From Models to Compound AI Systems
Reading order
Building AI Systems
Previous chapter
No adjacent chapter
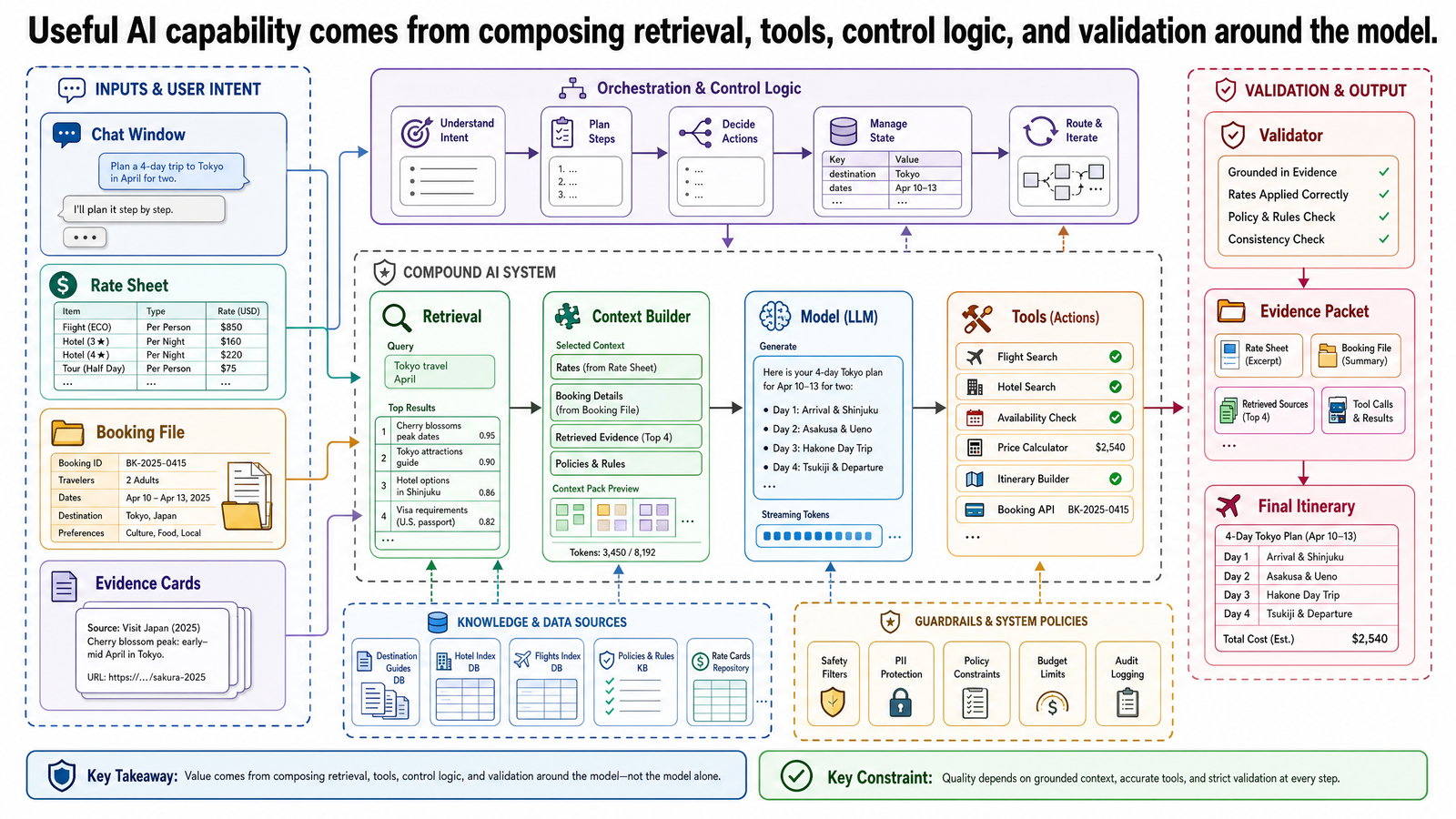
Table of Contents
- Why Model-Only Thinking Breaks
- Defining the Core Terms
- Model
- System
- Compound AI system
- Control logic
- Tool
- Retrieval
- Validation
- State
- What Counts as an LLM System
- From Monolithic Models to Compound Systems
- The Main Components Around the Model
- Input and routing
- Data access
- Extraction and transformation
- Model inference
- Validation and guardrails
- Presentation and provenance
- Running Example: The OptiVerse Travel Copilot
- Monolithic Versus Modular Thinking
- Common Misconceptions and Failure Modes
