Why LLMs Need Help — Hallucinations, Grounding, and the Case for Systems
Reading order
LLM Foundations
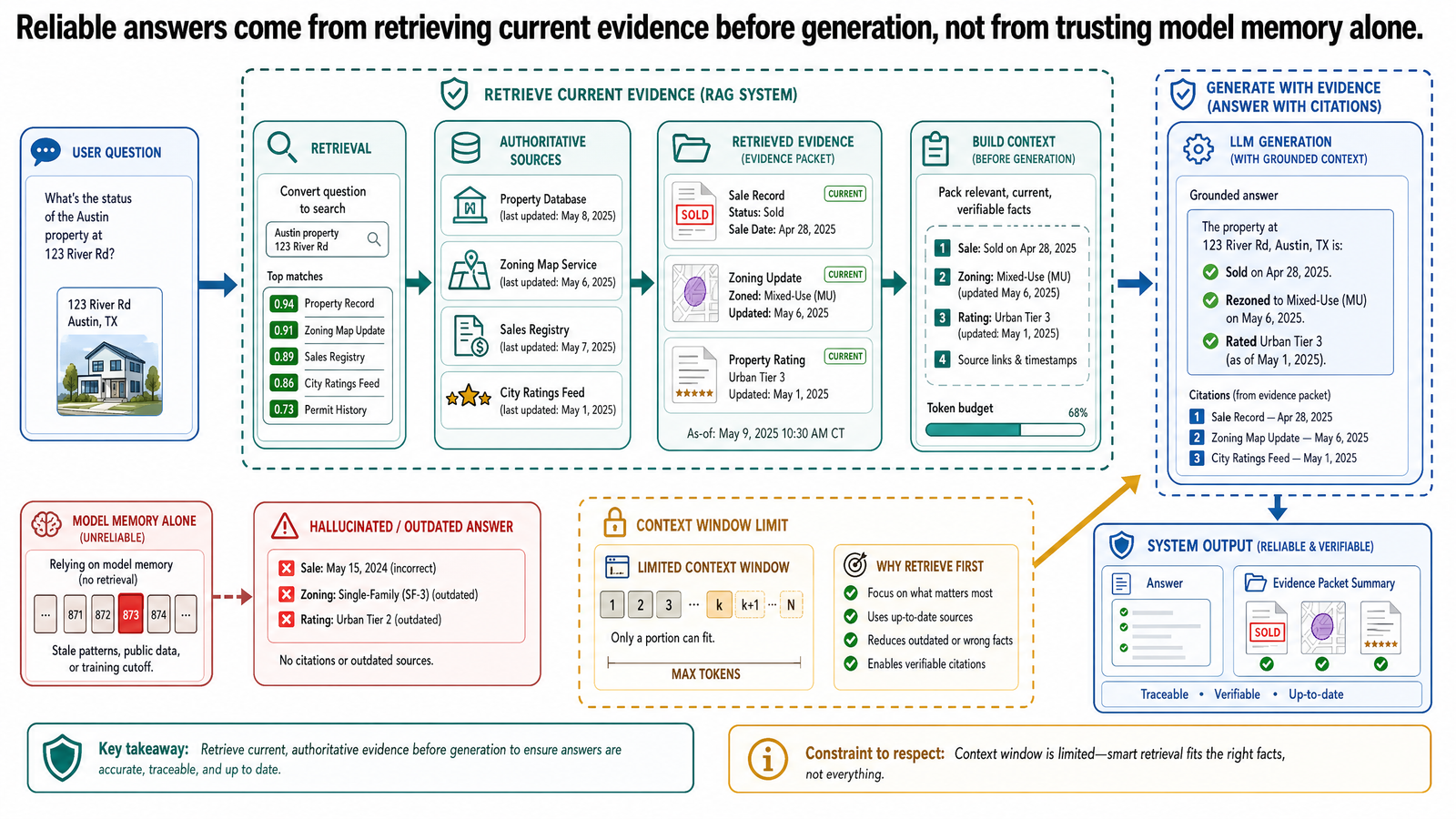
Table of Contents
- The Confident but Wrong Answer
- Why This Happens
- Three Flavors of Failure
- Stale knowledge
- Private and controlled data
- No source attribution
- What Grounding Means
- How Retrieval Works at the Simplest Level
- Embeddings — Text as Numbers, Similarity as Distance
- What a Vector Database Does
- When the System Should Say "I Don't Know"
- Why Reliable AI Is a System-Design Problem
- Common Misconceptions
- Misconception: Hallucination is a quality problem that better models will solve
- Misconception: Grounding eliminates hallucination
- Misconception: If you use RAG, you automatically get citations
- What This Post Is Not
- Where This Leads
- Key Terms Introduced
- Sources and Further Reading
Large language models produce fluent, confident text. That confidence is the problem. A model can sound authoritative about a property listing that no longer exists, a tax rate that changed last quarter, or a school rating from three years ago. It has no mechanism to check. It was not designed to check. It was designed to predict the next plausible token given its training data, and plausibility is not accuracy.
This post explains why that gap exists, what it means in practice, and why reliable AI requires building systems around the model rather than expecting the model to be reliable on its own.
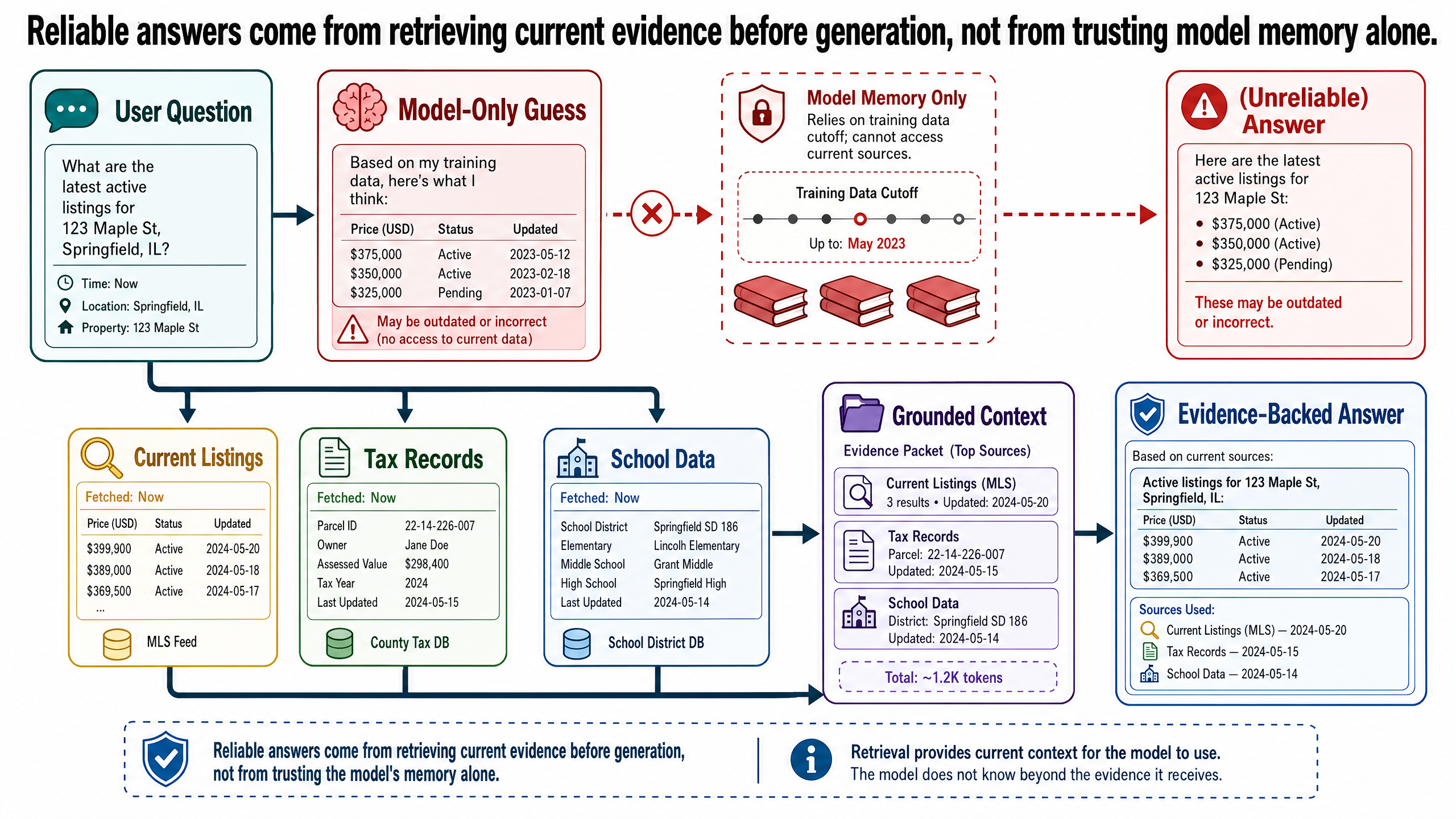
The Confident but Wrong Answer
A first-time buyer in Austin asks an AI assistant:
Find me a 2-bedroom apartment under $400K in Austin with good schools nearby.
