大型語言模型到底在做什麼
閱讀順序
LLM Foundations
上一章
尚無可用文章
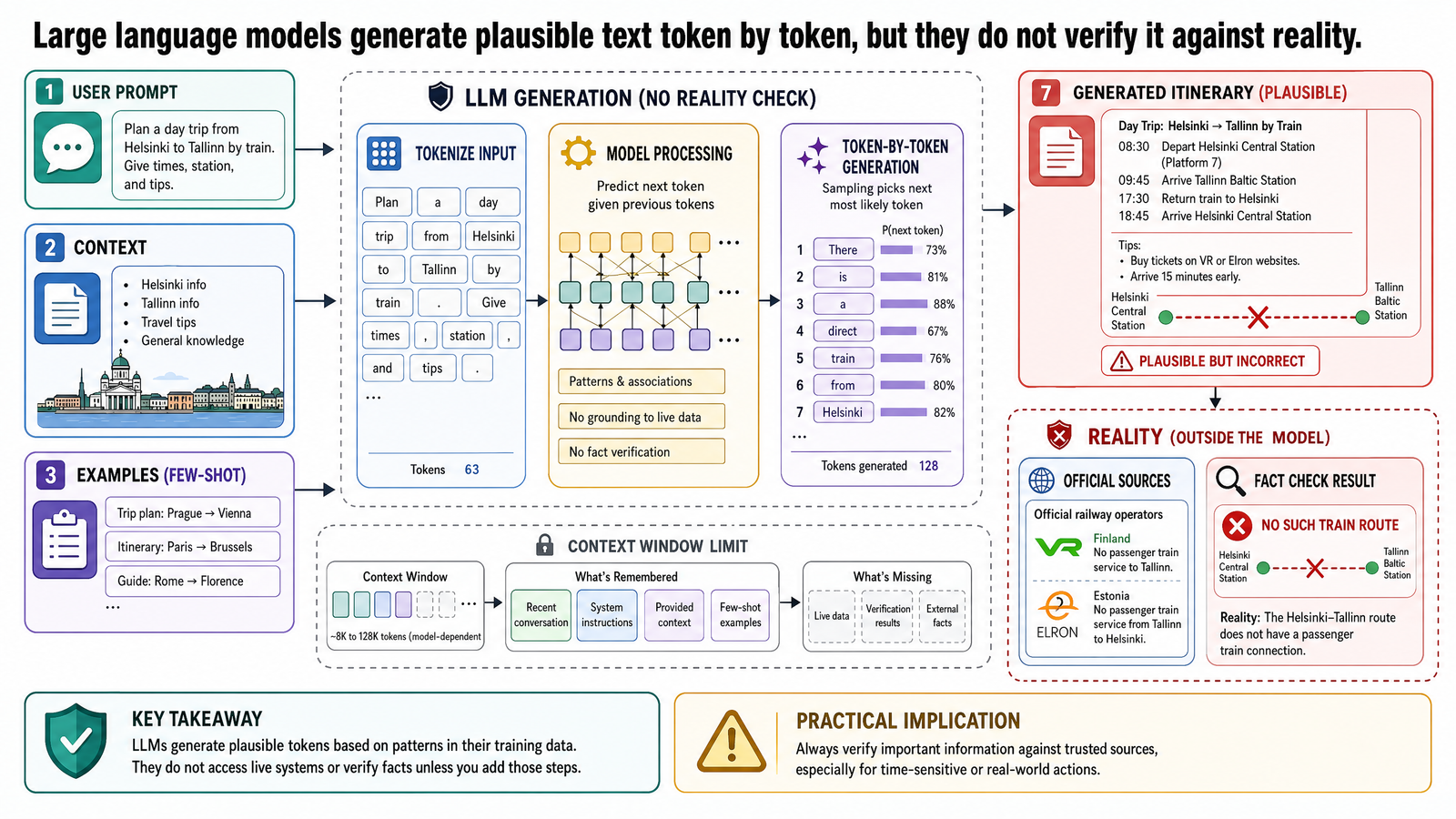
你在某個 AI 應用裡打了一段話,幾秒鐘後螢幕上跑出好幾段文字——流暢、有條理,讀起來像某個很懂的人寫的。這種事現在大家都習以為常了。但如果你打算在這些系統上面蓋東西,真正該理解的是:從你按下送出到那些文字出現,中間到底發生了什麼。
這篇文章會用一個例子帶你看 LLM(大型語言模型,Large Language Model)的核心運作方式。重點不是要讓你覺得這技術多神,而是幫你建立一個準確的心智模型——理解它怎麼運作,這樣它做對的事和出錯的事,你都不會感到意外。

令人印象深刻的輸出
假設你對一個通用 AI 助理丟了這樣一句話:
「幫我規劃一趟赫爾辛基(Helsinki)之旅。」
模型吐回一份超詳細的行程表。第一天:到了之後先去克盧維(Kluuvi)的飯店 check in,走路去參議院廣場和赫爾辛基大教堂,午餐到 Ravintola Sea Horse 吃經典芬蘭料理。第二天:搭渡輪去芬蘭堡(Suomenlinna)要塞,探索島上的歷史遺跡,晚上到 Löyly 體驗芬蘭桑拿。第三天:波爾沃(Porvoo)一日遊——從赫爾辛基中央車站搭 VR 火車,大概一小時,去逛老城區的紅色木造倉庫和中世紀教堂。第四天:去哈卡涅米市場大廳(Hakaniemi Market Hall)和設計區(Design District)。後面還有餐廳名字、交通怎麼走、什麼時候去,全都列好了。
文字很順、結構很清楚、語氣也很有把握。如果你沒去過赫爾辛基,看起來就像專家級的旅遊建議。
破綻
但如果去查證呢?
模型建議從赫爾辛基中央車站搭 VR 火車去波爾沃。但根本沒有這條路線——赫爾辛基到波爾沃沒有直達火車,唯一實際的選擇是從坎皮巴士站(Kamppi)搭巴士,大約 55 分鐘。模型還很有把握地說六月下旬可以「體驗永晝」。但赫爾辛基位於北緯 60.2 度,在北極圈以南,仲夏確實有大約 19 小時的日照,但太陽還是會下山;真正的永晝只有在拉普蘭(Lapland)——北緯 66.5 度以北——才看得到。行程表還推薦十月的某個晚上觀賞北極光。但在赫爾辛基看到極光很罕見,需要 Kp 4 以上的強烈地磁暴;想穩定看到極光得往北去拉普蘭。
這些錯誤來自 LLM 輸出中已被記錄的真實模式。部分周邊細節為了表達清楚做了簡化,但事實性的錯誤是真的,都可以查證。
這些錯誤不是隨機亂冒的,它們有一個共通點:模型產出的文字在統計上「長得像」一份赫爾辛基旅遊指南,但它從頭到尾沒有拿任何一個說法去跟現實世界核對過。要理解為什麼會這樣,我們得先理解語言模型到底是什麼東西。
什麼是神經網路(概念層次)
