Multimodal Evidence Systems: VLMs, Figure Grounding, and Cross-Modal Retrieval
Reading order
Document & Multimodal Intelligence
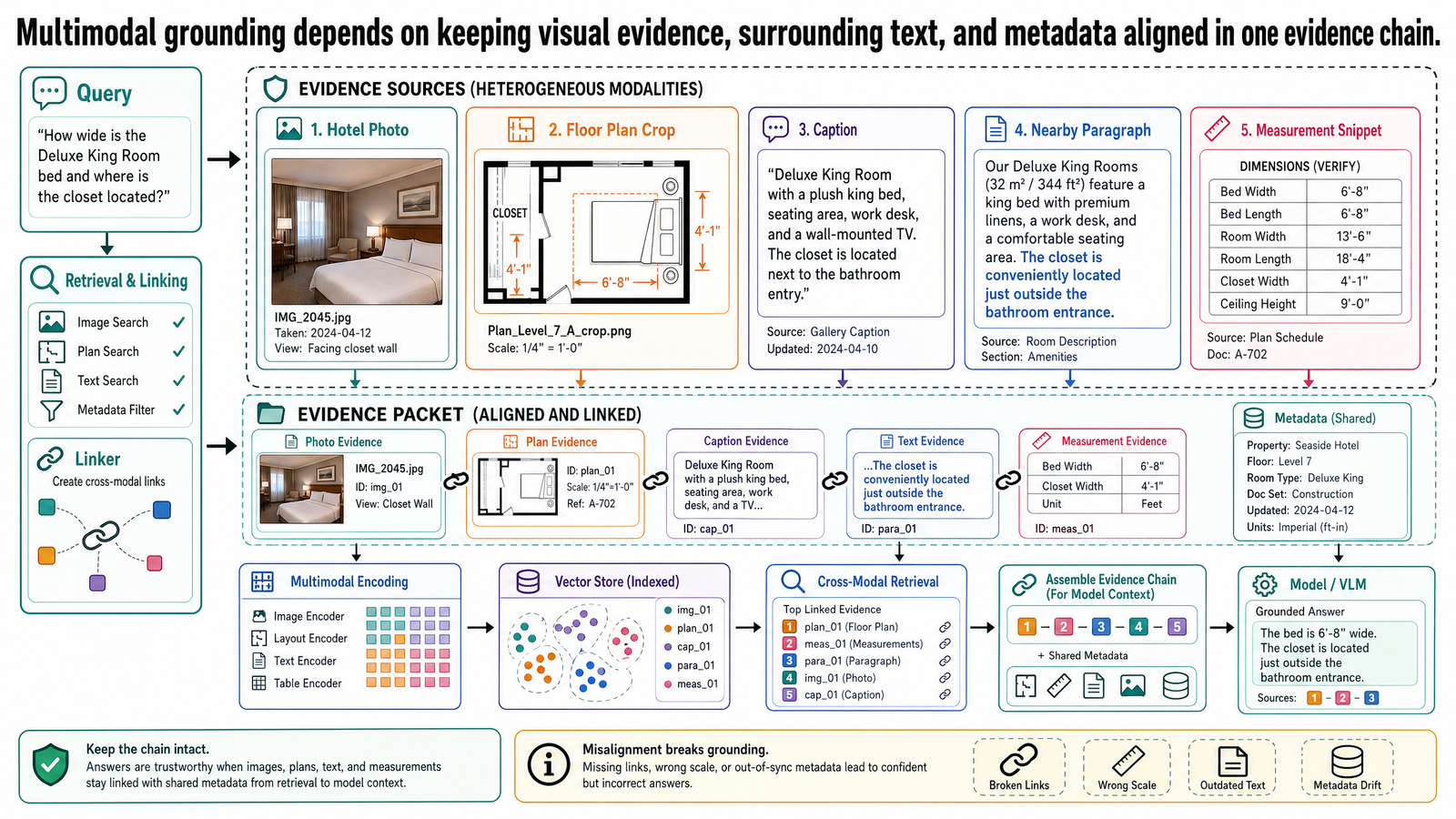
Table of Contents
- Why Visual Evidence Changes The Architecture
- What A VLM Is, In System Terms
- From Document Parsing To Figure Grounding
- Figure Grounding Requires More Than A Caption
- What Multimodal Retrieval Actually Means
- Running Example: An OptiVerse Travel Evidence Chain
- What This Post Is Not
- Common Misconceptions
- Failure Modes And Limits
- Practical Design Guidance
- What Still Needs Human Review
- Where This Fits In The Series
- Source Notes
Text-only systems break as soon as the evidence stops being mostly text, which is exactly what happens in accessible travel planning when photos, floor plans, route maps, captions, and measurements all shape the answer.
