Building the Travel Copilot: End-to-End Architecture, Approval Gates, and Auditability
Reading order
Document & Multimodal Intelligence
Next chapter
No adjacent chapter
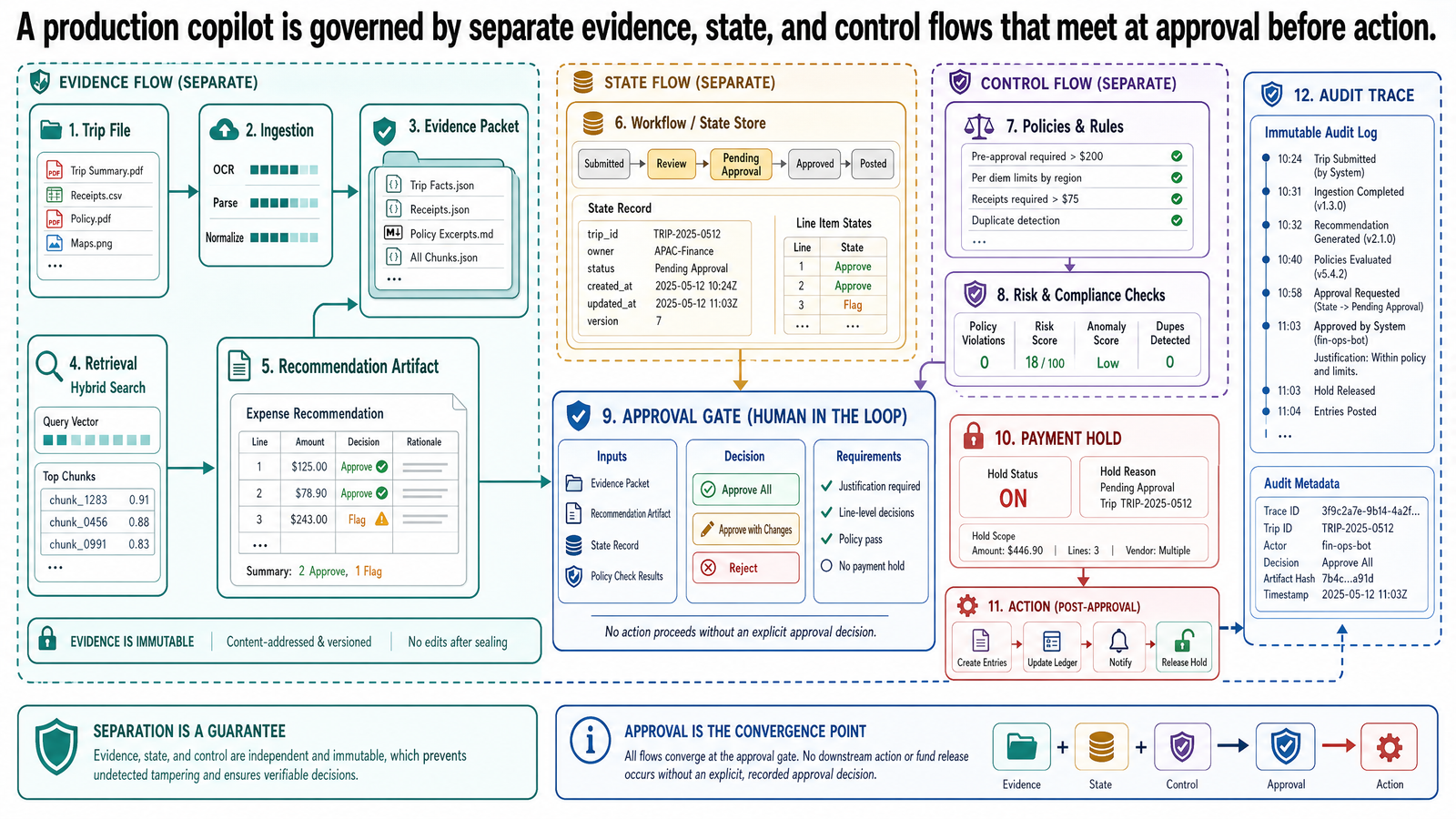
Table of Contents
- The End-to-End Architecture Problem
- The Organizing Triad: Evidence Flow, State Flow, and Control Flow
- Evidence Flow
- State Flow
- Control Flow
- How Ingestion, Retrieval, Working Memory, and Tool Use Fit Together
- 1. Ingestion creates the authoritative raw inputs
- 2. Document intelligence reconstructs structure
- 3. Multimodal evidence handling preserves visual support
- 4. Retrieval assembles the bounded evidence packet
- 5. Working memory holds the active packet and intermediate comparisons
- 6. Tool use operates over explicit contracts
- Approval Gates Are Part of the Architecture
- Describe, Recommend, Act
- Describe
- Recommend
- Act
- Running Example: One End-to-End Travel Copilot Run
- Auditability Requires Replayable Traces, Not Just Final Citations
- Common Failure Modes in the Capstone Architecture
- A Production Review Checklist
- The Series Conclusion: Operational Rigor Is the Real Maturity Test
- Source Notes
By the time a team reaches an advanced AI travel copilot, the hard question is no longer "Which model should we use?" It is "What has to happen, in what order, with what evidence, with what state, and under whose approval before this system can be trusted in production?" That is an architectural problem. A model sits inside it, but it does not solve it.