LLM 建構在一種叫做神經網路(neural network)的軟體系統上。這篇文章裡,我們不去管神經網路內部的數學,重點是它做的事:從資料裡學模式(pattern)。
你可以這樣想:模型在訓練的時候,把每一篇關於赫爾辛基的旅遊部落格、餐廳評論、城市指南、論壇貼文、Wikipedia 文章都讀過了——幾百萬篇。它從這些文字裡吸收了大量模式:哪些字常常出現在一起、什麼句型會接在什麼問題後面、一份「五天行程」通常長什麼樣。它學到「傳統芬蘭美食」後面常常會接某些類型的餐廳名、芬蘭料理術語、街區名稱。
但它從來沒去過赫爾辛基。沒有感官經驗,沒有吃飯的記憶,也沒辦法查巴士時刻表或確認某條火車路線到底存不存在。它學到的是關於赫爾辛基的文字在統計上的「形狀」,不是這座城市本身。
「訓練」是什麼意思
模型學這些模式的過程叫訓練(training)。訓練的時候,模型接觸大量文字資料,一邊不斷調整自己的內部結構,讓自己在一件事上越來越強:預測接下來會出現什麼文字。
訓練資料通常涵蓋網路上很大範圍的東西——Common Crawl 這類網頁爬取資料、數位化書籍、Wikipedia、學術論文、公開的程式碼、新聞、論壇討論。具體組成每個模型都不太一樣,而且通常不會完全公開。關鍵在規模——幾千億到幾兆個字詞——以及這帶來的後果:模型的知識全部來自這些文字,凍結在訓練結束的那一刻。
這就是訓練截止點(training cutoff)。如果一間餐廳是在訓練資料收集完之後才歇業的,模型單靠權重本身不可能知道。產品可以在模型外圍接上檢索、瀏覽或資料庫工具,但基礎生成步驟仍然依賴訓練時學到的模式,除非周邊系統提供新的證據。
什麼是「參數」
訓練的時候,模型會調整幾十億個內部數值,把學到的模式編進去。這些數值叫參數(parameters),也就是神經網路的學習權重(learned weights)。
參數不是一個事實資料庫。它不會像資料表一樣存「X 餐廳在 Y 地址」這種東西。參數編碼的是壓縮過的統計關係:訓練資料裡哪些字詞、片語、結構常常一起出現。當模型後來要寫關於赫爾辛基餐廳或火車路線的文字,它是從這些壓縮的模式裡「重建」出聽起來合理的內容,不是從某個查找表裡撈資料。
現代模型的規模很大,從數十億到數千億參數都有;有些混合專家模型(mixture of experts)會公布更大的總參數量,但每個 token 只啟用其中一部分。大多數商用模型——GPT-4、Claude、Gemini——的確切數字都沒有完全公開。重點不是具體數字,而是較大的模型通常能編碼更細緻的模式,代價是更多運算、記憶體和訓練資料。
什麼是 Token
語言模型不是一個字元一個字元讀的,也不是一整句一整句讀的。它操作的是一種中間切分單位,叫 token。