The assistant responds with three listings. Each one includes an address, a price, a school rating, neighborhood details, and an estimated monthly property tax. The response is well-organized, specific, and reads like a knowledgeable real estate agent wrote it.
Here is what is actually wrong:
Listing one was sold eight months ago. It is no longer on the market.
Listing two cites a school rating of 8 out of 10. That rating is from 2022. The current rating is 6.
Listing three describes the neighborhood as zoned for single-family residential. The zoning was changed to mixed-use in 2024.
The property tax estimate for all three uses a rate that does not match the county's current published rate.
None of these errors are random. Every one of them is a plausible-sounding detail drawn from training data that was accurate at some point in the past. The buyer almost made financial decisions based on this information. That is the real cost of a confident but ungrounded answer.
Why This Happens
The instinct is to treat these errors as quality problems. If the model were better trained, or if the prompt were more carefully written, maybe it would get the listings right. That instinct is wrong. The problem is structural.
Recall from earlier posts that a large language model works by predicting text based on patterns learned during training. Its parameters encode statistical relationships from the training corpus. When you ask about apartments in Austin, the model does not search a database. It generates text that is statistically consistent with what apartment listings in Austin looked like in its training data.
This means three things:
The model has no access to current facts. Its knowledge is a snapshot. Training data has a cutoff date. Anything that changed after that date — a sold listing, a revised tax rate, a rezoned parcel — is invisible to the model.
The model has no verification mechanism. It cannot check whether listing #4821 is still on the market. It has no way to query a county records database. It produces output; it does not fact-check output.
The model has no concept of "I made this up." From the model's perspective, there is no difference between generating a factual statement and generating a plausible-sounding one. Both are sequences of tokens that score well under the model's learned probability distribution. The term for this in AI is hallucination: the model generates content that sounds correct but is not grounded in any verifiable source.
Hallucination is not a bug that will be fixed in the next model version. It is a structural property of how language models generate text. Better models hallucinate less frequently on well-represented topics, but no model architecture based on next-token prediction can guarantee factual accuracy, because factual accuracy requires access to external ground truth that the model does not have.
Studies on hallucination rates across large language models consistently find that even state-of-the-art models produce fabricated content at non-trivial rates, particularly on questions involving specific facts, numbers, or recent events. A survey by Huang et al. (2023) catalogued hallucination types across dozens of models and found that factual fabrication remains a persistent challenge regardless of model scale (Huang et al., "A Survey on Hallucination in Large Language Models," arXiv:2311.05232).
