Grounding with RAG: How AI Systems Retrieve Evidence Before They Answer
Reading order
Building AI Systems
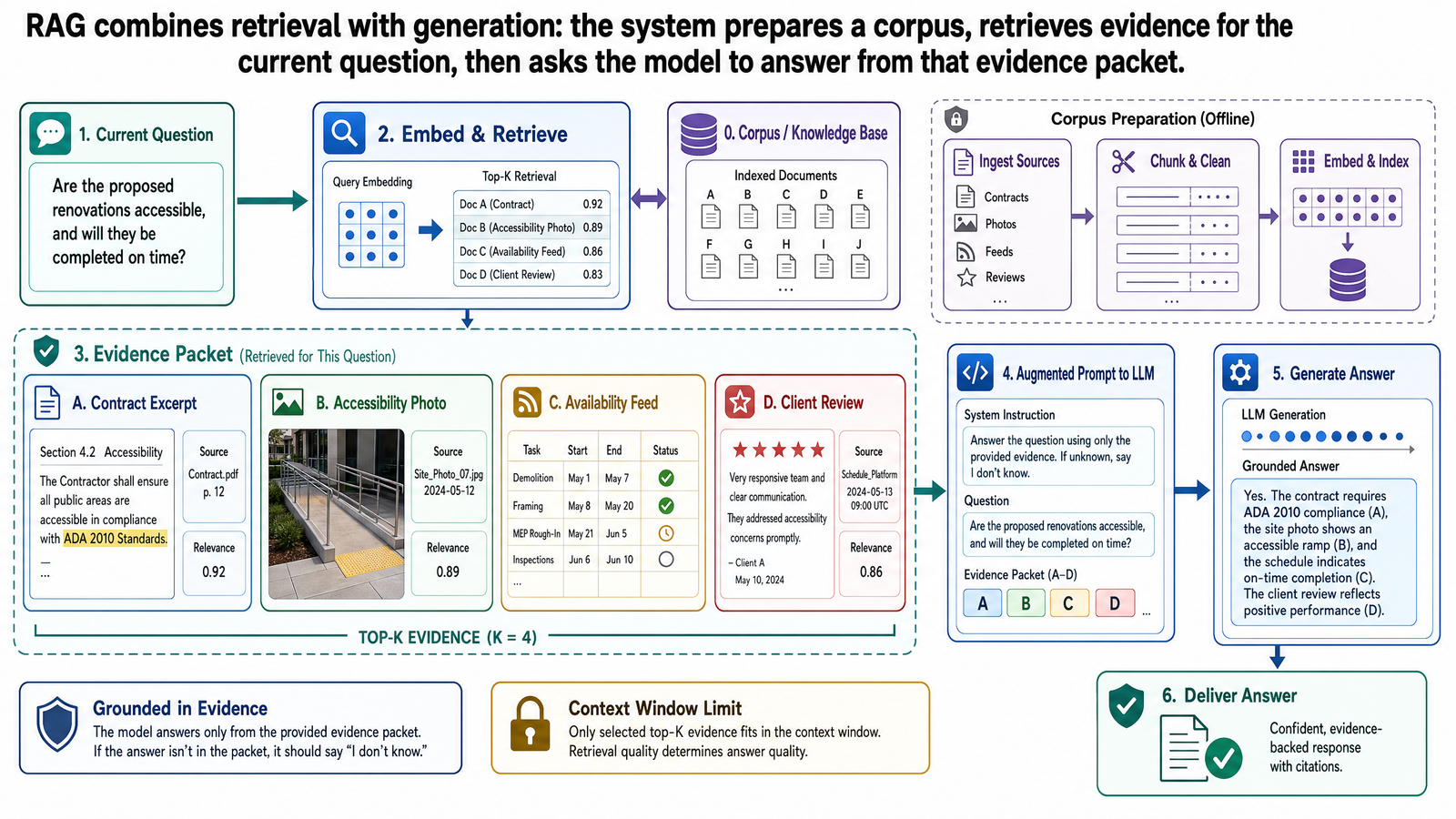
Table of Contents
- Why Model Parameters Are Not Enough
- What RAG Actually Is
- The Basic Retrieval Pipeline
- 1. Build the corpus
- 2. Prepare the documents
- 3. Split content into chunks
- 4. Create embeddings and index them
- 5. Retrieve candidates for the query
- 6. Rerank or filter the evidence
- 7. Generate the answer from the retrieved context
- 8. Return the answer with provenance, warning, or abstention
- What Retrieval Solves
- What Retrieval Does Not Solve
- Evidence-Backed Answers Versus Model-Only Replies
- A Practical System View
- Running Example: Accessible Hotel Lookup
- What This Post Is Not
- Common Misconceptions
- Failure Modes to Watch
- Design Guidance for Engineers and Decision-Makers
- What Comes Next
- Source Notes
Large language models are useful because they can synthesize, explain, and transform information in fluent language. They are unreliable when we ask them to know something current, something private, or something that needs verifiable support. A model may have seen similar material during training, but that is not the same as having access to the exact hotel contract, accessibility audit, or client feedback record that matters for the task in front of it.