Token 就是模型當成一個處理單位的一小段文字。常見的短詞通常自己就是一個 token;比較長或少見的詞會被拆成好幾個 token;標點符號和空格也算。具體怎麼切,看模型的分詞器(tokenizer)怎麼設計——它是一個把原始文字轉成 token 序列的前處理步驟。
粗略估一下:「Helsinki」看分詞器不同,大概一到兩個 token。「5-day itinerary」大約三到四個。「Take the VR train from Helsinki Central Station to Porvoo」這種句子大約十到十二個 token。
重點是:模型用 token 序列讀你的輸入,也一次只吐出一個 token。它做的所有事——從看懂你的問題到生成回答——都在這個逐 token 的框架裡發生。
什麼是「推論」
訓練只做一次(或模型更新時再跑一輪)。訓練完之後,參數就固定了。你丟提示進去、模型生成回應,這個過程叫推論(inference)。推論就是拿訓練好的模型去處理新的輸入。模型在推論時不會學到任何新東西——它只是把訓練時學到的模式,套在你的輸入上來產出結果。
這個區別很重要,因為它破解了一個常見的誤會。你跟 AI 助理聊天的時候,並不是在訓練它。你的提示和它的回應不會改變模型的參數。回答你赫爾辛基問題的那個模型,跟回答下一個使用者完全不同問題的模型,是同一個模型、同一組參數。
什麼是「生成式」
模型產出赫爾辛基行程表的過程叫生成(generation),這也是為什麼這類系統叫生成式模型(generative model)。生成的原理是下一個 token 預測(next-token prediction):模型看目前所有的 token(你的提示加上它已經生成的部分),預測下一個 token 的機率分布,從裡面選一個,加到序列裡,然後重複。
就是這樣。整份行程表——每一個餐廳名、每一條交通指引、每一個逐日標題——都是一次一個 token 蹦出來的。每個 token 都是根據參數裡編碼的統計模式,看前面所有內容選出來的。
下一個 token 預測這個概念,在原始的 Transformer 架構論文("Attention Is All You Need," Vaswani et al., 2017)裡就有了,後來生成式預訓練的研究持續在這個基礎上推進。GPT 這個縮寫本身就把事情講完了:Generative Pre-trained Transformer——生成式的(產出文字)、預訓練的(在你用之前就學好參數了)、建構在 Transformer 架構上。
理解「生成就是下一個 token 預測」,模型的很多優勢跟失效模式就都說得通了。
為什麼會產生幻覺
回到赫爾辛基行程表。模型在一日遊的指引裡寫了「從赫爾辛基中央車站搭 VR 火車去波爾沃」。為什麼?
