當 RAG 不夠用時:快取增強生成(CAG)、混合檢索與工作記憶
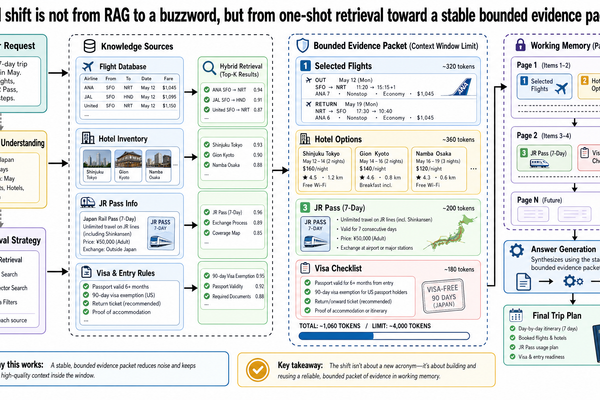
基本的檢索增強生成(RAG)到現在還是多數正式環境系統最常用的基礎模式。語料庫很大、更新頻繁、又需要展示答案來源?檢索依然是最乾淨的起點。不過實務上會碰到一種極限情境——簡單的 RAG 開始力不從心:系統確實找到了正確的文件,但任務現在需要的是針對一組有限的證據持續推理,同時回答同一案件的多次後續追問。
Huang Tzu Lin
Retrieval-augmented generation, cache-augmented generation, hybrid retrieval strategies, memory and state management, and knowledge systems. How AI systems access, manage, and reason over external evidence to produce grounded, reliable outputs.
3 篇文章
基本的檢索增強生成(RAG)到現在還是多數正式環境系統最常用的基礎模式。語料庫很大、更新頻繁、又需要展示答案來源?檢索依然是最乾淨的起點。不過實務上會碰到一種極限情境——簡單的 RAG 開始力不從心:系統確實找到了正確的文件,但任務現在需要的是針對一組有限的證據持續推理,同時回答同一案件的多次後續追問。
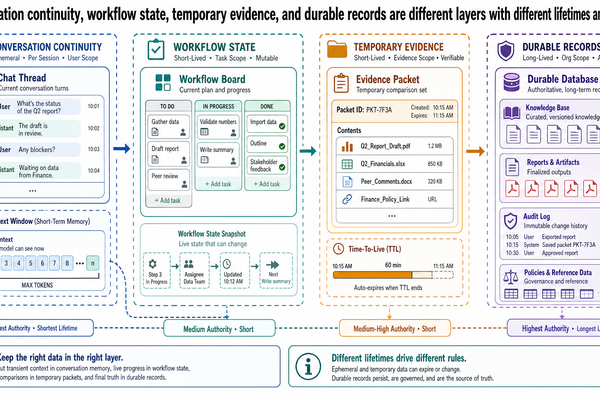
一個為中型旅行社打造的旅遊規劃 Copilot,被問了一個很直接的問題:「這間飯店之前是否在輪椅使用者的無障礙審查中未通過?」
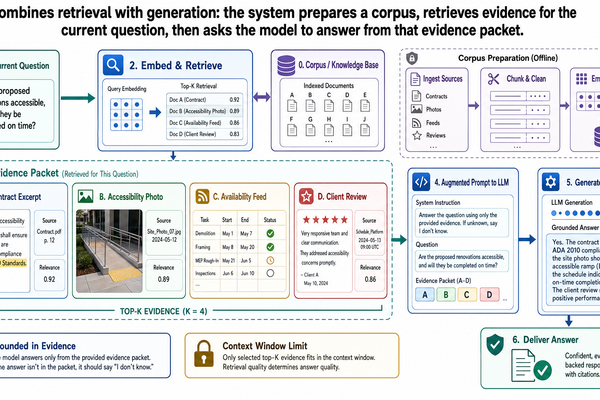
大型語言模型之所以有用,是因為它們能用流暢的語言綜合、解釋和轉化資訊。但一旦我們要求它們處理即時的、私有的,或需要可驗證依據的資訊,它們就變得不可靠。模型在訓練期間可能看過類似的素材,但這不代表它能存取當前任務需要的那份飯店合約、無障礙稽核或客戶回饋記錄。