This is the core grounding problem. Model parameters are a compressed statistical memory of prior training data. They are not a live connection to your organization's knowledge, and they are not a trustworthy audit trail. If a travel-agency planner asks, "Which of our Kyoto hotel partners have wheelchair-accessible rooms available in April under $250/night, and how does that compare to what past clients reported?", a model-only answer is not enough. The relevant evidence may live in private partner contracts, real-time availability feeds, accessibility inspection records, and past client reviews that the base model has never seen. Even if the model produces a plausible response, the team still needs to know where that answer came from.
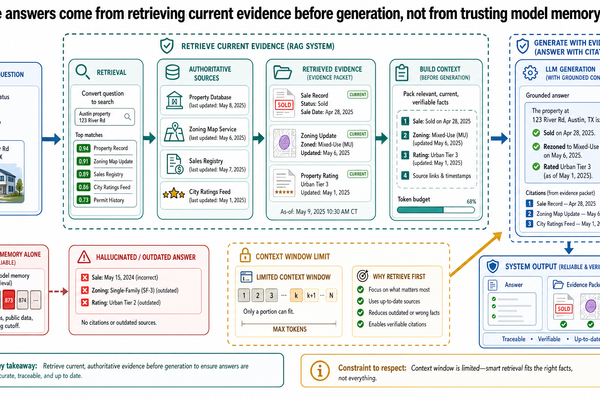
Retrieval-augmented generation, or RAG, is one of the main system patterns used to solve this problem. The central idea is simple: retrieve evidence first, then generate. Instead of asking the model to answer from its parameters alone, the system first searches an external knowledge source for relevant material and passes that evidence into the generation step. The model is not being retrained on the spot. Its weights do not change. What changes is the context it receives at inference time.
That distinction matters because it explains both the value and the limits of RAG. Retrieval can improve freshness, access to private data, and provenance. It does not make the model omniscient. It does not guarantee that the answer uses the evidence correctly. It does not eliminate the need for permissions, indexing discipline, or abstention when the evidence is weak.
Why Model Parameters Are Not Enough
There are three recurring cases where model-only answers break down.
First, there is stale knowledge. Training happens at a point in time. Even if a model was trained on a broad public corpus, it cannot be assumed to reflect the latest hotel availability, the newest accessibility renovation, or a contract updated last week.
Second, there is private knowledge. Most organizations care about questions whose answers live in internal systems: partner contracts, booking records, accessibility audits, client feedback forms, supplier rate sheets, and availability databases. Those materials are usually not part of public model training, and they should not be assumed to be embedded in the model.
Third, there is missing provenance. In many business and operational settings, "probably right" is not enough. Teams need to know which source supports a claim, whether the source is current, and whether the answer is summarizing or inferring beyond the evidence. A fluent paragraph without evidence is often operationally useless.
This is why grounding is a systems problem, not just a prompt-writing problem. If the answer depends on current or controlled information, the system needs a path to external evidence.
What RAG Actually Is
RAG stands for retrieval-augmented generation. In the original formulation by Lewis et al., the system combines a pretrained language model (the parametric component) with a document index that serves as non-parametric memory. The retrieval mechanism itself has parameters, such as the dense encoder used to embed queries and passages, but the knowledge store it searches is non-parametric: it can be updated, replaced, or expanded without retraining the model. In practical product terms, RAG is a pattern where a system:
stores external knowledge in a searchable form,
retrieves the most relevant pieces for a given query, and
asks the model to answer using those retrieved pieces as evidence.