Consider the running example from this series: a multimodal travel-planning copilot for OptiVerse Travel, a mid-size agency specializing in custom itineraries. A client asks:
Plan a 10-day accessible Japan trip for cherry blossom season — family of four, one wheelchair user — within a $13K–$15K budget. Include the relevant contract rates, accessibility evidence, and produce a recommendation memo with the most defensible itinerary.
That request is already larger than a generation task. The system must ingest and parse partner documents, recover contract rate tables and accessibility certifications, retrieve best options matching accessibility plus budget plus dates, assemble a trip file, build an itinerary with an evidence trail, run a budget check, and stop at explicit approval boundaries — client sign-off before booking, payment authorization before any charge. If any of those responsibilities are vague, the system may still produce a fluent answer, but it will not be a production-ready travel system.
This capstone post brings the series together through two organizing frames. The first is the architectural triad evidence flow, state flow, and control flow. The second is the output ladder describe -> recommend -> act. Those are not presentation devices. They are practical boundaries for designing a system that remains grounded, reviewable, and operationally safe as capability increases.
The claim here should also stay disciplined. This is an architecture pattern for governed travel copilots, not a claim that one generic agent can safely automate the full trip-planning workflow end to end. The point is to show how bounded retrieval, tool use, approval gates, and replayable traces combine into a system that can support travel planning without pretending uncertainty has disappeared.
Disclaimer: All companies, characters, bookings, and figures in this post are fictional. OptiVerse Travel is not a real travel agency.
The End-to-End Architecture Problem
The simplest way to misunderstand an advanced copilot is to treat it as a chat interface with more tools. In production, the system boundary is much wider.
An end-to-end travel copilot usually needs at least these layers:
ingestion for partner contracts, rate tables, accessibility audits, destination guides, and property photos
document-intelligence pipelines that recover layout, tables, figure links, and document hierarchy
retrieval over text, tables, metadata, and visual artifacts
working memory that holds the bounded trip file for the active planning task
tool use for search, extraction, comparison, normalization, and budget analysis
synthesis steps that produce an options summary, a recommended itinerary, or an abstention
approval gates before consequential downstream actions — client sign-off before booking, payment authorization before charges
trace and logging infrastructure that records what the system saw, did, decided, and handed off
This is why the capstone architecture should be read as a compound system, not as an agent prompt. Posts 1 and 2 established that useful systems decompose work into stages with explicit control logic. Post 5 sharpened this into a design question — who controls the next step — and introduced the describe/recommend/act ladder that this capstone makes concrete. Posts 3, 4, and 7 separated grounded retrieval, durable knowledge, task state, and bounded working context. Posts 5 and 6 clarified that tool-using agent behavior is a control pattern, not a license for unbounded autonomy. Posts 8 and 9 showed that document and multimodal evidence are architecture layers in their own right. The final step is to make those layers work together under operational constraints.
The Organizing Triad: Evidence Flow, State Flow, and Control Flow
The easiest way to reason about a production copilot is to separate three flows that often get collapsed in prototypes.
Evidence Flow
Evidence flow is the path by which source material becomes usable support for an answer or recommendation.