- Misconception 1: A better model removes the need for system design
- Misconception 2: Prompt engineering is the main path to system quality
- Misconception 3: Any multi-step AI workflow is an agent
- Misconception 4: Retrieval and validation are optional add-ons
- What This Post Is Not
- Where the Series Goes Next
- Source Notes
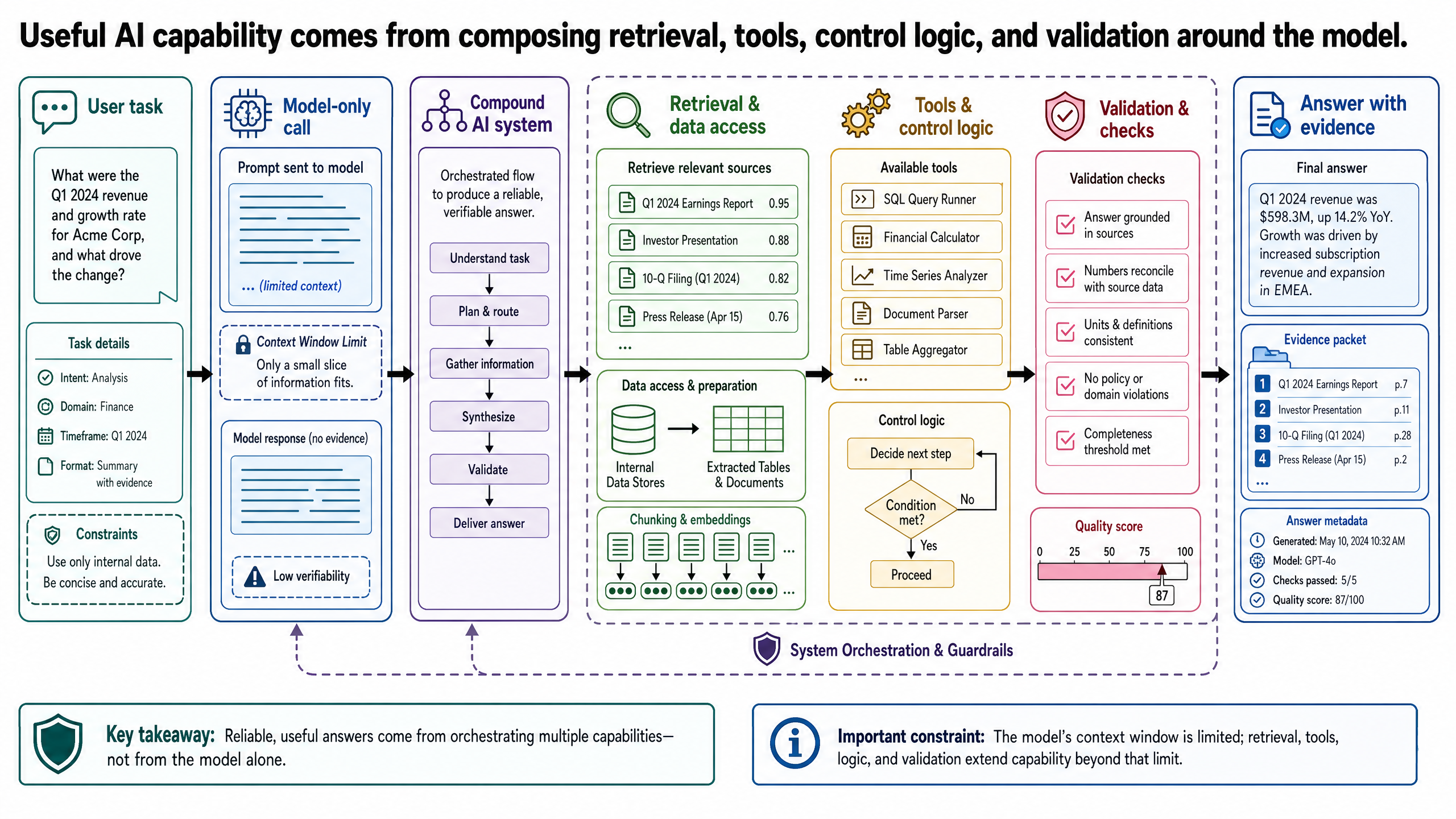
Most failures in real AI products do not come from the model suddenly becoming unintelligent. They come from asking a model to do work that actually belongs to a larger system: fetch the right data, interpret a messy document, check a schema, track state across steps, and show evidence for the answer. A strong demo can hide that distinction for a while. Production use exposes it quickly.
