Memory, State, and Knowledge: Stop Calling Everything "Memory"
Reading order
Building AI Systems
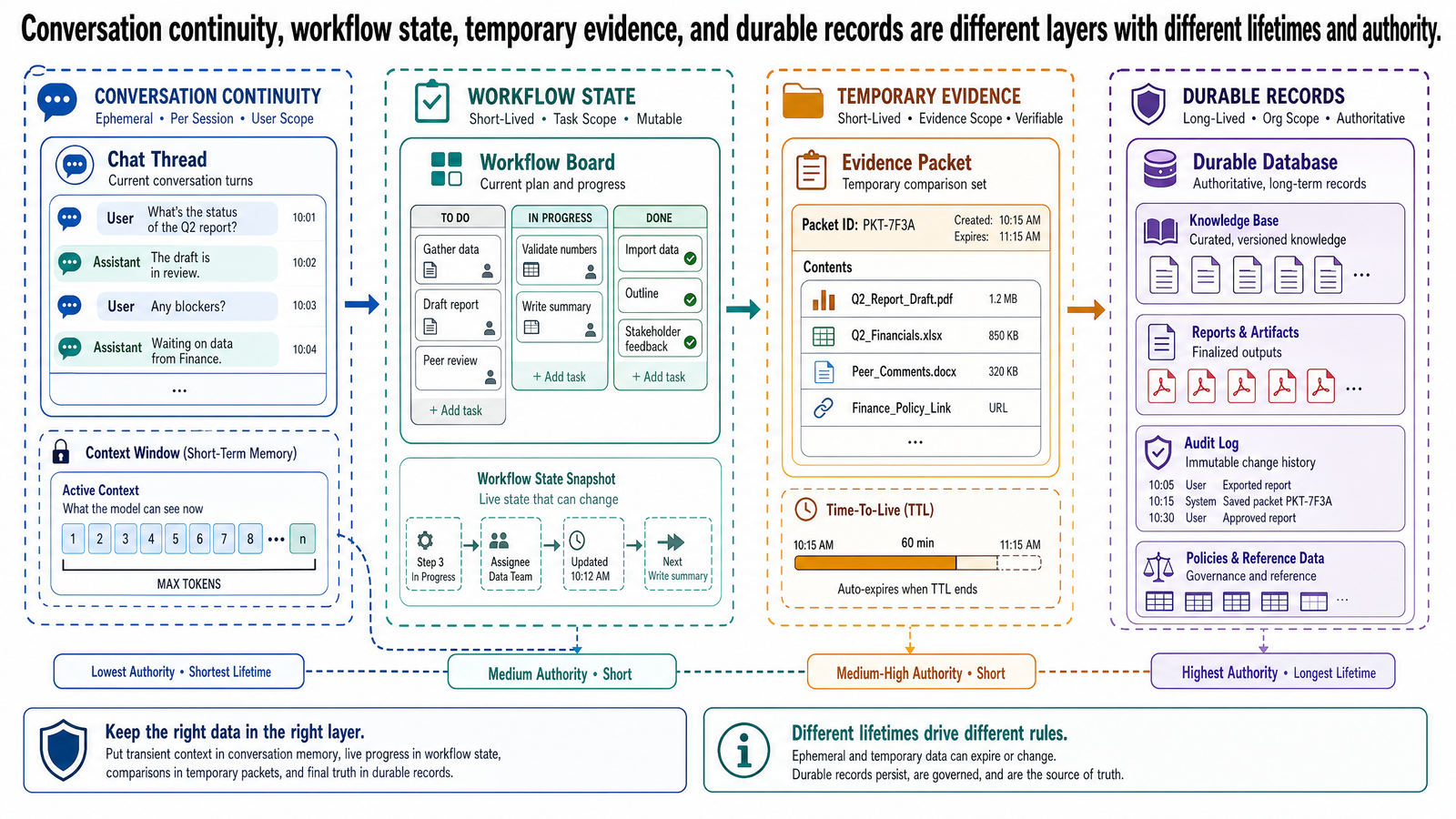
Table of Contents
- Why "Memory" Becomes a Catch-All
- The Four Layers
- Conversation Memory
- Task State
- Working Memory
- Durable Knowledge Stores
- A Direct Comparison
- Running Example: Trip Preferences Versus Factual Records
- Conversation Memory In This Example
- Task State In This Example
- Working Memory In This Example
- Durable Knowledge In This Example
- Common Misconceptions
- "Chat history is basically a knowledge base."