Three Flavors of Failure
The Austin example illustrates three distinct categories of failure, and each one has a different root cause.
Stale knowledge
The sold listing and the outdated school rating are failures of currency. The model's training data included those facts at some point, but the world has moved on. Property markets, school ratings, tax rates, and zoning designations change constantly. A model trained on data from even six months ago will have outdated information about any domain where facts change regularly.
This is not a solvable problem through more training. Retraining a large model is expensive and slow. Even if you retrained weekly, there would always be a gap between the model's knowledge and the current state of the world.
Private and controlled data
The MLS (Multiple Listing Service) database that real estate agents use is not public training data. County tax records, while technically public, are often behind portals that were not included in the model's training set. School rating databases are maintained by specific organizations with their own update schedules.
Even if the model's training data were perfectly current, it would still lack access to these private or controlled data sources. The information exists, but not inside the model's parameters.
No source attribution
The model says "the average home price in this ZIP code is $385K." That may or may not be true. But even if it happens to be correct, there is no way to verify it from the model's output alone. There is no citation, no timestamp, no link to a source. The user has no basis for evaluating the claim except the model's confidence, which is uniform regardless of accuracy.
This absence of source attribution is not just inconvenient. In domains where decisions have financial, legal, or health consequences, an unsourced claim is operationally useless. A real estate professional cannot tell a client "the AI said so" as a basis for a $400,000 purchase.
What Grounding Means
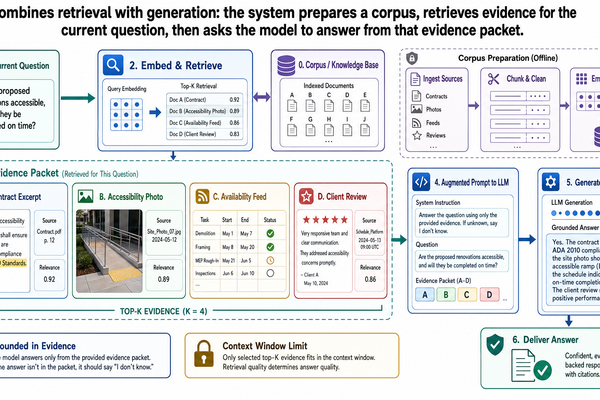
The solution to these three problems has a name: grounding. Grounding means connecting the model's output to verifiable external information before the answer is generated.
Instead of asking the model to recall what it knows about Austin apartment listings, a grounded system does something different:
It looks up current listings in the MLS database.
It checks the county tax assessor's published rate.
It retrieves the current school rating from the rating provider's database.
It passes this verified information to the model along with the user's question.
The model generates its response based on the retrieved facts, not its training data.
The principle is straightforward: check the source first, then answer. Do not rely on the model's memory of what apartment listings looked like in its training data. Go get the actual data and hand it to the model as context.
Grounding does not eliminate hallucination. The model can still misinterpret retrieved information, ignore parts of it, or combine it incorrectly. But grounding dramatically reduces the risk of fabricated facts because the model is working from real data rather than reconstructing approximate patterns from training. The shift is from "generate from memory" to "generate from evidence."
How Retrieval Works at the Simplest Level
Retrieval is the mechanism that makes grounding operational. At its simplest, retrieval is a three-step process:
Search a knowledge source for information relevant to the user's question.
Select the most relevant results.
Pass those results to the model along with the original question so the model can generate an answer based on actual evidence.
In the real estate example, retrieval might mean querying the MLS database for 2-bedroom apartments under $400K in Austin, retrieving the top results, and including those listing details in the prompt to the model. The model then writes its response using the real listing data instead of generating fictional ones.