That is why the right starting point for modern AI architecture is not "Which model should we use?" but "What system does this task require?" For engineers and technical decision-makers, this shift matters because capability is often a property of the surrounding design, not just of the model call. In practice, useful AI applications are rarely just model calls. They are compound systems that combine models with data access, control logic, tools, and validation.
This post introduces that shift using a running example: a travel copilot for OptiVerse Travel, a mid-size agency specializing in custom itineraries. The goal is not to make the system sound autonomous. It is to show, in concrete terms, why the model is only one component inside a broader design.
Why Model-Only Thinking Breaks
Consider a question from a travel planner:
Can we build an accessible 10-day Japan itinerary for a family of four during cherry blossom season within a $13,000–$15,000 budget, and does our Kyoto hotel partner still honor the contracted wheelchair-accessible rate?
A base language model can produce a plausible answer to that prompt. But plausibility is not the same as a correct system response.
To answer the question well, the application may need to:
find the booking file JPN-2026-0417 and its existing constraints
retrieve the relevant hotel partner contract and airline rate sheets
extract rate tables and accessibility clauses from PDF agreements
normalize currencies, date formats, and room-type codes
compare contracted rates against current seasonal availability
present the result with evidence and clear uncertainty
None of those requirements are guaranteed by the model alone. They depend on access to the right data, the right sequence of steps, and checks around the model output. If the system does not provide those capabilities, the model will often guess, generalize from training data, or answer without the provenance the user actually needs.
This is the first key distinction of the series:
A
modelis the learned component that maps inputs to outputs.A
systemis the full application around that model, including data flow, orchestration, constraints, and evaluation.
Once that distinction is explicit, many common frustrations become easier to diagnose. When an AI product returns stale information, ignores an internal database, or emits an answer in the wrong format, the problem is often not "the model is bad." The problem is that the task required system components that were never designed.
Defining the Core Terms
Before using the terminology loosely, it helps to define a few terms in operational language.
Model
A model is the statistical component that produces text, classifications, structured fields, or other outputs from an input context. In this series, that usually means a large language model, but the same system patterns can involve OCR models, layout models, vision-language models, or ranking models.
System
A system is the complete application that turns a user task into a result. It includes the model call, but also everything required to make that call useful: input handling, data access, workflow steps, error handling, output formatting, and evaluation.
Compound AI system
A compound AI system is an AI application built from multiple interacting components rather than a single monolithic model call. Those components can include models, retrieval layers, tool calls, extraction services, deterministic logic, validators, and approval boundaries for higher-consequence actions. The defining idea is compositional architecture: capability comes from how the pieces work together, not just from a larger base model.
The term is useful because it describes what many real systems have become. Research and industry practice increasingly treat high-performing applications as multi-component systems with explicit orchestration, not just isolated models.
Control logic
Control logic is the part of the system that decides what happens next. It can be simple and deterministic or it can involve model-based routing. In either case, it is the workflow layer that coordinates the system. The details of pipeline design belong in the next post. Here, the point is only that this coordination layer exists and materially shapes system behavior.
Tool
A tool is an external capability the system can call. Examples include search, database lookup, PDF parsing, currency conversion, code execution, or a domain-specific booking service. Tool use should be understood as system composition, not as a magical property of the model.
Retrieval
Retrieval is the process of selecting relevant external information for a task. That information might come from document stores, databases, booking records, or indexed partner agreements. Retrieval matters because useful enterprise answers often depend on data that should not be assumed to live inside model parameters.
Validation
Validation is any explicit check applied before the answer is accepted or shown. It is a first-class design component, not a cosmetic afterthought. In later posts, we will break validation into concrete pipeline checks and workflow contracts.
State
State is the information the system keeps while doing work. That might include the current task stage, selected documents, extracted fields, or user constraints. In this post, state is just the minimal concept that some work spans multiple steps. Later posts will separate state from memory and durable knowledge more carefully.
What Counts as an LLM System
Even a modest production application usually has more structure than "user prompt in, model text out." A minimal LLM system often looks more like this:
Accept and interpret the user request.
Decide whether the task needs external data or a tool.
Gather or prepare the needed context.
Call the model with a bounded role.
Check whether the result can be used.
Format the answer for the user or downstream service.
That is still a simple system. But it is already different in kind from a single prompt. The system has boundaries, explicit responsibilities, and places where failure can be detected.
This matters because application capability is often a system property. A model may be good at summarizing text, while the system is good at answering questions over internal partner contracts and booking records with citations and rate checks. Those are not the same claim. One belongs to the model. The other belongs to the architecture around it.