In the Japan trip example (JPN-2026-0417), evidence flow starts before the question is asked. The system ingests partner contracts, hotel rate cards, airline accessibility policies, wheelchair-taxi availability sheets, destination photos, and accessibility audit reports. The document layer extracts structure rather than only text: sections, tables, captions, photo regions, page layout, and source metadata. The multimodal layer preserves image evidence and the links between property photos, accessibility certifications, nearby descriptions, and booking identifiers. Retrieval then selects a task-specific subset — retrieve broadly across all partner data, reason locally within the trip file. The result is not "all context." It is a bounded evidence packet assembled for one itinerary.
That packet might include:
three accessible hotel options in Kyoto matching cherry blossom dates, drawn from Contract KYO-H12
two airline rate comparisons for JAL and ANA with wheelchair assistance details
extracted rate tables with pricing tiers normalized to USD
property photos and accessibility certification images linked to booking metadata (Photo set ACC-09)
JR Pass pricing and wheelchair-taxi availability records for the Kansai and Kanto regions
provenance pointers back to the source contract clauses, rate table cells, photo IDs, and record IDs
If those links are weak, the rest of the system is weak. A final paragraph with citations is not enough if the architecture cannot show which artifacts were retrieved, which were dropped, which were transformed, and which actually supported the recommendation.
State Flow
State flow is the path by which the system tracks what task it is performing, what intermediate products exist, and what working context is active.
This is not the same thing as evidence flow. Evidence is about source support. State is about process.
For the same JPN-2026-0417 request, the system may hold:
the active trip ID and client identity
the current workflow stage
the evidence-packet ID selected for this run
unresolved gaps such as missing wheelchair-taxi confirmation for Hakone
intermediate outputs such as a structured budget comparison table
approval status for the recommendation and booking stages
State matters because advanced workflows span many steps and often branch. A system that cannot track whether it is still working from the current trip file, whether a rate-table extraction has been validated, or whether an itinerary already passed client review is vulnerable to subtle failures that look like reasoning mistakes but are actually state-management mistakes.
This is also why working memory should remain bounded and temporary. The active packet for JPN-2026-0417 is useful for the current itinerary build. It is not a durable knowledge base, and it should not silently become one.
Control Flow
Control flow is the path by which the system decides what happens next. In this architecture, who controls the next step is never left to the model's discretion — it is defined by explicit decision boundaries.
Control flow determines:
when ingestion must run before retrieval
when extraction quality is sufficient to continue
which tool may be called, with what schema, and under what validation rules
when a synthesis step is allowed to generate a recommendation
when the workflow must stop, abstain, retry, or escalate to a human reviewer
In early prototypes, control flow is often hidden inside prompts. In production, that is too opaque. The application needs explicit decision boundaries because those boundaries determine reliability, latency, cost, and operational risk.
Once the triad is explicit, system design becomes easier to debug. If an itinerary cites the wrong rate, the failure may be in evidence flow. If the system used last month's rate card after new contracts arrived, the failure may be in state flow. If the system issued a booking confirmation before the client signed off, the failure may be in control flow. Those are different failures and need different fixes.
How Ingestion, Retrieval, Working Memory, and Tool Use Fit Together
The architecture becomes concrete when traced as a run rather than as a component list.
1. Ingestion creates the authoritative raw inputs
The system receives a stream of materials: partner contract PDFs, rate-card spreadsheets, accessibility audit reports, property photos, destination guides, and airline policy documents. Ingestion assigns stable record identifiers, stores source metadata, calculates checksums, and records access-control attributes. At this stage, the system is not answering anything yet. It is establishing the authoritative inputs from which later evidence can be derived.
The key architectural point is that ingestion should preserve identity and provenance early. If a rate extracted later cannot be linked back to a source contract and document position, the trace is already broken.
2. Document intelligence reconstructs structure
The next layer turns raw files into structured evidence objects. For PDFs and scanned contracts, this means OCR where needed, layout recovery, reading order, table reconstruction, caption linking, section segmentation, and document splitting when one file contains multiple logical documents. For internal records, it may mean schema normalization and entity resolution across trip IDs, contract IDs, and property identifiers.
This layer carries forward the main lesson of Post 8: document intelligence is not an optional preprocessing convenience. It determines whether later retrieval can distinguish a rate-table header from a body cell, a photo caption from unrelated text, or a contract appendix from the main terms.
