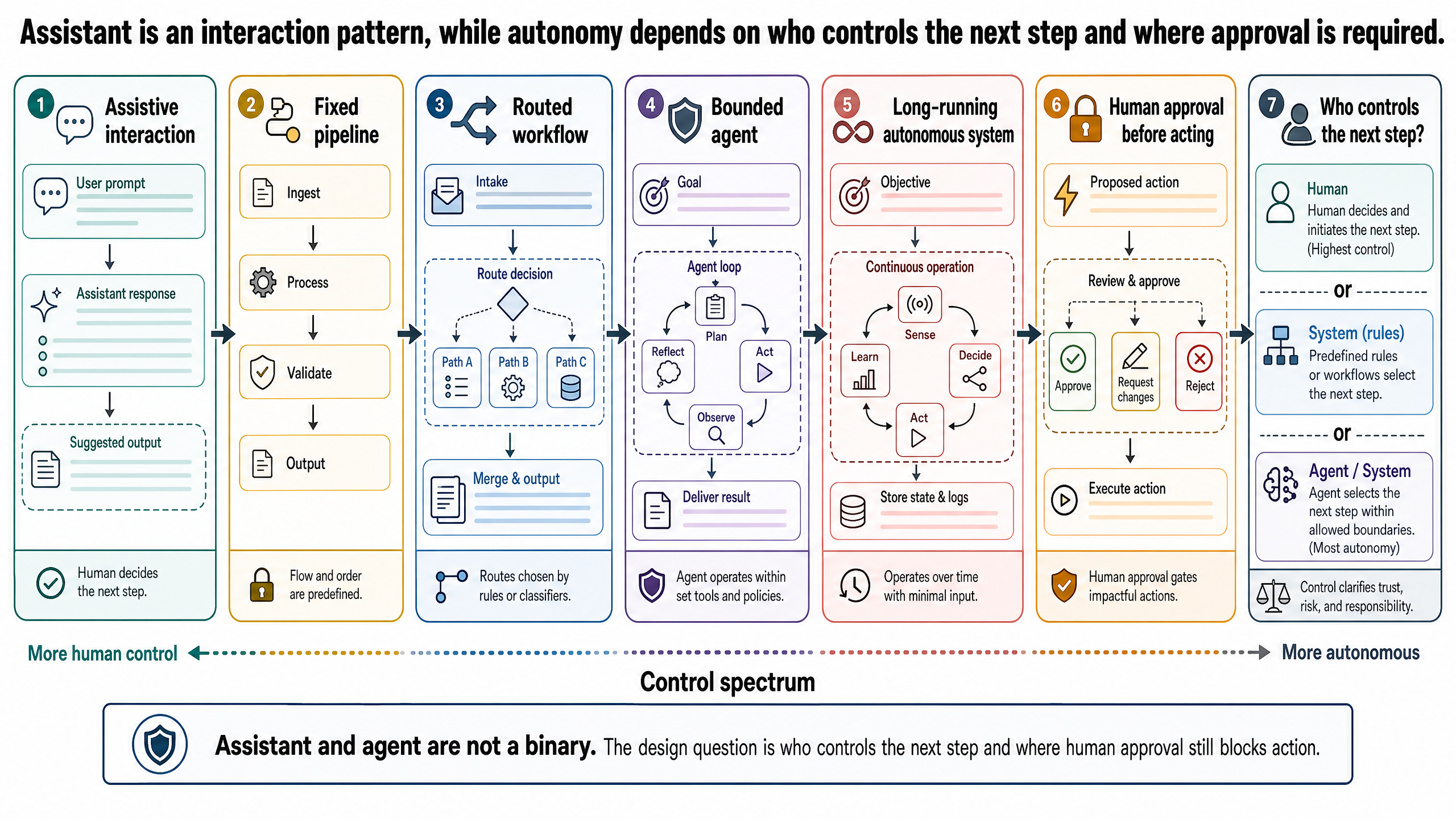
上面三個版本不是三種不同的產品,而是光譜上的三個點。我們需要的框架不是「助理 vs. agent」,而是五個逐步擴大決策範圍的層級——也就是系統有多大的自由度來選自己的下一步。
層級一——固定流程。 系統照預設步驟跑,人類事先定義工作流程,系統負責執行。適合理解透徹、可以重複的任務。一偏離預期就出問題。
層級二——路由式工作流程。 系統能根據輸入在預定義的路徑間做選擇。分類器或一組規則決定走哪條。比固定流程靈活,但能走的路在設計時就定死了。
層級三——輔助式。 系統幫忙檢索、草擬、分析,但使用者掌控工作序列。人類控制每個下一步。適合研究、分析,以及使用者想直接掌控流程的場景。
層級四——有邊界的 agent。 系統能自己規劃行動序列、選工具,碰到意外資訊也能調適。它在明確邊界內運作:核准的工具清單、支出限制、上報規則,還有高後果行動的強制人工核准。
層級五——長時間執行的自主系統。 系統在極少人類監督下追求目標,跨越長時間自行決策並行動。對今天大多數實際應用來說,還停留在願景階段。層級四到五之間的落差,正是大多數尚未解決的可靠性和安全問題所在。
重點是:光譜不是成熟度階梯,層級五不見得比層級二好。一條能穩定處理房貸申請的固定流程,比一個偶爾送出錯誤報價的全自主 agent 有價值多了。選對層級,要看任務複雜度、工具品質,和犯錯的代價。
工具使用(Tool Use)與 API
從層級一往上,系統都得跟外部服務打交道。不動產的例子裡,這些服務包括 MLS 房源資料庫、學區邊界服務、房貸利率計算器、郡政府分區記錄系統。這些資訊不在系統內部,得向外取。
怎麼取?靠 API(application programming interface,應用程式介面)。API 是程式跟程式之間溝通的結構化方式:請求資料、傳指令、觸發動作。不動產系統查學區時,對學區 API 送一個包含房產地址的結構化請求,收回學區名稱、學校評等、入學資料的結構化回應。
在 AI 系統裡,工具使用(tool use)是指語言模型能判斷什麼時候該呼叫外部 API、怎麼格式化請求。模型本身不執行 API 呼叫——周圍的系統處理實際的網路請求。但「要不要呼叫工具」、「呼叫哪個」、「參數怎麼填」,這些判斷是模型做的。
這既是關鍵能力,也是關鍵限制。沒有房貸計算器工具,系統就算不了月付金額——它只能根據訓練資料裡的模式去猜,而那些模式可能是過時利率。2026 年初,美國 30 年期固定房貸利率大約 6-6.5%,但會波動。如果系統因為訓練資料偏向 2020-2021 年的利率而猜「大約 3%」,估算會嚴重誤導。
換句話說:AI 系統的可靠性上限取決於它能用的工具。有邊界的 agent 搭配高品質、維護良好的工具,能產出值得信賴的結果。同樣的 agent 架構配壞掉或過時的工具,只會產出聽起來很有信心的錯誤。工具品質是系統設計的責任,模型補不了。
語言模型工具使用的相關研究——包括 Schick 等人在 Toolformer(2023)上的工作——已經證明語言模型可以學會辨識自身輸出何時不夠可靠,進而呼叫外部工具。這不是模型「想要」用工具,而是一種學到的模式:面對這類輸入,產生工具呼叫比直接產生文字能帶來更好的結果。
記憶不是單一概念
買家在十則訊息前提到「兩個小孩」,系統得記住這個細節,後面的學區比較才有意義。系統查了三間裡兩間的學區後暫停,它得知道上次做到哪。系統查 MLS 資料庫時,存取的是一個跟任何對話無關的外部知識庫。
三種不同的資訊職責。全部放入「記憶」這頂大帽子底下只會越來越難以管理。拆開來看。
對話記憶(conversation memory)是多輪對話中保留下來的資訊。買家提到「兩個小孩」和「家庭」,就形塑了系統在整個工作階段的優先順序。系統一旦丟了這個上下文——因為對話超過模型的上下文窗口,或工作階段重新開始——它可能轉去優化投資報酬率,而不是家庭適合度。
任務狀態(task state)是追蹤進行中工作流程的結構化資訊。房源已擷取、三間裡兩間的學區已查、房貸計算還沒做。它記的是「做完什麼、還沒做什麼、中間結果在哪」。與其說是記憶,不如說是進度追蹤器。
