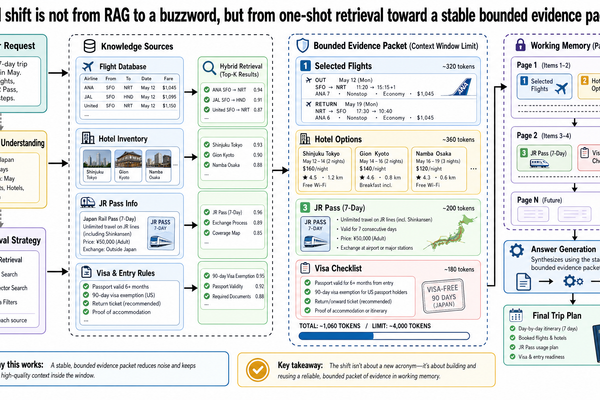
當 RAG 不夠用時:快取增強生成(CAG)、混合檢索與工作記憶
基本的檢索增強生成(RAG)到現在還是多數正式環境系統最常用的基礎模式。語料庫很大、更新頻繁、又需要展示答案來源?檢索依然是最乾淨的起點。不過實務上會碰到一種極限情境——簡單的 RAG 開始力不從心:系統確實找到了正確的文件,但任務現在需要的是針對一組有限的證據持續推理,同時回答同一案件的多次後續追問。
Huang Tzu Lin
6 posts
基本的檢索增強生成(RAG)到現在還是多數正式環境系統最常用的基礎模式。語料庫很大、更新頻繁、又需要展示答案來源?檢索依然是最乾淨的起點。不過實務上會碰到一種極限情境——簡單的 RAG 開始力不從心:系統確實找到了正確的文件,但任務現在需要的是針對一組有限的證據持續推理,同時回答同一案件的多次後續追問。
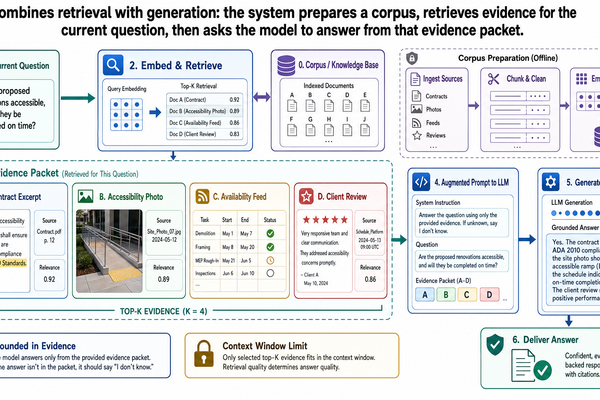
大型語言模型之所以有用,是因為它們能用流暢的語言綜合、解釋和轉化資訊。但一旦我們要求它們處理即時的、私有的,或需要可驗證依據的資訊,它們就變得不可靠。模型在訓練期間可能看過類似的素材,但這不代表它能存取當前任務需要的那份飯店合約、無障礙稽核或客戶回饋記錄。
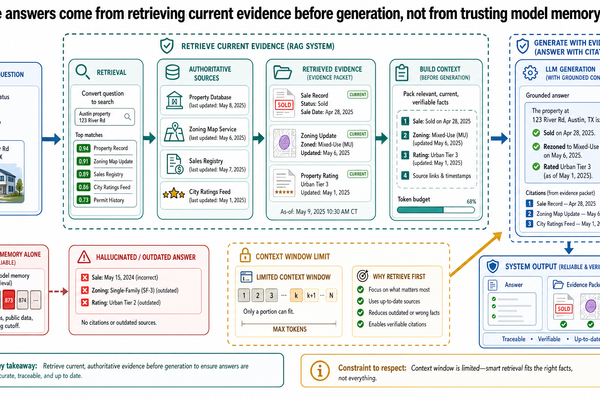
大型語言模型能產出流暢又自信的文字。而這份自信,正是問題所在。模型可以把一筆已經下架的房源、一個上一季才變動的稅率、一則三年前的學校評分,講得頭頭是道。它沒有任何機制去查核——本來就不是為查核設計的。它的工作是根據訓練資料預測下一個最合理的 token,而合理不等於正確。
Basic retrieval-augmented generation, or RAG, is still the default grounding pattern for most production systems. If you have a large corpus, frequent updates, and a need to show where an answer came from, retrieval remains the cleanest starting point. But there is a practical limit case where si...
Large language models are useful because they can synthesize, explain, and transform information in fluent language. They are unreliable when we ask them to know something current, something private, or something that needs verifiable support. A model may have seen similar material during trainin...
Large language models produce fluent, confident text. That confidence is the problem. A model can sound authoritative about a property listing that no longer exists, a tax rate that changed last quarter, or a school rating from three years ago. It has no mechanism to check. It was not designed to...