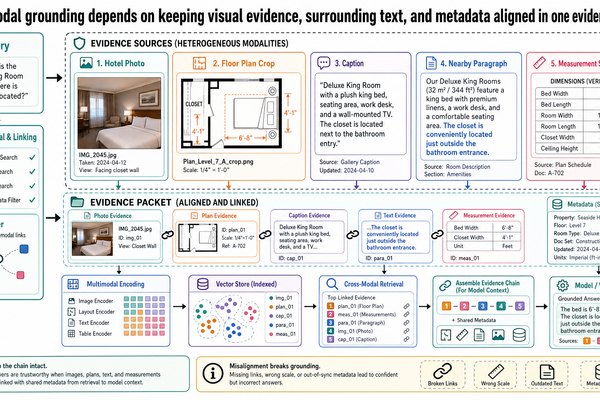
3. Multimodal evidence handling preserves visual support
The system should not flatten images into afterthoughts. Property photos, accessibility certification images, and page renderings need their own identifiers and links to captions, nearby description, and booking metadata. This is where the main lesson of Post 9 enters the capstone: visual evidence must remain aligned with the rest of the travel record.
For JPN-2026-0417, that means the system can retrieve not only text passages about accessible rooms, but also the specific property photos and accessibility certification images (Photo set ACC-09) that support a suitability comparison.
4. Retrieval assembles the bounded evidence packet
Retrieval is the bridge from the broad corpus to the active task. A good production pattern is hybrid: retrieve broadly over the indexed corpus, then reason locally by assembling a bounded trip file for the planning workflow. The packet should be small enough to review and reason over, but rich enough to preserve the decisive evidence.
Typical retrieved artifacts for this task might include:
prior itineraries with similar accessibility requirements or cherry blossom timing
sections of partner contracts discussing accessible-room availability and cancellation terms
extracted rate tables with seasonal pricing and wheelchair-assistance surcharges
property photos and accessibility certifications tied to specific hotels
airline policies that constrain whether the wheelchair-assistance options are truly comparable
This is where freshness and permissions matter. If retrieval ignores the newest partner contract or surfaces rates the travel agent should not yet quote, the system has failed before generation begins.
5. Working memory holds the active packet and intermediate comparisons
Once retrieved, the trip file becomes working memory for the current task. The system may enrich it with normalized budget breakdowns, open questions, and intermediate judgments such as "accessible room confirmed at Kyoto property but Hakone wheelchair-taxi availability incomplete." That is useful temporary state. It is not durable truth.
Keeping this packet explicit has two benefits. First, it gives the synthesis layer a narrower, more defensible context window than a general corpus dump. Second, it gives audit and review processes something concrete to inspect after the run.
6. Tool use operates over explicit contracts
Tool use fits here as a controlled extension of the workflow, not as a free-form display of autonomy. The model may be allowed to call:
retrieval services
rate-table comparison tools
currency-conversion and budget-normalization functions
availability-check services
image-analysis or photo-cropping utilities
itinerary-assembly templates
Each tool should expose a clear contract: allowed arguments, structured outputs, validation rules, and failure responses. Tool calls that produce malformed outputs or ambiguous rate matches should not flow silently into downstream synthesis. They should fail closed, retry with constraints, or route to review.
This is where production systems separate themselves from demos. A tool call is not just a convenience. It is part of the control surface of the application.
Approval Gates Are Part of the Architecture
Approval gates are often described as governance or policy. That framing is incomplete. In a production copilot, approval gates belong in the architecture because they shape control flow, data flow, user experience, and downstream integration.
An approval gate is a designed stop point where the system may prepare an output for review but may not advance to the next consequence without an explicit approval event. That event should be tied to a role, an identity, a policy, and a record in the trace.
For the travel copilot, approval gates typically belong at transitions like these:
from options summary to recommended itinerary publication
from recommended itinerary to booking execution (client sign-off)
from booking confirmation to payment charge (payment authorization)
from internal trip memo to client-facing delivery or partner notification
This matters because not all outputs have the same operational weight. A descriptive options summary is usually informational. A recommended itinerary starts to influence commitments. A booking action changes the world — it reserves rooms, holds seats, and charges cards.