- "If the system remembers a prior turn, it has durable memory."
- "Prompt caching means the system now knows the information."
- "Long context solves memory."
- "Everything stored by an agent should be called memory."
- Failure Modes When The Layers Collapse
- Stale Chat Assumptions Become Facts
- Workflow State Drifts From Reality
- Temporary Evidence Is Mistaken For Durable Record
- Preferences Leak Into Factual Logic
- Privacy And Retention Problems
- False Confidence From Repetition
- Practical Design Guidance
- 1. Give Each Layer A Clear Job
- 2. Separate Authority From Convenience
- 3. Keep Task State Structured
- 4. Treat Working Memory As Disposable
- 5. Require Provenance For Durable Knowledge
- 6. Design Retention Policies Explicitly
- What This Post Is Not
- Why This Distinction Matters Before We Talk About Agents
- Source Notes
A travel-planning copilot for a mid-size agency is asked a straightforward question: "Did this hotel fail an accessibility review before for wheelchair users?"
The assistant answers confidently that it did. The answer sounds plausible because the earlier conversation mentioned a rejected Kyoto property, the user has been discussing accessible accommodations for several turns, and the current screen still shows a hotel comparison workflow in progress. But the active booking explicitly requires properties with verified wheelchair access, the current contract ID points to a different hotel, and the actual partner database shows no prior accessibility failure for this specific property.
Nothing supernatural went wrong. The system collapsed several different information layers into one vague idea of "memory." It treated prior chat, workflow variables, temporary evidence, and durable records as interchangeable. That is a design error, not an intelligence problem.
This confusion shows up constantly in AI product discussions. Teams say a system "needs memory" when they actually mean one of several different things:
continuity across turns in a conversation
structured state for a workflow already in progress
temporary context assembled for a single task
durable factual records that should outlive any one session
Those are different responsibilities. They should be designed, stored, updated, and governed differently.
This post separates four terms that are often blurred together:
conversation memory
task state
working memory
durable knowledge stores
The goal is practical system clarity. This is not a post about human cognition, inner monologue, or whether a model "really remembers." It is not a broad survey of memory architectures either. It is about software architecture for stateful AI systems and the minimum vocabulary needed for the rest of the series.
Post 3 established the retrieval pipeline: how a system fetches evidence from an external corpus before generating an answer. That is one specific information responsibility. This post steps back to clarify that retrieval is not the only kind of information a system carries forward, and that the four layers described here have different jobs, lifetimes, and authority rules.
Why "Memory" Becomes a Catch-All
Conversational interfaces encourage sloppy terminology. When a system responds in a continuous dialogue, users and builders naturally describe any reused information as memory. That sounds harmless until the system has to be reliable.
In production systems, different kinds of information have different jobs:
Some data helps the system maintain conversational continuity.
Some data tracks where a workflow is and what step comes next.
Some data is assembled only for the current task and should be discarded or refreshed.
Some data is a durable organizational record with provenance, permissions, and update rules.
Calling all of this memory hides critical engineering questions:
Where does the information come from?
How long should it persist?
Who or what is allowed to update it?
What makes it authoritative?
How is it validated?
When should it be ignored?
Once those questions matter, the catch-all label stops helping.