That definition is worth stating carefully because RAG is often described too loosely.
RAG is not online learning. The system is not permanently updating the model's knowledge every time it retrieves a document.
RAG is not the same thing as web search. Search may be one retrieval source, but many RAG systems retrieve from internal corpora, structured records, or mixed knowledge stores.
RAG is not a guarantee of factuality. Retrieval improves the system's ability to ground an answer in available evidence, but the final answer can still be wrong if the wrong evidence is retrieved, if key evidence is missing, or if the model misreads what it was given.
RAG is best understood as a grounding strategy. It gives the model access to evidence at answer time.
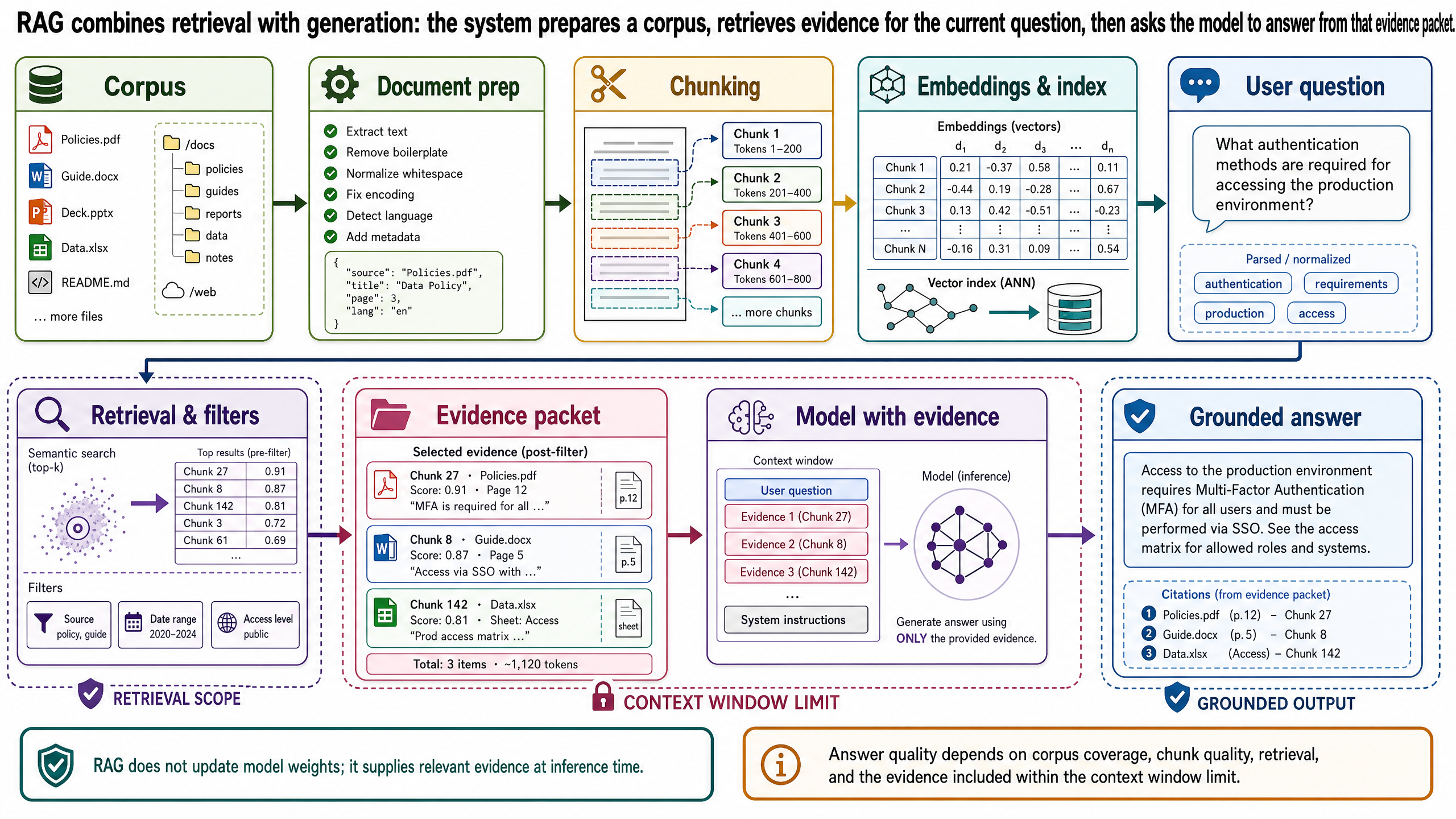
The Basic Retrieval Pipeline
The simplest RAG pipeline can be explained without assuming prior knowledge of vector databases or retrieval research. Think of it as a sequence of preparation and runtime steps.