If the team treats approval as something bolted on after the agent is built, several problems appear immediately:
the UI may not preserve the intermediate artifact that a reviewer needs to inspect
the trace may not record which trip file supported the itinerary being approved
the action path may already be wired to booking APIs with no clean pause point
the user may not know whether they are reviewing evidence, advice, or a booking request
That is why the series ends on a harder standard than "human in the loop." The useful question is not merely whether a human can intervene. It is whether the workflow has explicit architectural pause points before consequential transitions.
Describe, Recommend, Act
The most practical control boundary in advanced copilot design is the ladder describe -> recommend -> act.
Describe
Describe means the system summarizes, extracts, compares, or explains evidence. It may answer questions like:
What accessible hotel options in Kyoto match our cherry blossom dates under Contract KYO-H12?
Which rate tables and property photos are relevant to this suitability comparison?
Where do the airline wheelchair-assistance policies align or diverge between JAL and ANA?
Descriptive output can still be wrong and still needs grounding, but it does not by itself change a downstream system or commit the agency to a course of action.
Recommend
Recommend means the system proposes a next step based on the available evidence. For example:
The most defensible itinerary is a 10-day route through Tokyo, Hakone, Kyoto, and Osaka, using JAL with pre-booked wheelchair assistance, because current contract rates and accessibility audits confirm availability within the $13K–$15K budget window, though Hakone wheelchair-taxi confirmation remains pending.
This is materially different from description. The system is now moving from evidence presentation to decision support. That usually requires stronger sufficiency checks, clearer uncertainty language, and a visible approval boundary before the output can drive booking decisions.
Act
Act means the system changes something outside the current reasoning context. Examples include:
placing a hotel reservation
booking airline seats with wheelchair assistance
charging the client's payment method
sending a booking confirmation to partner hotels
updating the agency's system-of-record with committed itinerary details
This is the highest-risk class because the output is no longer just informative. It is consequential.
The core rule for many production systems should be simple:
the system may autonomously
describeit may conditionally
recommendit should not automatically
acton consequential workflows without explicit policy, scoped permissions, and an approval event
Different organizations will set different thresholds, but collapsing these classes into one is a design mistake. A strong descriptive summary does not justify booking rights. A plausible itinerary recommendation is not equivalent to an approved booking.