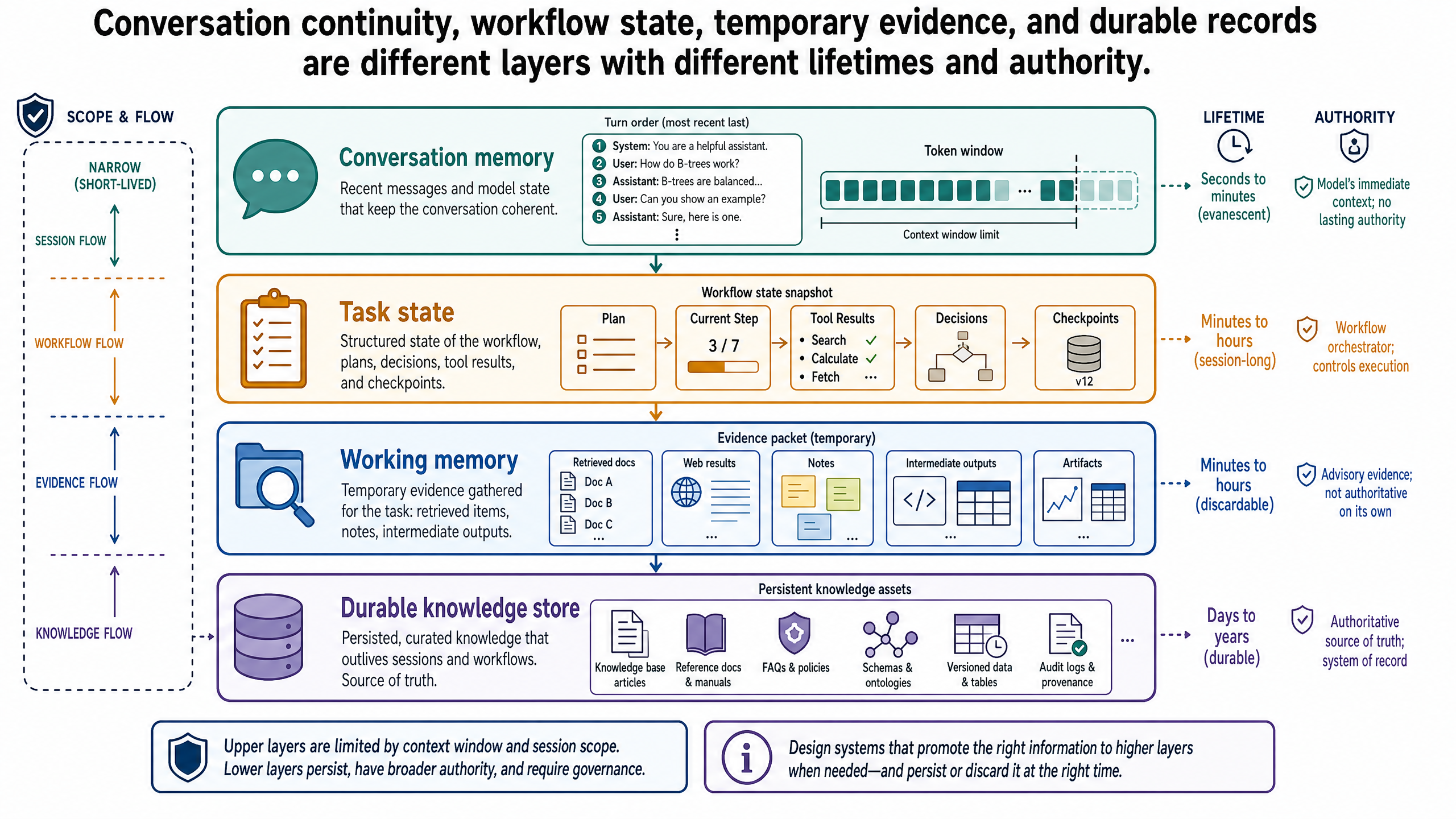
The Four Layers
The cleanest way to think about the problem is to separate four layers of information handling.
Conversation Memory
Conversation memory is information preserved across turns so the interaction remains coherent. It helps the system continue a dialogue without making the user restate everything on every turn.
Typical examples:
the client prefers trains over buses
the active trip reference number
the fact that "this hotel" refers to the property discussed two turns ago
a previously stated client constraint that should still apply during the session
What it is for:
dialogue continuity
local user experience
reference resolution across turns
What it is not:
a verified source of durable facts
a complete representation of application state
a substitute for domain records
Conversation memory is often lightweight and session-scoped, though some systems persist parts of it across sessions. Even when persisted, it should not automatically become authoritative knowledge. A remembered preference such as "show prices in USD" is fundamentally different from a remembered claim such as "Hotel Sakura failed its wheelchair-access audit in March."
Task State
Task state is structured information about an active workflow. It describes what the system is doing, what has already happened, and what identifiers or control variables matter for the next step.