From Monolithic Models to Compound Systems
The early mental model for many AI products was straightforward: choose the strongest available model, write a better prompt, and let the model do more of the work. That framing was useful for experimentation, but it breaks down as tasks become knowledge-intensive, compliance-sensitive, or operationally messy.
The architectural shift is toward compound systems. Instead of expecting one model invocation to solve the entire problem, teams decompose the work:
retrieval fetches relevant evidence
extraction converts documents into usable inputs
deterministic logic handles known transformations
model steps synthesize or interpret ambiguous material
checks decide whether the result is usable
This is not a retreat from model capability. It is a more realistic use of it. The model remains central, but it is given a narrower and more defensible role inside a larger workflow.
Research across the last few years supports this direction. Retrieval-augmented generation made the distinction between model knowledge and external knowledge access explicit. Tool-use work showed that language models can be embedded inside systems that call outside functions. ReAct-style approaches demonstrated the value of interleaving model-driven steps with external actions. Broader systems framing, including recent work on compound AI systems, made the pattern harder to ignore: many practical gains now come from composition, not just scale.
For technical leaders, the implication is direct. If a use case depends on freshness, private data, provenance, structured outputs, or repeatable workflows, then the design discussion has to expand beyond model selection.
The Main Components Around the Model
The exact architecture varies by product, but a few components show up repeatedly in real systems.
Input and routing
The system needs to classify the request and send it down the right path. A general explanatory question may only need a model. A question about a specific booking or partner contract probably needs retrieval and evidence formatting. A document-heavy question may need extraction first.
Data access
Many high-value tasks depend on information outside the base model: partner contracts, booking databases, PDF agreements, accessibility specification sheets, or current rate information. If the system cannot access that data, the answer quality is capped no matter how strong the model is.
Extraction and transformation
Documents are rarely ready for immediate synthesis. Rate tables may need parsing, field names may differ across sources, currencies may need conversion, and property photos may need to be linked back to room descriptions or accessibility notes. These are architectural tasks, not prompt flourishes.
Model inference
The model is used where probabilistic interpretation helps: summarizing evidence, comparing options, drafting explanations, or converting semi-structured information into a target format. The important point is that the model should do the part it is well suited for, not all possible parts by default.
Validation and guardrails
A system should be able to reject or constrain outputs that do not satisfy known requirements. If a comparison must cite sources, the answer should fail without them. If a rate field requires a numeric value in a standard currency, the output should be checked before it is trusted.
Presentation and provenance
Users often need more than an answer. They need to know where it came from, what evidence was used, and where uncertainty remains. In travel planning, provenance is often part of the product requirement, not an optional feature.
Running Example: The OptiVerse Travel Copilot
Now apply the architecture shift to the travel copilot.
The user asks whether an accessible 10-day Japan trip for a family of four can be built within a $13,000–$15,000 budget during cherry blossom season, and whether the Kyoto hotel partner still honors the contracted wheelchair-accessible rate under Contract KYO-H12, Clause 4.3. A model-only design runs into immediate problems:
internal booking data for JPN-2026-0417 may not exist in the prompt context
the relevant partner contract may contain the needed rate evidence inside a table or clause, not plain text
the hotel property may be referred to by variant names across booking systems
prices and availability windows may be stored in inconsistent formats
the user needs an evidence-backed answer, not a fluent guess
A compound system can break the task into narrower responsibilities.
First, a routing step identifies the request as a grounded comparison task rather than a generic chat question. Then retrieval gathers candidate partner contracts, rate sheets, and accessibility specification sheets. If key evidence is buried in PDFs, an extraction path pulls out the relevant rate table fields, clause references, and photo set ACC-09 for wheelchair-accessible room verification. A normalization step reconciles naming and currency differences. Only then does the synthesis model compare the contracted rates with current seasonal pricing and draft a response. The point is not the exact pipeline. The point is that useful behavior comes from coordinated components rather than from one oversized model prompt.
The result is still an AI application built around models. But its useful behavior comes from the composition:
the retriever brings in the right evidence
the extraction path turns messy documents into usable inputs
the control layer keeps the sequence coherent
the synthesis step interprets the evidence
the surrounding system decides whether the output should be accepted
That is the practical meaning of a compound AI system. The model is not replaced. It is situated.
Monolithic Versus Modular Thinking
It is tempting to think of this as a temporary workaround until models get better. That is the wrong framing for many engineering contexts.
A more capable model may reduce how often a system needs special handling. It does not eliminate the need for system boundaries. Private data still requires access controls. Fresh information still requires retrieval or another external source. Structured business processes still require orchestration. High-stakes use still requires evaluation and validation.