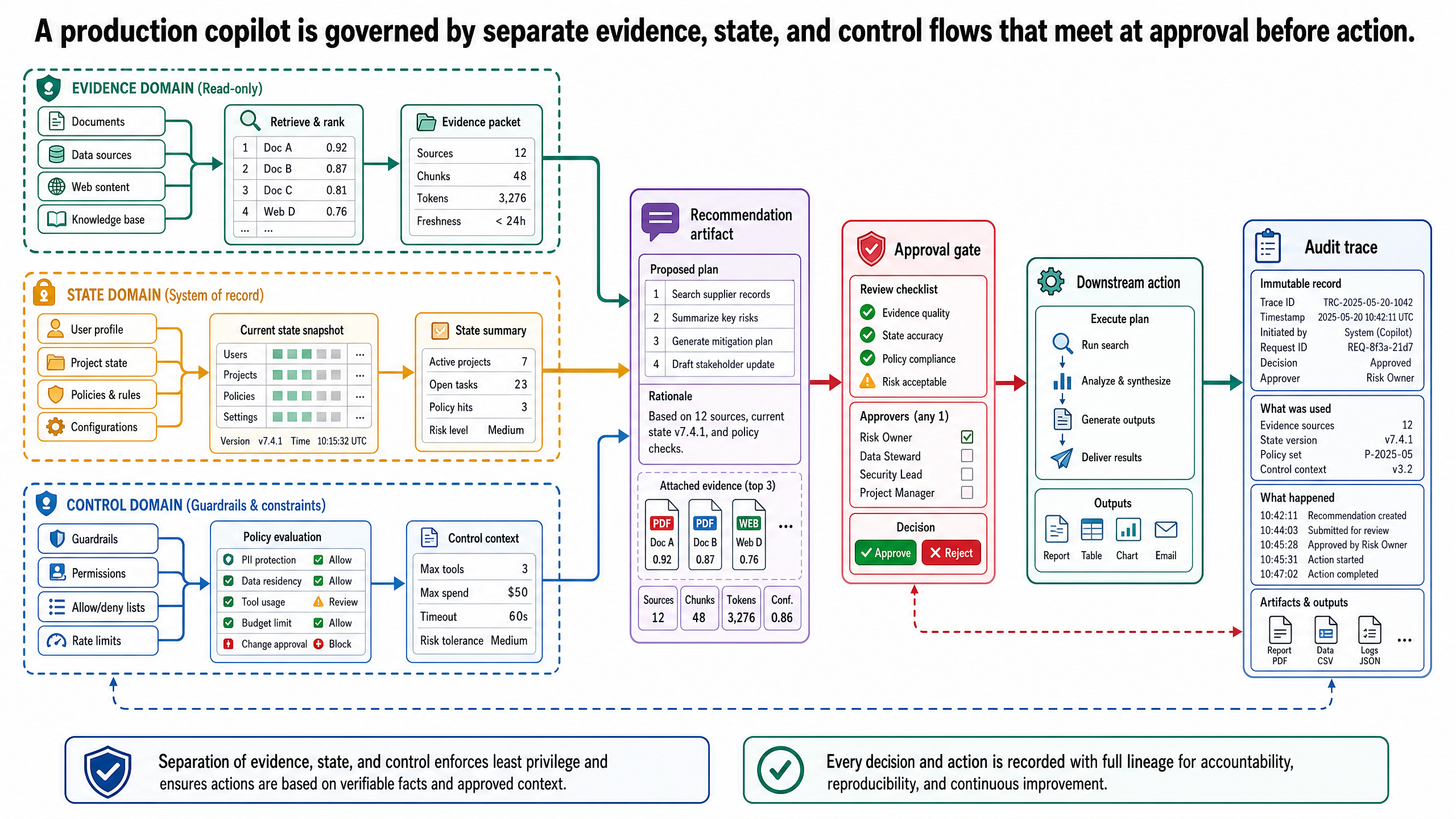
Running Example: One End-to-End Travel Copilot Run
Now consider the full run for the JPN-2026-0417 request.
The client asks for a 10-day accessible Japan itinerary, a comparison of partner options matching accessibility and budget constraints, relevant rate tables and property evidence, and the most defensible recommended itinerary. The system starts by resolving the request into a workflow: gather relevant partner documents, reconstruct structured evidence, compare against budget and accessibility criteria, synthesize an options summary, assess whether evidence is sufficient for a recommendation, and stop at approval before any downstream booking action.
The ingestion layer already holds the relevant corpus: partner contracts, airline policy documents, rate-card spreadsheets, accessibility audit reports, and property photos. The document-intelligence layer has reconstructed rate tables, contract clauses, photo regions, and section boundaries. The multimodal layer has preserved the links between property images, accessibility certifications, and booking metadata.
Retrieval then assembles a trip file for this specific run. It pulls three accessible Kyoto hotel options from Contract KYO-H12, two airline rate comparisons for JAL and ANA with wheelchair-assistance details, a rate table showing cherry blossom seasonal pricing, property photos and accessibility certifications for the shortlisted hotels (Photo set ACC-09), and JR Pass and wheelchair-taxi records establishing that only the Kyoto and Tokyo legs have fully confirmed accessibility at this time.
At this point the system can describe. It produces an options summary that:
presents the accessible hotel, flight, and transport options with contract-backed rates
identifies which options meet all accessibility requirements and which have gaps
cites the supporting contracts, rate-table extractions, and property photo artifacts
states any important gaps, such as incomplete wheelchair-taxi confirmation for the Hakone leg
The budget breakdown at this stage might show: flights $4,000–$6,000 (JAL/ANA, wheelchair assistance), accommodation $3,000–$4,500 (accessible rooms, cherry blossom premium), transport $1,800–$2,800 (JR Pass plus wheelchair taxis), food $1,500–$2,000, activities $500–$1,000, miscellaneous $400–$600, totaling $13,000–$17,000 — noting that the client's $13K–$15K target requires mid-tier options.
Before moving further, control logic checks whether recommendation criteria are met. Are the key evidence links present? Are the retrieved contracts current and access-valid? Are the normalized rate tables validated? Is the accessibility comparison still materially ambiguous? If these checks fail, the system should stop at description or return a limited recommendation with explicit uncertainty. It should not manufacture decisiveness from partial evidence.