Typical examples:
current trip ID: JPN-2026-0417
hotel comparison status
itinerary draft ID
which booking calls have already completed
approval status for a trip proposal
What it is for:
workflow control
resumability
idempotency
coordination between application components
What it is not:
conversational continuity by itself
factual knowledge about the domain
temporary evidence selected for a single reasoning pass
Task state should feel familiar to any software team. It is not exotic AI functionality. It is ordinary application state, just attached to systems that happen to use models.
This distinction matters because a system can have excellent conversational continuity and still lose the workflow. It can also have robust workflow state while still answering factual questions incorrectly if it is not grounded in authoritative records.
Working Memory
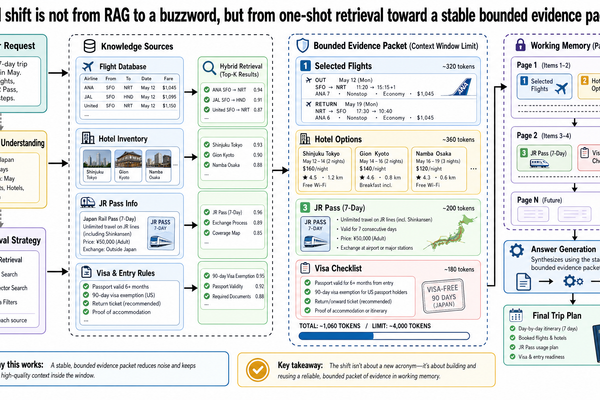
Working memory is the temporary context assembled for one task or reasoning pass. It usually includes the subset of retrieved evidence, extracted fields, intermediate summaries, and current instructions needed right now.
Typical examples:
the three most relevant accessible Kyoto hotels retrieved from the partner database
extracted pricing and room details from one property listing
a temporary comparison packet built for the hotel-selection task
intermediate notes used while producing a grounded recommendation
What it is for:
focusing the model on relevant context
reducing unnecessary context load
enabling multi-step reasoning over a bounded evidence set
What it is not:
a durable record
a user profile
a workflow ledger
Working memory is ephemeral by design. It may live in a context window, a scratchpad structure, an intermediate store for a job, or another runtime layer. The key point is that it is assembled for a task and should not automatically be promoted to durable knowledge just because it was useful once.
This is one reason larger context windows do not eliminate system design. More room for temporary context can help with some tasks, but it does not solve provenance, update policy, access control, or long-term correctness.
Durable Knowledge Stores
Durable knowledge stores hold long-lived information that the system can retrieve and use over time. These stores are the closest thing in this discussion to what many teams informally mean by "memory," but even here the term knowledge is usually more precise.
Typical examples:
partner hotel and tour-operator databases
visa and entry-requirement repositories
rail-pass terms and fare schedules
approved supplier contract records
validated accessibility audit reports
What they are for:
preserving organizational knowledge
supporting grounded retrieval
maintaining records beyond any single session or task
enabling provenance, audit, and controlled updates
What they are not:
a transcript of every conversation
a free-form scratchpad for unfinished reasoning
an ungoverned dump of everything the model has ever seen
Durable knowledge stores need ordinary data-management discipline. They need schemas or at least stable structure, access controls, freshness policies, lineage, and rules for how new material becomes trusted enough to use. If a system cannot explain where a durable fact came from, when it was updated, and whether it was approved, then its "memory" design is not mature.
A Direct Comparison
These four layers are related, but they should not be conflated.
Layer — Main purpose — Typical lifetime — Example — Failure if misused
Conversation memory — Keep dialogue coherent across turns — Session or selectively persistent — "Client prefers trains over buses" — Chat-derived assumptions treated as facts
Task state — Track workflow progress and control variables — Until task completion or archival — trip_id=JPN-2026-0417 — Workflow drift, duplicate actions, lost progress
Working memory — Hold the temporary context for the current task — Seconds to one job run — Retrieved hotel listings and extracted accessibility details — Temporary evidence mistaken for durable truth
Durable knowledge — Store authoritative records that outlive sessions — Long-lived — partner database, visa-requirement repository — Stale, untraceable, or unauthorized facts
This comparison reveals a practical rule:
Not all persistence is memory, and not all memory-like behavior should be treated as knowledge.
If a team uses one storage mechanism and one vague label for all four responsibilities, the system will eventually confuse preference with fact, workflow with evidence, or temporary context with durable records.
Running Example: Trip Preferences Versus Factual Records
Return to the travel-planning copilot.