1. Build the corpus
The system begins with a corpus: the set of documents or records it is allowed to use. In the OptiVerse Travel copilot, that might include hotel partner contracts, real-time availability feeds, accessibility inspection reports, past client itineraries, review summaries, and supplier rate sheets.
This step is more important than it sounds. If relevant sources are missing, no retrieval method can recover them later. A grounded system with an incomplete corpus often looks confident while silently failing to see decisive evidence.
2. Prepare the documents
Raw documents are rarely retrieval-ready. PDFs may need text extraction. Tables may need normalization. Metadata such as source type, date, booking reference, property ID, accessibility rating, and access permissions may need to be attached. This preparation step is where many production systems either become usable or remain fragile.
Document preparation also determines what the system can later cite or filter. If an accessibility report is ingested without the contract ID that links it to a hotel partner, the retriever may never connect the user's question to the relevant record.
3. Split content into chunks
Most systems do not retrieve entire contracts or full inspection reports at once. They split content into chunks: smaller passages that can be indexed and compared efficiently.
Chunking is a practical design choice, not a trivial preprocessing step. If chunks are too small, the system may retrieve fragments without enough context to support a claim. If chunks are too large, retrieval may become noisy, and irrelevant text can crowd out the key passage. Good chunking often follows document structure where possible, such as sections, paragraphs, table regions, or contract clause boundaries.
4. Create embeddings and index them
An embedding is a numerical representation of a piece of text or another object. At a high level, embeddings place semantically similar content near each other in a high-dimensional space. This lets the system compare a user question with stored chunks by meaning, not just exact keyword overlap.
Once chunks are embedded, the system stores those vectors in an index that supports similarity search. This is the part many people summarize as "vector search." The important point for a first systems view is not the database brand or indexing algorithm. The important point is that the system has transformed the corpus into a form where semantically related passages can be retrieved quickly.
5. Retrieve candidates for the query
When a user asks a question, the system typically converts that question into an embedding as well, then searches for the most relevant chunks in the index. Some systems also apply metadata filters before or after retrieval, such as limiting results to hotel contracts for a given region or only to records the current user is allowed to access.
This stage often returns candidate passages rather than final evidence. The goal is to gather a promising set, not to assume the first retrieved chunk is correct.
6. Rerank or filter the evidence
Many practical systems add a reranking step after initial retrieval. A fast retriever can cast a wide net, and a second model or scoring method can reorder the candidates based on closer relevance to the exact question. This often improves answer quality because the generation step sees a tighter, more relevant evidence set.
At a beginner-friendly level, reranking solves a simple problem: the first search pass is efficient but imperfect, so the system uses a more careful pass to improve the shortlist.
7. Generate the answer from the retrieved context
Only after retrieval does the model generate the response. The prompt typically includes the user's question, instructions about how to use evidence, and the retrieved passages or records. This is the "augmented" part of retrieval-augmented generation.
If the system is designed well, the model is not asked to answer from general knowledge when the evidence is missing. It is asked to summarize, compare, extract, or synthesize based on what was retrieved.
8. Return the answer with provenance, warning, or abstention
A production system should not stop at generated text. It should decide how to present support. That may mean linked source passages, document titles, contract IDs, booking references, or confidence warnings. It may also mean refusing to answer when the evidence is too weak, contradictory, or incomplete.
That last branch is part of grounding. A useful grounded system sometimes says, "I do not have enough reliable evidence to answer this."
What Retrieval Solves
Retrieval solves a specific class of problems well.