Suppose the checks pass with caveats. The system can now recommend: it proposes a 10-day itinerary that best balances accessibility, cherry blossom timing, and budget while noting which evidence is strongest and which assumptions remain open. That recommendation is packaged with the trip-file ID, source references, comparison artifacts, and uncertainty notes.
Now the first approval gate matters. The system does not place any booking on its own. The client sees:
the descriptive options summary
the recommended itinerary text
the exact trip file used
the budget breakdown and linked property photo artifacts
the unresolved gaps and validation warnings
the bookings that would be triggered if approved
Only after the client signs off can the system proceed. But even then, a second approval gate intervenes before payment authorization — the agent verifies final booking details against the approved itinerary, total charges against the agreed budget, and what was promised versus what will actually be booked. Only after payment authorization can the system act, such as placing hotel reservations, booking flights, and confirming wheelchair-taxi services. Each approval event becomes part of the trace. Without those events, the system stops at a recommendation artifact, not an operational change.
That is what it means to make approval architectural. The client is not reading a detached paragraph in an email. They are reviewing a controlled artifact tied to evidence, state, and the next possible consequence — the system describes options, recommends an itinerary, and acts only with explicit sign-off.
Auditability Requires Replayable Traces, Not Just Final Citations
Many teams assume an answer is auditable if it includes citations. That is too weak.
Final citations help with user-facing provenance, but auditability is a system property. To review a consequential run after the fact, the team usually needs to reconstruct at least five things:
what evidence the system selected
what state the workflow was in at each stage
what tools were called and what they returned
what outputs were produced at each class of the ladder
who approved what before a consequential action
That means a replayable trace should typically include:
request ID (JPN-2026-0417), client identity, and time
corpus versions or source record identifiers (Contract KYO-H12, Photo set ACC-09)
trip-file ID and membership
retrieval results and reranking or selection records
extracted rate-table, contract-clause, and photo artifact IDs
tool invocations with arguments, outputs, and validation status
workflow state transitions
model output class such as
describe,recommend, oract-requestapproval events with reviewer identity, timestamp, and decision (client sign-off, payment authorization)
downstream booking records if an action was executed, including promised-versus-booked reconciliation
Not every system needs byte-for-byte deterministic replay. Many AI systems cannot provide that in a strict sense. But a production system should still support practical replay: enough traceability to understand which sources, transformations, and decisions produced the final artifact.
This is also where the limits of "store the final prompt and answer" become obvious. That record omits the retrieved evidence set, the rate-table and photo artifacts, the intermediate comparison objects, the tool calls, the state transitions, and the approval history. It is useful debugging residue, not a sufficient audit trail.
Common Failure Modes in the Capstone Architecture
The capstone design fails in recurring, predictable ways.
One failure is weak source linking. The final itinerary cites a hotel name, but the system cannot show which extracted rate-table cells or accessibility photo artifacts actually supported the recommendation. Another is stale state. A recommendation is generated from a trip file assembled before a new partner contract with better rates arrived. A third is collapsed output classes: the UI presents a recommended itinerary as if it were already an approved booking. A fourth is incomplete trace capture: document and multimodal artifacts were used during synthesis but never recorded in the audit trail.
There are also workflow failures. Tool outputs may enter downstream logic without validation. Approval ownership may be unclear. A client may approve the itinerary text without seeing the trip file that justified it. A booking pathway may be technically available from the same surface that was meant only for descriptive trip-planning support.
None of these are exotic model failures. They are architectural failures. Better models may make them less visible for a while because the outputs look more coherent. They do not remove the need to design around them.
A Production Review Checklist
Before shipping a travel copilot with recommendation or booking pathways, a technical team should be able to answer these questions clearly.
Do we know the exact authoritative sources this system may ingest, and are stable source identifiers preserved from ingestion onward?
Can the document layer recover the structures that matter for the task, including rate tables, contract clauses, photo links, and logical document boundaries?
Can the multimodal layer preserve property photos and accessibility evidence as first-class artifacts rather than flattening them into weak text?
Is retrieval bounded by permissions, freshness, and task relevance rather than only embedding similarity?
Does each run create an explicit trip file for the active planning task?