因為前面的上下文——一段講赫爾辛基一日遊的文字——之後,「搭 VR 火車從赫爾辛基中央車站出發」這樣的序列在統計上很合理。模型讀過幾千篇提到芬蘭鐵路旅行的文章,學到 VR(芬蘭國鐵)從赫爾辛基中央車站發車,也學到波爾沃是熱門的一日遊目的地。每個單獨的事實都是對的,但模型把它們組裝成了一條根本不存在的路線——赫爾辛基到波爾沃沒有直達火車。
它並沒有去查這條路線存不存在——它也做不到。沒有驗證機制、沒有 VR 路線資料庫、沒辦法連上路線查詢系統、也沒辦法確認兩個車站之間到底有沒有鐵路服務。它根據學到的模式預測了下一個 token,而那些 token 拼成了一條聽起來合理、但實際上不存在的交通指引。
這種失效模式叫幻覺(hallucination):模型產出了流暢又自信、但事實上不正確的文字。這個詞值得精確理解。模型不是在說謊——說謊代表有意圖、知道真相。它也不是在隨意推測——輸出確實是被真實的統計模式所塑造的。它做的就是它被訓練來做的事:預測可能的下一個 token。問題在於,「統計上可能的文字」跟「事實上準確的文字」是兩回事。
幻覺不是那種可以修一修的 bug,它是生成機制的直接結果。一個靠預測「接下來可能出什麼字」來產出內容的系統,有時就是會產出可能但錯誤的文字。具體的事實性陳述特別危險——專有名詞、日期、時刻表、地址——因為模型壓縮的統計模式,沒辦法保留那種精確度。
訓練截止點問題
永晝的說法揭示了另一個相關但不同的問題。模型的訓練資料裡有大量「芬蘭與永晝」的文字,這個關聯性強到模型能信心十足地重現——但它沒有編碼足夠的地理精度去區分永晝需要北極圈以上的緯度,而不只是「芬蘭」。就算訓練資料裡有這個區別,壓縮的統計模式也沒辦法可靠地保留它。模型的知識凍結在訓練截止點,那個日期之後發生的事——餐廳收了、交通路線改了、地標在整修——模型全都看不到。
這不是模型變大就能解決的。參數多十倍的模型,還是不可能知道訓練資料收完之後發生的事。訓練截止點是結構性的限制,不是效能問題。
統整核心詞彙
到這裡,核心術語都定義完了。用赫爾辛基的例子把它們串起來看:
一個神經網路在訓練的時候從文字裡學模式,產出幾十億個參數——編碼壓縮統計關係的學習權重。你送出提示的時候,系統做推論:把你的輸入處理成一串 token 序列,用下一個 token 預測來生成回應,根據參數裡的統計模式選每個 token。當這些模式產出聽起來對但事實上錯的文字,就是幻覺。當事實在訓練資料收完之後已經變了,模型就撞上訓練截止點。
每個術語都是在描述同一個底層過程的一個面向。基礎模型裡面沒有獨立的「知識檢索」步驟、沒有「事實驗證」模組、也沒有「信心評估」機制。有的就是一個文字預測引擎,一次一個 token 地產出統計上可能的接續內容。
這在實務上意味著什麼
赫爾辛基行程表把這項技術的兩面看得很清楚。
模型強的地方。 它幾秒鐘就生出了一份結構完整、文字流暢的旅行計畫。整體格式沒問題。一般性的知識——芬蘭堡值得去、波爾沃是熱門一日遊、芬蘭桑拿文化是旅遊體驗的核心——都是準確的,因為這些東西在訓練資料裡有大量佐證,統計模式能可靠地重現。模型在整合、組織結構、產出符合特定文類慣例的文字上,表現很好。
模型不可靠的地方。 具體的事實——交通路線、地理精確度、當前商業資訊、任何需要區分相關但不同事實的東西——就是下一個 token 預測會出包的地方。模型沒有辦法區分「一個剛好對應當前事實的模式」和「一個產出聽起來合理但其實是虛構的模式」。
如果你要在這些系統上面蓋應用,這個區別是實務層面的,不只是理論。它告訴你哪裡可以信任模型的輸出,哪裡需要額外的機制——驗證、從當前資料來源檢索、人工審查——來確保可靠性。
常見的誤解
如果不懂下一個 token 預測的機制,很容易對語言模型產生幾種誤解。
誤解:模型「知道」事情
模型不是用資料庫的方式在存知識。它編碼的是統計模式,這些模式能重現出類似知識的文字。如果某個事實有大量佐證(芬蘭的首都是赫爾辛基),模式夠強,輸出通常是對的。但比較冷門或最近才變的事實,模式可能只會產出「聽起來對」的東西。
誤解:模型「理解」你的問題
模型把你的輸入當 token 序列處理,生成統計上可能的接續內容。這算不算「理解」,是一個哲學問題,我們這裡不用管它。實務上重要的是:模型會用任何真正有理解力的系統不會犯的方式出錯——比方說,在你要可靠推薦的時候,信心十足地推薦一條根本不存在的火車路線。
誤解:出錯代表模型「很差」