持久知識(durable knowledge)是存在外部系統裡、比任何對話或任務都更長壽的資訊。MLS 資料庫、學區記錄、郡政府分區檔案——這些是權威的資料儲存。系統從裡面讀,但不該把它們跟自己的「記憶」混淆。系統不是「記得」房產 B 被劃為住宅區,它是去查了那個資料庫。
三種類型的存續期不同、更新規則不同、權威等級也不同。對話記憶是短暫的、使用者專屬。任務狀態是工作階段範疇、系統管理。持久知識是永續的、由外部流程治理。設計記憶不是要給系統「更好的回憶力」,而是釐清哪些資訊該放哪一層、每一層怎麼維護。
後面的文章會再分出第四層——工作記憶(working memory),就是為單一推理步驟組裝的臨時上下文。目前三層夠用了。
核准邊界(Approval Boundaries):描述、建議、行動
不是所有輸出都承載同樣的風險。呈現事實資料的系統跟提交購買報價的系統,做的是根本不同的事。最實用的思考方式是把系統行動分三個層級。
描述(Describe)。 系統不帶判斷地呈現資訊。「房產 B 位於 Lincoln Elementary 學區。Lincoln Elementary 在 GreatSchools 上的評等為 7/10。」系統只負責報告,人類自己判讀意義。
建議(Recommend)。 系統加入詮釋。「根據學校評等、通勤時間和每月費用,房產 C 似乎最適合您的家庭。不過,請注意房產 B 相鄰地塊有待決的分區重劃。」系統做了判斷,但人類有最終決策權。
行動(Act)。 系統採取有現實後果的動作。「以 385,000 美元加標準附帶條件對房產 C 提出報價。」這改變了現實世界的狀態,產生法律義務,不是改一下 prompt 就能撤銷的。
這三者之間的邊界,是任何有現實影響的系統中最重要的設計決策。今天大多數上線的系統都在「描述」到「建議」的範圍內。進入「行動」就需要明確的人工核准,而這條核准邊界(approval boundary)應該是一級架構組件——不是事後才想到要補的東西。
這個框架跟 NIST AI Risk Management Framework(AI RMF 1.0, 2023)的原則一致。NIST 強調:AI 系統的自主性越高,治理、透明度和人類監督就要越強。描述/建議/行動的分層,就是落實這種比例原則的務實做法。
前面版本三的不動產 agent 正好展示了這一點:它描述了分區發現、建議房產 C 並附帶警示,然後在「行動」前停下。如果系統未經核准就提交報價,那就是跨越了設計上不該允許的邊界。
何時不該使用 Agent
自主性光譜不是一條「從差到好」的進度條。有些情況下,低自主性才是對的。
簡單查詢。 使用者問「Oak Street 42 號掛牌價多少?」一次 API 呼叫加一個格式化回應就夠了。為一個單步驟任務啟動 agent 迴圈去規劃、推理、反思?不只浪費算力,還多了不必要的故障面。
工具不夠可靠時的高風險行動。 如果唯一的分區資料來源不可靠或已過時,讓系統根據它自動調整推薦就很危險。薄弱工具加高自主性,等於自信滿滿的錯誤。
固定流程就能完成的任務。 從三筆 MLS 房源產生標準比較報告,是理解透徹、可以重複的事。固定流程會比每次都重新規劃的 agent 更快、更便宜、更可預測。
法規或合規情境。 有些領域要求決策流程的每一步都必須事先設定好,可供稽核。動態選路徑的 agent 可能在架構上就跟這些要求不相容——不管它決策多好都一樣。
通則:用能可靠完成任務的最低自主性層級。自主性是工具,不是目標。
常見的失敗模式
系統在較高自主性層級運作時,有幾種失敗會一再出現。先認識它們,設計和除錯時才知道從哪下手。
錯誤的工具呼叫。 系統替子任務選了不對的工具。拿分區問題去問學區 API,或送了格式錯的請求給房貸計算器。這不是什麼抽象的推理失敗——系統可能有個合理的計畫——問題出在計畫跟可用工具之間的錯配。工具描述和輸入 schema 得夠精確,模型才選得準。
迴圈(Looping)。 系統在沒有進展的情況下重複同一個動作。查 MLS 資料庫、拿到意外的回應格式、用同樣的查詢重試、拿到同樣的回應、再重試。沒有迴圈偵測或最大迭代次數限制的話,這可以跑到天荒地老——燒資源卻什麼有用的都沒產出。
過早總結(Premature synthesis)。 系統還沒跑完所有子任務就急著給答案。三間房產才查了兩間的學區,就當三間都查完了來寫比較報告。輸出看起來完整,其實缺了資料。這通常發生在模型的訓練傾向偏好「生成流暢結論」勝過「追蹤任務完成度」的時候。