This pattern was formalized in a 2020 research paper by Lewis et al. titled "Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks." The paper demonstrated that combining a retrieval step with a language model significantly improved accuracy on knowledge-intensive questions compared to using the model alone (Lewis et al., 2020, arXiv:2005.11401). The approach is now widely known as Retrieval-Augmented Generation, or RAG.
The prompt to the model in a basic RAG setup has three parts:
An instruction telling the model to answer based on the provided information.
The retrieved content — the actual data from the knowledge source.
The user's question.
The model sees verified information alongside the question and generates a response grounded in that information. This is fundamentally different from a bare model call where the model has nothing to work with except its parameters.
Embeddings — Text as Numbers, Similarity as Distance
Retrieval requires a way to determine which documents or records are relevant to a question. Keyword matching works for simple cases, but it breaks down quickly. Consider:
A buyer searches for "family-friendly neighborhoods with good transit access."
A listing description says: "Quiet residential area near the light rail station, several parks and elementary schools within walking distance."
These two texts are clearly about the same kind of place. But they share almost no keywords. "Family-friendly" does not appear in the listing. "Transit" does not appear either. A keyword search would miss this match entirely.
This is where embeddings come in. The intuition is straightforward, even if the math behind it is sophisticated.
Think of it this way. Imagine you could place every sentence on a map, where sentences that mean similar things are close together and sentences that mean different things are far apart. On this map, "family-friendly neighborhoods with good transit" and "quiet residential area near light rail with parks and schools" would be neighbors, even though they use completely different words. Meanwhile, "industrial warehouse district with no residential zoning" would be far away on the map.
An embedding is the address of a sentence on that map. Technically, it is a list of numbers — often hundreds or thousands of numbers — that represents the meaning of the text. The process of creating an embedding converts text into this numerical representation using a specialized model called an embedding model.
The key property is that similar meanings produce similar numbers. Two sentences that mean roughly the same thing will have embeddings that are numerically close together. Two sentences that mean very different things will have embeddings that are far apart. This closeness is measured mathematically and is called vector similarity (because the list of numbers is called a vector in mathematics).
Early work on this idea, such as the Word2Vec model (Mikolov et al., 2013), showed that even individual words could be represented as vectors where relationships were preserved: the vector for "king" minus "man" plus "woman" produced a vector close to "queen." Modern embedding models, such as sentence transformers, extend this to entire sentences and paragraphs, capturing meaning at a much richer level.
For the real estate example, this means a search for "family-friendly with good transit" can match listings described as "near light rail with parks and schools" — not because the words overlap, but because the meanings are close in embedding space.
What a Vector Database Does
If embeddings are addresses on a meaning map, a vector database is the infrastructure that makes that map searchable at scale.
Here is what it does in practice:
Indexing: Every listing description, school profile, neighborhood summary, or other text record is converted into an embedding and stored in the database alongside the original text.
Querying: When a user asks a question, the question is also converted into an embedding using the same embedding model.
Similarity search: The database finds the stored embeddings that are closest to the query embedding — the records whose meaning is most similar to the question.
Return: The matching records (the original text, not just the numbers) are returned and can be passed to the language model as context.
This is what makes retrieval by meaning possible. Instead of matching keywords, the system matches concepts. A query about "affordable starter homes in a safe area" can find listings described as "budget-friendly condos in a low-crime neighborhood" because their embeddings are close together.
Several vector databases are available today — Pinecone (a fully managed service), Weaviate and Chroma (open-source with optional managed hosting), and others. The choice of database matters for production engineering (performance, scaling, cost), but the underlying principle is the same: store text as embeddings, search by meaning, return relevant results.
When the System Should Say "I Don't Know"
Grounding and retrieval reduce the risk of fabricated answers. But what happens when the retrieval step finds nothing relevant? What if there are no 2-bedroom apartments under $400K in Austin in the current MLS data? Or what if the only matches are marginal — a listing at $410K, or a studio apartment rather than a 2-bedroom?