It helps with freshness because the answer can use material added after model training.
It helps with private knowledge because the corpus can include internal documents that the base model never had access to.
It helps with provenance because the system can attach source references to the answer, making it easier for users to inspect the supporting evidence.
It also helps with governance. Because retrieval draws from an explicit corpus, teams can reason about scope, permissions, indexing schedules, and auditability in ways that are much harder when people speak as if the answer simply came from "the model."
For the OptiVerse Travel copilot, this is the difference between a generic answer about Kyoto hotels and a grounded answer tied to actual evidence. The system can retrieve Contract KYO-H12 showing partner room rates and accessibility features, cross-reference that with the latest April availability feed, pull accessibility photo set ACC-09 from a prior inspection, and surface client reviews from families who previously booked wheelchair-accessible rooms at that property. That is far more useful than an ungrounded summary of general travel knowledge.
What Retrieval Does Not Solve
RAG is often oversold by people who have only seen happy-path demos. Retrieval improves the conditions for a good answer, but it does not remove the rest of the system design problem.
It does not guarantee that the retrieved evidence is the right evidence. A weak retriever can miss the crucial contract clause, return a superficially similar but irrelevant hotel listing, or overemphasize popular properties instead of those that actually meet the accessibility criteria.
It does not guarantee faithful use of citations. A response may include links or footnotes and still overstate what the source says. Source attribution is valuable, but attribution is not proof of faithful reasoning over that source.
It does not solve access control on its own. If the retrieval layer is not permission-aware, it can expose sensitive content just as efficiently as it retrieves useful content.
It does not solve corpus quality. If the knowledge base is incomplete, outdated, duplicated, or badly normalized, the model will generate from a flawed evidence set.
It does not replace domain judgment. In travel planning, the correct answer may depend on interpreting seasonal availability, accessibility standards across regions, or conflicting client preferences. Retrieval can assemble the evidence; it cannot by itself define the policy for how conflicts should be handled.
This is why "RAG reduces hallucinations" should be treated as an incomplete statement. Retrieval can reduce unsupported answering when the evidence layer is strong and the generation policy is disciplined. It can also produce very persuasive errors when retrieval is weak and the system fails to abstain.
Evidence-Backed Answers Versus Model-Only Replies
The easiest way to understand RAG is to compare answer modes.
A model-only reply is generated from the model's parameters and the user's prompt. It may be fluent and even directionally correct, but the user usually cannot inspect the evidence path. If the answer is wrong, it is hard to tell whether the model is outdated, confused by the wording, or inventing support.
An evidence-backed answer has a different contract. The system retrieves external material, constrains the answer around that material, and exposes where the support came from. This changes the operational meaning of the output. The answer becomes inspectable.
Inspectable does not mean infallible. The system may still summarize incorrectly or make an unsupported inference across documents. But inspectability matters because it gives users and evaluators something concrete to verify. In practice, the difference between "the model says" and "the system found these records and summarized them as follows" is one of the biggest architecture shifts in modern AI products.
For engineers and decision-makers, that shift has practical consequences:
evaluation can include retrieval accuracy, citation faithfulness, and abstention behavior, not just final-answer style;
failures become diagnosable because they can often be traced to ingestion, indexing, permissions, ranking, or generation policy;
trust becomes a system property shaped by evidence handling, not a vague belief in model intelligence.
A Practical System View
The simplest demos make RAG look like "search, then paste a few paragraphs into the prompt." Production systems are more structured.
At ingestion time, they extract text, preserve structure where possible, attach metadata, and maintain indexes.
At query time, they enforce access control, retrieve candidates, rerank them, decide how much context to include, and instruct the model to use the evidence conservatively.
After generation, they often attach references, log the evidence path, and evaluate whether the system should have abstained.
Seen this way, RAG is not one component. It is a pipeline with multiple opportunities to fail or to improve. The retriever matters. The corpus matters. Chunking matters. Metadata matters. Prompt instructions matter. Answer policy matters.
This is also why stronger base models do not remove the need for retrieval engineering. A very capable model can still fail badly if the wrong evidence is passed in, if critical evidence is omitted, or if the context window is filled with noisy passages. Answer quality is often dominated by retrieval quality.