That sounds obvious, but it is still a common architectural mistake. An AI assistant may retrieve the right document, quote the right paragraph, and still miss the evidence that actually matters because the claim lives in a hotel photo, an architectural floor plan, a route map annotation, or a table tied to an accessibility audit image. In travel planning and accessibility verification, the conclusion often depends on how visual evidence, surrounding prose, and structured measurements fit together. If the system treats images as decorative attachments or reduces them to weak OCR text, it loses the chain of evidence.
That is why multimodal evidence systems are not just text systems with image upload support. They are systems built to align evidence across modalities while preserving provenance. In this post, the focus is not on flashy image-chat demos. It is on the practical systems problem: how to connect figures, captions, nearby discussion, tables, and measurements so a grounded answer remains reviewable.
This is also the right place to keep the claim narrow. The argument is not that current VLMs can independently verify accessibility compliance from images alone. The argument is that they can become useful components inside a stricter evidence-alignment system when figure structure, surrounding text, metadata, retrieval, and review boundaries remain explicit.
The running example is the same one used across this series: an OptiVerse Travel copilot for accessible trip planning. Here, multimodality is not optional. The agency works with hotel brochures, accessibility spec sheets, architectural floor plans, route maps with elevation profiles, and destination audit photos. A question about roll-in shower compliance, doorway width clearance, or wheelchair route feasibility may depend on what is visible in a photo and whether that visual evidence matches the written accessibility specifications for the same property.
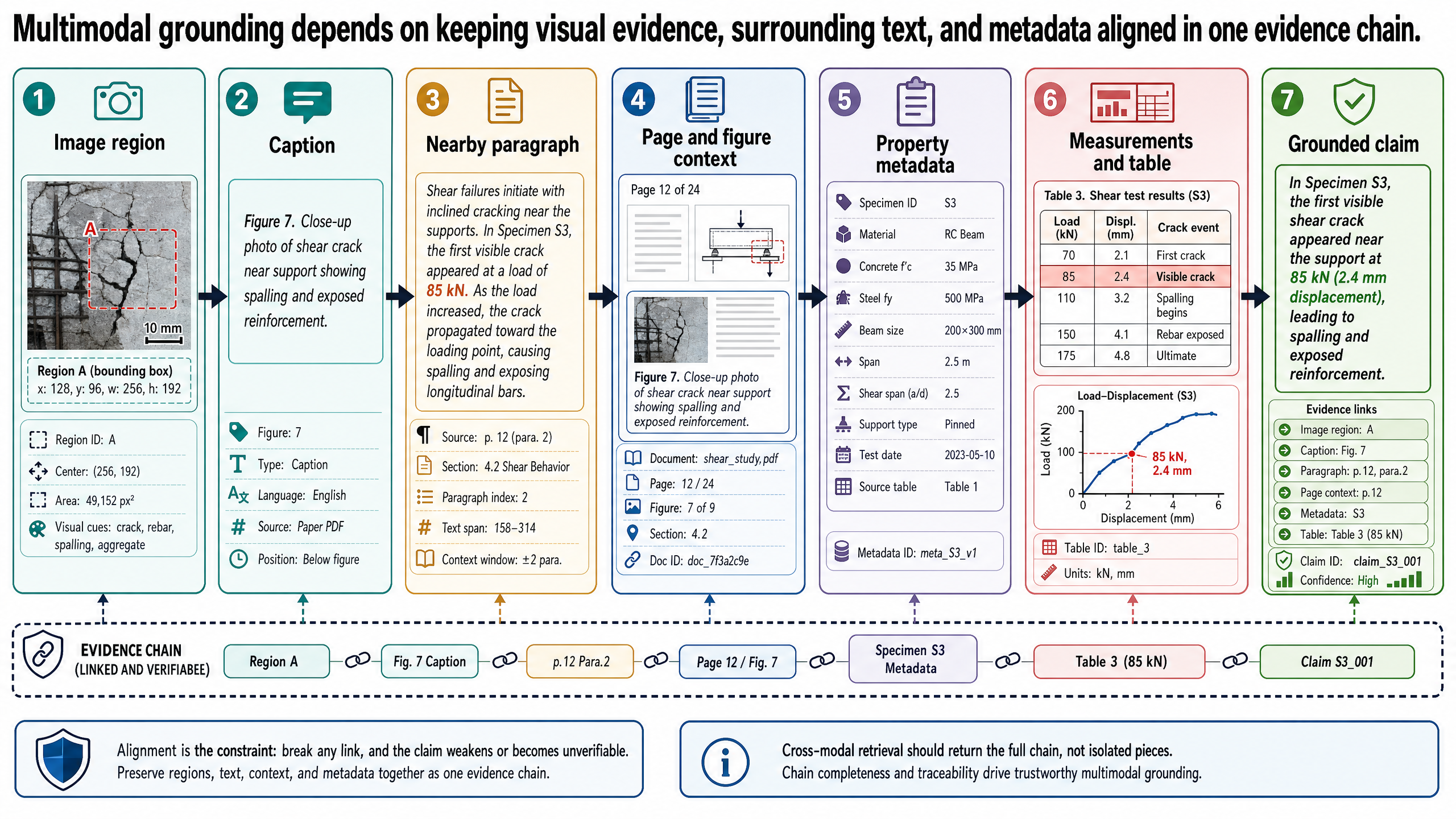
Why Visual Evidence Changes The Architecture
In earlier posts, the main challenge was getting reliable text and structured data out of documents, retrieving the right evidence, and keeping the synthesis grounded. That still matters. But once figures and images become first-class evidence, the architecture has to change in three ways.