The correct behavior is abstention: the system should acknowledge that it cannot answer rather than generating a plausible-sounding response from nothing. "I was unable to find current listings matching your criteria" is a far more useful response than three fabricated listings that waste the buyer's time and erode trust.
But here is the important caveat: you cannot rely on the model to abstain on its own. Language models are trained to produce helpful responses. Their default behavior is to answer, not to decline. Even when instructed to say "I don't know" if uncertain, models frequently generate answers anyway, especially when the question is in a domain well-represented in their training data.
Reliable abstention requires system design, not just prompting. It means building explicit checks:
Retrieval-score cutoffs: If the similarity scores from the vector database are below a threshold, the system concludes that no sufficiently relevant information was found and routes to an abstention response rather than passing low-quality results to the model.
Confidence thresholds: The system evaluates whether the retrieved information actually answers the user's question, rather than assuming any retrieved content is sufficient.
Coverage checks: If the user asked for three criteria (price, bedrooms, school quality) and the retrieved data only covers one, the system can flag incomplete coverage rather than letting the model fill in the gaps from imagination.
These are architectural decisions. They happen in the system layer around the model, not inside the model itself. A model can be instructed to abstain, but a system can be designed to enforce it.
Why Reliable AI Is a System-Design Problem
Return to the Austin buyer's original question. To answer it reliably, the application needs:
Live MLS access to retrieve current listings (not training-data memories of past listings).
County tax record lookup to verify the actual property tax rate.
School rating API to retrieve current ratings from the authoritative source.
Embedding-based search to match the buyer's natural-language preferences to listing descriptions.
Retrieval-score checks to determine whether the results are good enough to present.
Abstention logic to decline gracefully when the data does not support an answer.
The language model to synthesize the verified information into a clear, helpful response.
The model is one component in that list. It is the component that turns structured evidence into a natural-language answer. That is valuable. But it is not the component that retrieves listings, verifies tax rates, or decides when to say "I don't know." Those responsibilities belong to the system around the model.
This is the core argument of this post: reliable AI is a system-design problem, not a model-selection problem. A stronger model may produce better prose. It will not produce current MLS data. A better prompt may reduce hallucination on some questions. It will not verify a county tax record. These capabilities come from system components designed for those specific jobs.
RAG makes source attribution *possible* because the system knows what documents it retrieved and can present them alongside the answer. But citation *faithfulness* — whether the generated text actually reflects what the cited source says — is a separate problem that requires additional system design: checking that the model's statements are supported by the retrieved evidence, not just adjacent to it. Attribution is an architectural feature. Faithful attribution is an evaluation problem.
Common Misconceptions
Misconception: Hallucination is a quality problem that better models will solve
Hallucination rates decrease with model improvements, but they do not reach zero. Any system that generates text from statistical patterns rather than verified data will occasionally produce plausible-sounding fabrications. The rate may drop, but the structural cause remains. For any application where accuracy matters, architectural mitigation (grounding, retrieval, validation) is necessary regardless of the model.
Misconception: Grounding eliminates hallucination
Grounding reduces the risk of fabricated facts by giving the model real data to work from. It does not eliminate hallucination entirely. A model can still misinterpret retrieved data, overstate weak evidence, or combine facts incorrectly. Grounding changes the failure mode from "invented the data" to "misused the data," which is a significant improvement but not a complete solution.
Misconception: If you use RAG, you automatically get citations
RAG gives the system access to source documents, which makes citation mechanically possible. But the model may generate statements that do not accurately reflect the cited source, or it may blend information from multiple sources in misleading ways. Faithful citation — where the generated text correctly represents what the source actually says — requires explicit evaluation and checking, not just retrieval.
What This Post Is Not
This post is not a RAG implementation tutorial. It does not cover chunking strategies, reranking algorithms, retrieval engineering, or pipeline optimization. Those are engineering topics covered later in the series.
