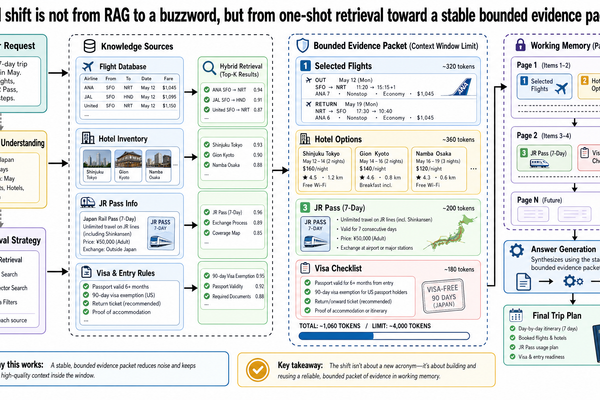
當 RAG 不夠用時:快取增強生成(CAG)、混合檢索與工作記憶
基本的檢索增強生成(RAG)到現在還是多數正式環境系統最常用的基礎模式。語料庫很大、更新頻繁、又需要展示答案來源?檢索依然是最乾淨的起點。不過實務上會碰到一種極限情境——簡單的 RAG 開始力不從心:系統確實找到了正確的文件,但任務現在需要的是針對一組有限的證據持續推理,同時回答同一案件的多次後續追問。
Huang Tzu Lin
4 posts
基本的檢索增強生成(RAG)到現在還是多數正式環境系統最常用的基礎模式。語料庫很大、更新頻繁、又需要展示答案來源?檢索依然是最乾淨的起點。不過實務上會碰到一種極限情境——簡單的 RAG 開始力不從心:系統確實找到了正確的文件,但任務現在需要的是針對一組有限的證據持續推理,同時回答同一案件的多次後續追問。
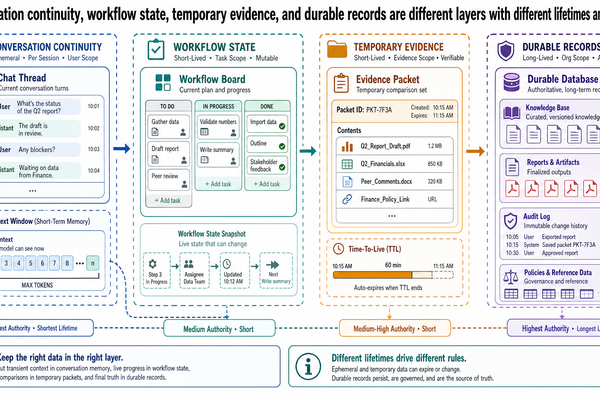
一個為中型旅行社打造的旅遊規劃 Copilot,被問了一個很直接的問題:「這間飯店之前是否在輪椅使用者的無障礙審查中未通過?」
Basic retrieval-augmented generation, or RAG, is still the default grounding pattern for most production systems. If you have a large corpus, frequent updates, and a need to show where an answer came from, retrieval remains the cleanest starting point. But there is a practical limit case where si...
A travel-planning copilot for a mid-size agency is asked a straightforward question: "Did this hotel fail an accessibility review before for wheelchair users?"