An agent is working on a 10-day accessible Japan itinerary for a family of four. The trip requires wheelchair accessibility throughout. The current task is to compare one candidate hotel against prior client feedback and verified accessibility data.
Here is how the information should be separated.
Conversation Memory In This Example
The system may preserve:
the active trip reference: JPN-2026-0417
the client's preference for train travel over buses
the fact that the client wants accommodations framed around cherry-blossom proximity and wheelchair access
That helps the interaction remain smooth. It should not, by itself, answer whether a specific hotel previously failed an accessibility review.
Task State In This Example
The system may track:
the current contract ID: KYO-H12
the status of the hotel comparison workflow
the itinerary draft ID generated for this trip
whether a senior travel consultant has approved the proposed routing
This is what lets the application resume work, avoid duplicate booking calls, and coordinate multiple steps.
Working Memory In This Example
The system may assemble:
retrieved listings from the partner database for accessible Kyoto hotels
extracted pricing and room configurations from one property
a shortlist of relevant tours with verified wheelchair access
intermediate notes comparing accessibility features across properties
This packet exists to support the current analysis. It may be recomputed or replaced as the task evolves.
Durable Knowledge In This Example
The system may retrieve from:
the partner hotel and operator database
accessibility audit records
validated visa and entry requirements
approved rail-pass terms (e.g., JR Pass at ~50,000 yen/adult (7-day) post-2023; Nozomi not included in base pass, supplementary ticket available since October 2023)
These sources should determine the factual answer. If the database shows no prior accessibility failure for the current property, then a prior mention in chat should not override that.
That is the core architectural lesson. The system may remember trip preferences and interaction context, but factual answers should still come from grounded knowledge sources. Conversation continuity is useful; it is not evidence.
Common Misconceptions
Several recurring misconceptions drive bad designs.
"Chat history is basically a knowledge base."
It is not. Chat history is a record of what was said in a conversation. Some of that content may be correct, some may be speculative, and some may be outdated by the next turn. A knowledge base, by contrast, should have explicit ingestion rules, provenance, and update discipline.
Teams that treat chat history as a knowledge base often create systems that repeat earlier guesses as if they were established facts.
"If the system remembers a prior turn, it has durable memory."
Remembering a prior turn usually means the application preserved and reused context. That is useful, but it does not imply durable, governed, or validated knowledge.
Persistence alone is not the issue. The issue is what kind of information is being persisted and what authority it should carry.
"Prompt caching means the system now knows the information."
No. Caching is a runtime optimization. It can reduce repeated processing cost for reused context, but it does not turn temporary prompt material into a durable knowledge asset. A cache hit is not the same thing as a maintained record with provenance and update policy.
"Long context solves memory."
Longer context windows can improve what the model can consider in one pass. They do not solve state management, durable storage, retrieval quality, permissions, or record maintenance. A bigger temporary workspace is still a temporary workspace.
"Everything stored by an agent should be called memory."
This is how systems become unreadable. Store names like user_memory, agent_memory, or long_term_memory often hide very different objects: chat summaries, job variables, document embeddings, tool traces, and scratchpads. These should be separated by role, not grouped by a human-like metaphor.
Failure Modes When The Layers Collapse
The practical cost of fuzzy terminology is not semantic. It is operational.
Stale Chat Assumptions Become Facts
An early guess in a conversation gets repeated later as if it were verified. The system "remembers" the claim, but no authoritative store ever confirmed it.
Workflow State Drifts From Reality
The assistant believes it is still evaluating hotel A while the application has already switched to hotel B. If task state is buried inside chat instead of managed structurally, this kind of drift is predictable.
Temporary Evidence Is Mistaken For Durable Record
A retrieved snippet or intermediate summary is useful for one task, then gets treated as if it were a validated long-term fact. This is especially risky when the evidence packet was assembled under narrow retrieval conditions and may be incomplete.
Preferences Leak Into Factual Logic
User-specific context, such as preferred format or current emphasis, gets mixed into retrieval or ranking logic in ways that distort factual outputs. Personalization is not neutral if it changes what evidence is surfaced.
Privacy And Retention Problems
Teams store too much conversational context for too long because they call it all memory and never define retention boundaries. That creates obvious governance and security risk.