This post also does not cover how embedding models are trained, how vector databases are indexed internally, or how to evaluate retrieval quality. The goal here is vocabulary and motivation: understanding *why* these components exist and *what problem* they solve, so that the engineering details in later posts have a clear foundation.
Where This Leads
Grounding solves the knowledge problem. The model no longer has to guess about apartment listings because the system retrieves real ones. It no longer has to fabricate tax rates because the system looks them up.
But what if the buyer says: "Compare these three properties, check zoning for each, calculate monthly payment at current rates, and tell me which is the best investment"?
That is not a retrieval problem. The system cannot answer it with a single search. It needs to check three separate zoning records, call a mortgage calculator, compare multiple properties along several dimensions, and synthesize a recommendation. That requires planning, tool use, and multi-step decision-making.
That is the subject of the next post.
Key Terms Introduced
Term — Definition
Hallucination — When a model generates content that sounds correct but is not grounded in verifiable information. A structural property of text generation, not a bug.
Grounding — Connecting model output to verifiable external data before generating a response. Reduces but does not eliminate fabrication risk.
Retrieval — Searching external knowledge sources, selecting relevant results, and passing them to the model as context for generation.
Embedding — A numerical representation of text (a list of numbers) where similar meanings produce similar numbers. Enables search by meaning rather than keywords.
Vector similarity — A mathematical measure of how close two embeddings are, used to determine whether two pieces of text have similar meaning.
Vector database — A searchable index that stores text as embeddings and supports similarity search — finding records whose meaning is closest to a query.
Abstention — The system declining to answer when it lacks sufficient verified information. Requires system-level design (score cutoffs, coverage checks), not just model prompting.
RAG (Retrieval-Augmented Generation) — An architecture that combines retrieval from external knowledge sources with language model generation, formalized by Lewis et al. (2020).
Sources and Further Reading
Lewis, P., Perez, E., Piktus, A., Petroni, F., Karpukhin, V., Goyal, N., Kuttler, H., Lewis, M., Yih, W., Rocktaschel, T., Riedel, S., & Kiela, D. (2020). "Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks." *arXiv:2005.11401*. https://arxiv.org/abs/2005.11401 — The foundational paper introducing the RAG framework.
Huang, L., Yu, W., Ma, W., Zhong, W., Feng, Z., Wang, H., Chen, Q., Peng, W., Feng, X., Qin, B., & Liu, T. (2023). "A Survey on Hallucination in Large Language Models: Principles, Taxonomy, Challenges, and Open Questions." *arXiv:2311.05232*. https://arxiv.org/abs/2311.05232 — Comprehensive survey of hallucination types and rates across large language models.
Mikolov, T., Chen, K., Corrado, G., & Dean, J. (2013). "Efficient Estimation of Word Representations in Vector Space." *arXiv:1301.3781*. https://arxiv.org/abs/1301.3781 — The Word2Vec paper that demonstrated word embeddings capture semantic relationships.
Reimers, N. & Gurevych, I. (2019). "Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks." *arXiv:1908.10084*. https://arxiv.org/abs/1908.10084 — Introduced efficient sentence-level embeddings, enabling practical semantic search.
Zaharia, M., Khattab, O., Chen, L., Davis, J. Q., Gu, H., Ghodsi, A., Ratner, A., Jordan, M. I., Liang, P., Stoica, I., & Re, C. (2024). "The Shift from Models to Compound AI Systems." *Berkeley AI Research Blog*. https://bair.berkeley.edu/blog/2024/02/18/compound-ai-systems/ — Argues that state-of-the-art AI results increasingly come from systems of components, not individual models.
Huang Tzu Lin
With over five years in autonomous robotics, there's a strong passion for incorporating cutting-edge technologies and innovative approaches. Dedicated to transforming the latest research and insights into practical applications, this journey pushes the limits of possibility.
Related Posts
Stay Updated
Get the latest technical insights delivered to your inbox.