Running Example: Accessible Hotel Lookup
Consider the question: "Which of our Kyoto hotel partners have wheelchair-accessible rooms available in April under $250/night, and how does that compare to what past clients reported?"
A grounded OptiVerse Travel copilot might handle this as follows.
It first identifies the trip context from the user's request — booking JPN-2026-0417, a 10-day accessible Japan itinerary for a family of four with a $13K–$15K budget. It then retrieves partner contracts for Kyoto properties (such as Contract KYO-H12), real-time availability feeds for April dates, accessibility inspection records including photo set ACC-09, and past client reviews from families who booked similar accommodations. It filters or reranks those results so that the most relevant passages for the specific accessibility requirements and nightly rate threshold are at the top.
Only then does the model synthesize an answer. A careful response might say that two Kyoto partner hotels have wheelchair-accessible rooms available in the requested dates under $250/night, but one property received mixed accessibility feedback from a prior client who noted narrow bathroom doorways despite the hotel's ADA-equivalent certification. The answer can cite the contract IDs, availability feed timestamps, and the specific client review used for the comparison.
That answer is useful because it is grounded in evidence, scoped to the actual question, and explicit about the comparison boundary. A model-only answer would struggle to do any of those things reliably because the decisive evidence is private and specific.
Just as important, the system should know when not to answer. If the contract terms are ambiguous, if the availability feed is stale, or if the relevant accessibility report has not been ingested, the correct behavior may be to return a partial answer with a warning or to abstain entirely pending more evidence.
What This Post Is Not
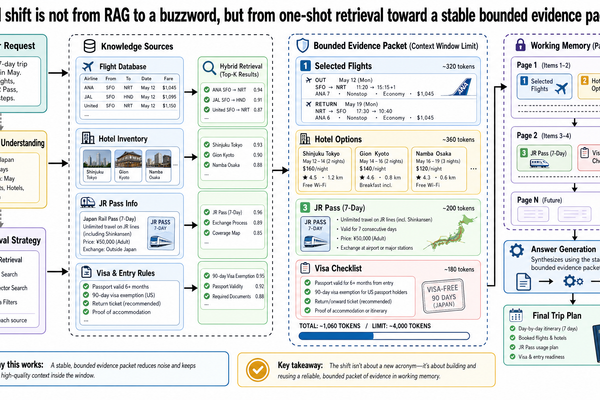
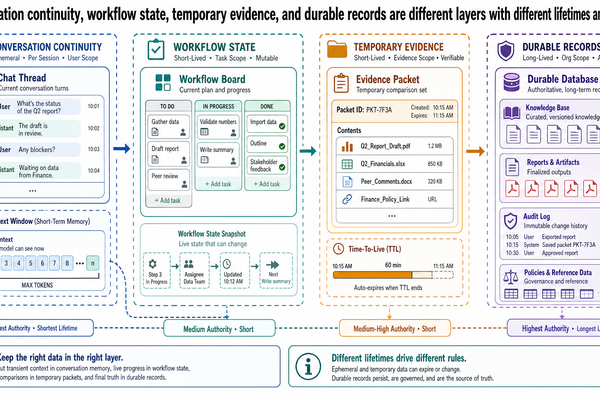
This is not a post about advanced retrieval alternatives such as cache-augmented generation, hybrid grounding, or long-context strategies. Those belong to Post 7. It is not a memory architecture post; the separation of retrieval from conversation memory, task state, working memory, and durable knowledge comes in Post 4. And it is not a document-intelligence post; when tables, layout, and page structure matter for retrieval quality, that becomes a separate systems problem addressed in Post 8.
This post covers baseline RAG as a grounding strategy. Everything else builds on top of it.
Common Misconceptions
One common misconception is that RAG means the model has learned the retrieved material. It has not. Retrieval changes the current prompt context, not the model's long-term parameters.
Another misconception is that any cited answer is therefore grounded. Citation formatting is easy to imitate. What matters is whether the cited source actually supports the claim and whether the system can show that link clearly.
A third misconception is that retrieval is just a convenience feature layered on top of a capable model. In many domains, retrieval is part of the minimum viable architecture because the answer depends on current or controlled evidence.