遺漏上報(Missing escalation)。 系統碰到超出能力或權限的狀況卻沒標出來。它發現了房產 B 的待決分區重劃,但只當小註腳,而不是當成應該改變推薦結構的重大發現。系統需要上報——把發現醒目呈現並請人介入——但設計裡缺了觸發機制。
這些不是假設性的邊緣案例。跑 agent 系統的實務經驗一再顯示,工具選錯、無限迴圈和過早終止是最常見的失敗類別。Yao 等人提出的 ReAct 框架(2022)——交錯推理步驟與行動步驟——設計目的之一就是緩解過早總結:強制模型在產生下一個動作前,先對觀察結果做明確推理。不過這個框架沒有消除這些失敗,只是讓系統更結構化,使失敗更容易被觀察和除錯。
本文未涵蓋的內容
這篇不講 agent 迴圈在機制面怎麼運作——工具呼叫怎麼格式化、觀察結果怎麼回饋給模型、停止條件怎麼評估。那些實作細節很重要,但屬於另一個層次。
不涵蓋進階檢索策略、embedding 模型或向量資料庫。那些在第 0-3 篇已經引介,主系列會進一步展開。
不主張 agent「從經驗中學習」——也就是在使用過程中更新自身參數。有邊界的 agent 發現分區標記後調整計畫,它是在當前上下文中回應新資訊,不是在重新訓練自己。這個區分很重要:工作階段內的調適是系統行為,跨工作階段的學習是訓練行為。混淆了會讓人對已部署系統的能力產生不切實際的期待。
也不主張「自主性越高越好」。光譜框架的重點就在:正確的自主性層級是設計決策,不是終點。
接下來的方向
你已經看到一個不動產助理怎麼從簡單問答,演進到能規劃、能調適、知道何時該踩煞車的有邊界 agent。自主性光譜、工具使用(tool use)、記憶層、核准邊界(approval boundary)——這些就是我們思考這類系統的概念詞彙。
那麼,當所有概念匯聚在一個真實產品裡,實際上會長什麼樣?下一篇會看一個完整的系統:檢索、工具使用、記憶和核准邊界協同運作——不是各自獨立的功能,而是一套真正整合的架構。
本文引介的關鍵術語
術語 — 定義
助理(Assistant, AI) — 一種互動模式,系統協助使用者執行任務,通常回應明確指令,並在各步驟之間等待指示
工作流程(Workflow) — 一個預先定義的步驟序列,控制邏輯固定在程式碼中;模型在有限步驟內運作,但不選擇序列
Agent(AI Agent) — 一個能夠規劃自身行動序列、選擇工具,並在定義的邊界內調適新資訊的系統
自主性光譜(Autonomy spectrum) — 一個五層級框架(固定流程、路由式工作流程、輔助式、有邊界 agent、長時間執行的自主系統),用於描述系統對自身執行的掌控程度
API — Application programming interface(應用程式介面)——一種結構化的方式,讓一個程式透過請求資料、傳送指令或觸發動作來與另一個程式溝通
工具使用(Tool use) — 語言模型判斷何時呼叫外部服務以及如何格式化請求的能力
對話記憶(Conversation memory) — 在對話的多個回合中保留的資訊,例如使用者偏好或已陳述的條件限制
任務狀態(Task state) — 追蹤進行中工作流程的結構化資訊——已完成的、尚未完成的,以及可用的中間結果
持久知識(Durable knowledge) — 外部系統(資料庫、記錄)中的資訊,獨立於任何對話或任務工作階段而持續存在
核准邊界(Approval boundary) — 決定系統能夠描述、建議或行動的架構決策點——以及何處需要人工核准
描述/建議/行動(Describe / Recommend / Act) — 系統輸出的三層級階層,依現實世界後果遞增、人類掌控遞減排序
參考文獻與延伸閱讀
Yao, S., Zhao, J., Yu, D., Du, N., Shafran, I., Narasimhan, K., & Cao, Y. (2022). "ReAct: Synergizing Reasoning and Acting in Language Models." *arXiv preprint arXiv:2210.03629*. Introduced the framework for interleaving reasoning traces with tool actions in language model agents. arxiv.org/abs/2210.03629