Is working memory treated as temporary task context rather than durable knowledge?
Are tool contracts explicit, schema-validated, and recorded in the trace?
Are evidence sufficiency checks defined before the system is allowed to move from
describetorecommend?Is there a visible architectural pause point before any consequential
actstep, including both client sign-off and payment authorization?Is reviewer identity, decision, and timestamp recorded for each approval event?
Can the team reconstruct which sources, artifacts, tool calls, and state transitions produced a given itinerary recommendation?
Are abstention and exception paths defined when evidence is incomplete, conflicting, or stale?
Does the UI make the output class obvious to the user: description, recommendation, or booking request?
Are downstream integrations scoped so that unapproved outputs cannot silently trigger real-world bookings or charges?
Has the team tested failure cases involving stale trip files, broken provenance links, malformed tool outputs, and missing approvals?
Is there a policy for model versioning and behavior-drift risk? Swapping or updating the underlying LLM or VLM can change system behavior in ways that are not captured by the evidence or control layers alone.
Has the team addressed security and adversarial robustness? Prompt injection, data poisoning, and adversarial inputs are production concerns that complement the evidence and auditability architecture described here.
Has fairness and bias evaluation been considered for any user-facing or decision-influencing outputs?
If several of these answers are vague, the system is probably still a promising prototype rather than a production-ready copilot.
The Series Conclusion: Operational Rigor Is the Real Maturity Test
This series started by separating models from systems. It ends by separating capability from operational maturity.
An advanced travel copilot is not defined by whether it can speak fluently about destinations, call booking APIs, or interpret property photos. Those capabilities matter, but they are not the final bar. The real maturity test is whether the system can move evidence through a bounded architecture, maintain the right state through a multi-step workflow, enforce the right control boundaries before recommendations and actions, and leave behind a trace that a human can review with confidence.
That is why the capstone standard is evidence flow, state flow, and control flow, organized around describe -> recommend -> act. If those boundaries are clear, the system can be powerful without becoming opaque. If they are vague, even an impressive model stack will remain hard to trust.
The core anchors throughout this series — "who controls the next step," "retrieve broadly, reason locally," and "describe -> recommend -> act" — are not slogans. They are design discipline. Each one answers a question that must be answered in production.
Operational rigor is not the part that comes after the interesting AI work. In production, it is the interesting AI work.
Source Notes
This capstone draws on the following primary, official, and practitioner sources:
BAIR. "The Shift from Models to Compound AI Systems." Core reference for the compound-systems framing used throughout the capstone. bair.berkeley.edu/blog/2024/02/18/compound-ai-systems
Anthropic. "Building effective agents." Practitioner reference for bounded complexity, checkpoints, and explicit control boundaries. anthropic.com/engineering/building-effective-agents
OpenAI. "Structured model outputs." Official reference for schema-constrained outputs and model-computer boundary reliability. developers.openai.com/api/docs/guides/structured-outputs
OpenAI. "Conversation state." Official reference for application-managed state responsibilities. developers.openai.com/api/docs/guides/conversation-state
Lewis, P., Perez, E., Piktus, A., et al. "Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks." Reference for the retrieval layer feeding the evidence packet. arxiv.org/abs/2005.11401
Smock, B., Pesala, R., and Abraham, R. "PubTables-1M." Reference for table extraction and structured document evidence. arxiv.org/abs/2110.00061
Faysse, M., Sibille, H., Wu, T., et al. "ColPali," and Yu, S., Tang, Z., Zhang, Z., et al. "VisRAG." References for visually rich document retrieval and multimodal retrieval-augmented generation. arxiv.org/abs/2407.01449, arxiv.org/abs/2410.10594
National Institute of Standards and Technology. "Artificial Intelligence Risk Management Framework: Generative Artificial Intelligence Profile." Reference for traceability, oversight, evaluation, and trustworthy deployment language. nist.gov/publications/artificial-intelligence-risk-management-framework-generative-artificial-intelligence
Huang Tzu Lin
With over five years in autonomous robotics, there's a strong passion for incorporating cutting-edge technologies and innovative approaches. Dedicated to transforming the latest research and insights into practical applications, this journey pushes the limits of possibility.
Related Posts
Stay Updated
Get the latest technical insights delivered to your inbox.