There is also a tendency to collapse RAG into generic "search." Search is part of many RAG systems, but RAG includes the end-to-end pattern of evidence preparation, retrieval, answer conditioning, and provenance-aware output.
Finally, some teams assume a grounded system should always produce something. In practice, abstention is often a sign of maturity. If the evidence is weak, a confident answer can be worse than no answer.
Failure Modes to Watch
Poor chunking can break support. A key contract clause may be separated from the rider that qualifies it, causing retrieval to surface a misleading fragment.
Weak recall can hide the truth. If the retriever misses the one decisive accessibility report, the generation step cannot recover it.
Noisy context can dilute good evidence. Adding more chunks is not always better. Too much loosely related material can make it harder for the model to focus on what matters.
Incomplete corpora create silent failure. Teams may think they have built a grounded system when they have only built a search interface over a partial document set.
Stale indexes can undermine freshness. New documents do not help if ingestion or indexing lags behind operational reality.
Permission mistakes can create both risk and bad answers. If retrieval ignores access boundaries, the system may expose sensitive information. If it overfilters incorrectly, it may miss evidence the user was allowed to see.
Faithless synthesis remains a real problem. Even with the right passages in context, the model can overgeneralize, merge distinct cases, or present an inference as if it were directly stated.
These are system failures, not just model failures. They need system-level evaluation.
Design Guidance for Engineers and Decision-Makers
Start by defining the evidence contract. What sources is the system allowed to use, and what should the user be able to inspect in the answer?
Treat corpus preparation as product work, not plumbing. The usefulness of a RAG system is often decided before the first retrieval call, during extraction, metadata design, and permission handling.
Evaluate retrieval separately from generation. If you only score final answers, you may miss whether the system failed to retrieve the right evidence or failed to use good evidence correctly.
Design abstention explicitly. Decide what the system should do when evidence is missing, contradictory, or low confidence. "Answer anyway" is rarely a serious policy for operational use cases.
Use provenance as a product feature. Source links, document names, timestamps, and contract IDs are not decorative extras. They are part of the value proposition of grounded systems.
Keep the retrieval pipeline understandable. Teams make poor architecture decisions when retrieval is treated as magic infrastructure. Engineers and product owners should be able to explain the pipeline from corpus to answer in plain language.
What Comes Next
RAG gives a system a way to retrieve evidence at answer time. That is not the same thing as remembering prior conversation turns, tracking workflow progress, or maintaining durable organizational records. A system may do all of those things, but they are different responsibilities with different storage, update, and authority rules.
That distinction matters more as systems become more interactive. In the next post, we will separate conversation memory, task state, working memory, and durable knowledge stores so the architecture stays clear. After that, the evidence problem widens again: once tables, figures, captions, and page structure matter, retrieval becomes a document-intelligence problem, and later still it becomes multimodal evidence handling.
Source Notes
This post draws on the following primary and practitioner sources:
Lewis, P., Perez, E., Piktus, A., et al. "Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks." Primary reference for RAG as generation conditioned on retrieved non-parametric memory. arxiv.org/abs/2005.11401
Karpukhin, V., Oguz, B., Min, S., et al. "Dense Passage Retrieval for Open-Domain Question Answering." Reference for dense retrieval over embedded passages. arxiv.org/abs/2004.04906
Asai, A., Wu, Z., Wang, Y., et al. "Self-RAG: Learning to Retrieve, Generate, and Critique through Self-Reflection." Reference for adaptive retrieval and evidence critique as advanced RAG behavior. arxiv.org/abs/2310.11511
BAIR. "The Shift from Models to Compound AI Systems." System-level reference for retrieval as one component around the model. bair.berkeley.edu/blog/2024/02/18/compound-ai-systems
National Institute of Standards and Technology. "Artificial Intelligence Risk Management Framework: Generative Artificial Intelligence Profile." Reference for provenance, evaluation, and risk management language around grounded outputs. nist.gov/publications/artificial-intelligence-risk-management-framework-generative-artificial-intelligence
Huang Tzu Lin
With over five years in autonomous robotics, there's a strong passion for incorporating cutting-edge technologies and innovative approaches. Dedicated to transforming the latest research and insights into practical applications, this journey pushes the limits of possibility.
Related Posts
Stay Updated
Get the latest technical insights delivered to your inbox.