Modular design also improves debuggability. When a travel copilot answer is wrong, the team can ask useful questions:
Was the wrong contract or rate sheet retrieved?
Did the table parser miss a column?
Did currency conversion fail?
Did the synthesis step overstate weak availability evidence?
Did validation fail to catch a missing source?
Those questions are much harder to answer in a monolithic "just prompt the model harder" approach. Modular systems are not automatically simpler, but they are often easier to inspect, test, and improve.
Common Misconceptions and Failure Modes
The shift to compound systems is easy to misread. A few misconceptions show up repeatedly.
Misconception 1: A better model removes the need for system design
Stronger models help, but they do not remove architectural requirements. If the task needs proprietary data, evidence tracking, or schema guarantees, a model upgrade does not make those concerns disappear.
Misconception 2: Prompt engineering is the main path to system quality
Prompts matter, but they do not substitute for architecture. A prompt can improve behavior inside a step. It rarely substitutes for the step itself.
Misconception 3: Any multi-step AI workflow is an agent
Not every composed system is agentic. Many useful AI products are mostly pipelines with selective model calls and deterministic control logic. In this post, that distinction stays intentionally narrow. Later posts will describe assistants, agents, and autonomy boundaries with more precision.
Misconception 4: Retrieval and validation are optional add-ons
For many production tasks, they are core architecture. Without retrieval, the system may answer from stale or irrelevant knowledge. Without validation, it may present unsupported outputs with unjustified confidence.
Failure modes follow directly from these misconceptions:
answering tool-dependent questions without using the required tool
relying on stale or incomplete knowledge
failing to ground an answer in enterprise or private data
producing outputs that drift from required schemas or currencies
omitting provenance on claims that require evidence
failing to abstain when the system lacks sufficient support
These are system failures as much as model failures. That distinction is important because it tells you where to intervene.
That is the main architectural lesson of this post. Useful AI capability is often assembled. The system earns usefulness by separating concerns and giving each component a role it can actually perform.
What This Post Is Not
This post does not argue that every AI application needs a complex orchestration stack. Some tasks are simple enough for a direct model call with light formatting. The point is narrower: once a task depends on external knowledge, structured evidence, multi-step control, or verification, you are already in systems territory.
It also does not argue that compound systems are synonymous with agents. Agent loops are one design pattern inside the broader space of AI systems. They become relevant when the system needs flexible multi-step decision-making. Many useful applications do not start there.
Where the Series Goes Next
This architecture-first view sets up the rest of the series.
In Post 2, we will go deeper into reliable LLM pipelines and control logic: how to decompose work into stages, where deterministic workflows still win, and how explicit checks improve system reliability.
In Post 3, we will focus on grounding through retrieval-augmented generation. That post will explain how systems fetch relevant evidence, why provenance matters, and why a good application sometimes needs to say, "I don't know."
Later in the series, the evidence problem will widen again: once tables, figures, and page structure start to matter, retrieval becomes a document-intelligence problem, and once images themselves become evidence, the system moves into multimodal evidence handling.
Those topics are easier to understand once the core shift is clear: modern AI products are not just models. They are compound systems built around them.
Source Notes
This post draws on the following primary and practitioner sources:
BAIR. "The Shift from Models to Compound AI Systems." Core framing for modern AI applications as systems assembled from models, retrieval, tools, control logic, and validation. bair.berkeley.edu/blog/2024/02/18/compound-ai-systems
Lewis, P., Perez, E., Piktus, A., et al. "Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks." Primary reference for generation conditioned on retrieved external evidence rather than only model parameters. arxiv.org/abs/2005.11401
Schick, T., Dwivedi-Yu, J., Dessi, R., et al. "Toolformer: Language Models Can Teach Themselves to Use Tools." Reference for model-directed tool-use behavior as one ingredient in compound systems. arxiv.org/abs/2302.04761
Yao, S., Zhao, J., Yu, D., et al. "ReAct: Synergizing Reasoning and Acting in Language Models." Reference for interleaving language-model reasoning traces with actions and observations. arxiv.org/abs/2210.03629
National Institute of Standards and Technology. "Artificial Intelligence Risk Management Framework: Generative Artificial Intelligence Profile." System-level risk, evaluation, and trustworthiness framing for generative AI deployments. nist.gov/publications/artificial-intelligence-risk-management-framework-generative-artificial-intelligence
Huang Tzu Lin
With over five years in autonomous robotics, there's a strong passion for incorporating cutting-edge technologies and innovative approaches. Dedicated to transforming the latest research and insights into practical applications, this journey pushes the limits of possibility.
Related Posts
Stay Updated
Get the latest technical insights delivered to your inbox.