Schick, T., Dwivedi-Yu, J., Dessì, R., Raileanu, R., Lomeli, M., Hambro, E., Zettlemoyer, L., Cancedda, N., & Scialom, T. (2023). "Toolformer: Language Models Can Teach Themselves to Use Tools." *NeurIPS 2023; arXiv:2302.04761*. Demonstrated that language models can learn to invoke external tools when their own outputs would be unreliable. arxiv.org/abs/2302.04761
National Institute of Standards and Technology. (2023). *AI Risk Management Framework (AI RMF 1.0)*. NIST AI 100-1. Provides governance principles for AI systems, including proportional oversight as autonomy increases. nist.gov/itl/ai-risk-management-framework
Zaharia, M., Khattab, O., Chen, L., Davis, J. Q., Miller, H., Potts, C., Zou, J., Carbin, M., Frankle, J., Rao, N., & Ghodsi, A. (2024). "The Shift from Models to Compound AI Systems." *Berkeley AI Research Blog*. Argues that state-of-the-art AI results increasingly come from multi-component systems rather than monolithic models. bair.berkeley.edu/blog/2024/02/18/compound-ai-systems
Kapoor, S., Stroebl, B., Siegel, Z. S., Nadgir, N., & Narayanan, A. (2024). "AI Agents That Matter." *Princeton University; arXiv:2407.01502*. Analyzes agent evaluation methodology, documenting how benchmarking shortcomings -- including cost-accuracy trade-offs, reproducibility problems, and overfitting to benchmarks -- obscure real-world agent performance. arxiv.org/abs/2407.01502
Huang Tzu Lin
With over five years in autonomous robotics, there's a strong passion for incorporating cutting-edge technologies and innovative approaches. Dedicated to transforming the latest research and insights into practical applications, this journey pushes the limits of possibility.
相關文章
訂閱最新資訊
將最新技術洞察直接送到您的信箱。