False Confidence From Repetition
If information is cached, repeated, or preserved across turns, users may assume it has become more reliable. But repetition is not validation. A fluent system can be consistently wrong for a long time if the wrong layer is treated as authoritative.
Practical Design Guidance
The easiest way to improve these systems is to stop designing "memory" as one feature and start designing information layers with explicit contracts.
1. Give Each Layer A Clear Job
Before implementation, define:
what the layer stores
why it exists
how long it lives
who can update it
what authority it has
If a layer cannot answer those questions, it is probably hiding multiple responsibilities.
2. Separate Authority From Convenience
Conversation memory is convenient. Working memory is useful. Neither should outrank durable knowledge when factual correctness matters.
This sounds obvious, but many product failures come from convenient context being easier to access than authoritative records.
3. Keep Task State Structured
Do not rely on free-form chat text to track workflow progress. Store identifiers, statuses, and transitions in explicit application structures. That makes resumability, debugging, and audit much easier.
4. Treat Working Memory As Disposable
Temporary evidence packets should be refreshable and replaceable. If they need to become part of durable knowledge, promote them through a separate ingestion or approval process rather than leaving them in an ambiguous middle state.
5. Require Provenance For Durable Knowledge
When a durable store drives answers, the system should be able to trace where records came from, when they were updated, and whether they were approved for this use. This is not optional in serious enterprise or travel-agency settings.
6. Design Retention Policies Explicitly
Conversation memory, task state logs, working memory artifacts, and durable knowledge stores do not need the same retention period. Treating them as one bucket usually leads to either unnecessary deletion or unnecessary accumulation.
What This Post Is Not
This is not a claim that there is one correct memory architecture for all AI systems. The right design depends on the product, risk profile, and workflow.
It is also not a claim that every system needs sophisticated multi-layer storage from day one. Simple products can start simple. But even simple products benefit from naming the layers correctly.
Most importantly, this is not an argument for anthropomorphic language. The useful question is not whether the model has a mind-like memory. The useful question is which system component stores which information under what policy.
Why This Distinction Matters Before We Talk About Agents
Once systems move beyond one-shot prompting, people start describing them as assistants, agents, or autonomous workflows. That discussion becomes muddled immediately if memory, state, and knowledge are still collapsed together.
An assistant may preserve conversation continuity without managing complex task state. An agent may need explicit task state to coordinate multi-step actions. A more autonomous system may need both, while also drawing from durable knowledge and assembling temporary working memory for each subtask.
Those are not labels for different kinds of magic. They are different control patterns built on top of information layers with different responsibilities.
That is the bridge to the next part of the series. Before we can talk clearly about assistants, agents, and autonomy, we need to know what information the system carries forward, what it is doing right now, what temporary evidence it is using, and what durable sources it is allowed to trust.
Source Notes
This post draws on the following official and research sources:
OpenAI. "Conversation state." Official reference for application-managed conversation continuity and state handling. developers.openai.com/api/docs/guides/conversation-state
OpenAI. "Prompt caching." Official reference used to distinguish runtime cache reuse from durable memory or authoritative knowledge. developers.openai.com/api/docs/guides/prompt-caching
Anthropic. "Context windows." Reference for context as bounded working memory rather than the model's training corpus. docs.anthropic.com/en/docs/build-with-claude/context-windows
Park, J. S., O'Brien, J. C., Cai, C. J., et al. "Generative Agents: Interactive Simulacra of Human Behavior." Research reference for stored experiences, retrieval, and reflection as explicit architecture. arxiv.org/abs/2304.03442
Packer, C., Fang, V., Patil, S. G., et al. "MemGPT: Towards LLMs as Operating Systems." Reference for memory hierarchy as a systems design problem. arxiv.org/abs/2310.08560
National Institute of Standards and Technology. "Artificial Intelligence Risk Management Framework: Generative Artificial Intelligence Profile." Reference for data governance, provenance, and trustworthy-use framing. nist.gov/publications/artificial-intelligence-risk-management-framework-generative-artificial-intelligence
Huang Tzu Lin
With over five years in autonomous robotics, there's a strong passion for incorporating cutting-edge technologies and innovative approaches. Dedicated to transforming the latest research and insights into practical applications, this journey pushes the limits of possibility.
Related Posts
Stay Updated
Get the latest technical insights delivered to your inbox.