幻覺不是模型表現差的證據,而是生成機制的可預期結果。一個從不幻覺的模型,要嘛得有完美的事實知識(有限的訓練資料和截止點下不可能),要嘛得有可靠的內部機制區分事實和虛構(單靠下一個 token 預測辦不到)。想通這一點,思路就能從「模型犯錯了」轉向「這個任務需要的不只是模型本身」。
誤解:更大的模型不會產生幻覺
更大的模型在有充分佐證的事實上確實比較少幻覺,因為它們能用更高的保真度編碼模式。但它們還是會幻覺,特別是具體陳述、近期事件、訓練資料裡代表性不足的領域。規模提升能降低某些錯誤的頻率,但消除不了結構性的成因。
本文不涵蓋的內容
這篇不講怎麼減輕幻覺或提高 LLM 輸出的可靠性。那些是系統設計的問題——牽涉檢索、grounding、驗證、人工監督——後面的文章會處理。
也不講 Transformer 內部的數學。注意力機制(attention mechanism)、位置編碼(positional encoding)、層級架構(layer architecture)都是重要的工程主題,但在這篇討論的層次上,不需要它們也能理解語言模型的運作。
也不講 agent、工具(tool)或多步驟 AI 系統。那些概念建立在這裡打的基礎上,但屬於另外的架構概念。
下一步
模型從一句話就生出了一份詳盡的赫爾辛基行程表。結構上很厲害,但具體細節不可靠。這個落差——流暢的生成能力跟事實準確性之間的落差——是任何在語言模型上蓋應用的人都得面對的核心設計挑戰。
下一個問題在輸入端。模型從一句話就做出了這份行程表。如果你給它更好的指示、更多上下文,或者要求它一步一步想呢?那就是文章 0-2 要講的事。
參考資料與延伸閱讀
Vaswani, A., Shazeer, N., Parmar, N., et al. (2017). "Attention Is All You Need." *Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS).* 介紹 Transformer 架構的奠基性論文,現代大型語言模型皆以此為基礎。 arXiv:1706.03762
Radford, A., Narasimhan, K., Salimans, T., and Sutskever, I. (2018). "Improving Language Understanding by Generative Pre-Training." *OpenAI.* 最初的 GPT 論文,確立了語言模型的生成式預訓練方法。 OpenAI Research
Bender, E. M., Gebru, T., McMillan-Major, A., and Shmitchell, S. (2021). "On the Dangers of Stochastic Parrots: Can Language Models Be Too Big?" *Proceedings of FAccT 2021.* 對大型語言模型風險的批判性檢視,包括訓練資料組成以及流暢度與理解力之區別的討論。
Ji, Z., Lee, N., Frieske, R., et al. (2023). "Survey of Hallucination in Natural Language Generation." *ACM Computing Surveys, 55(12).* 語言模型幻覺的全面綜述,涵蓋分類法、成因及緩解方法。 DOI:10.1145/3571730
Shanahan, M. (2024). "Talking About Large Language Models." *Communications of the ACM, 67(2).* 對語言模型能做什麼與不能做什麼的嚴謹哲學與技術分析,釐清了常見的擬人化誤歸因。 arXiv:2212.03551
Huang Tzu Lin
With over five years in autonomous robotics, there's a strong passion for incorporating cutting-edge technologies and innovative approaches. Dedicated to transforming the latest research and insights into practical applications, this journey pushes the limits of possibility.
相關文章
訂閱最新資訊
將最新技術洞察直接送到您的信箱。