First, retrieval can no longer assume that the best representation of a document is text alone. A visually rich page may carry important meaning in layout, floor plan structure, annotations, measurement labels, or image content. Second, grounding now requires cross-modal alignment. The system needs to know which image belongs to which caption, which surrounding paragraph explains the image, and which property metadata or accessibility specification corresponds to the depicted evidence. Third, synthesis must become stricter, not looser. A model may produce a fluent visual description, but a production evidence system still has to answer a narrower question: what evidence supports this claim, and what remains uncertain?
This is a useful distinction for technical decision-makers. The question is not whether a model can describe an image convincingly. The question is whether the system can maintain a defensible evidence chain from visual artifact to claim.
What A VLM Is, In System Terms
A vision-language model, or VLM, is a model that connects visual inputs and language so the system can interpret or generate language about images and visually rich documents. For this series, the important part is not the internal branding of a particular model family. The important part is that a VLM gives a system a way to map images and text into a shared or aligned representation space and to reason over visual content together with language.
That capability enables two different but related jobs:
understanding or describing visual input in language
matching text and images for retrieval, ranking, and grounding
Those jobs are often conflated. They should not be. A model that can produce a plausible caption for an image is not automatically reliable at accessibility evidence matching. Likewise, a system that can retrieve a relevant photo from a text query is not automatically able to draw a correct compliance conclusion from that photo.
For practical architecture, it helps to separate the layers:
Document intelligenceextracts document structure: pages, figures, captions, tables, sections, and layout relationships.VLM capabilityhelps interpret image content and encode visual pages or image regions in a way that can be aligned with language.Retrieval and rankingconnect text queries, image queries, page images, and structured metadata.Grounded synthesisproduces a bounded answer that cites which image, caption, paragraph, and measurements support the conclusion.
That separation keeps the system from collapsing into a vague idea that "the model sees the whole document." In production, each layer has different failure modes and different evaluation requirements.
From Document Parsing To Figure Grounding
Post 8 treated document intelligence as a first-class systems problem because OCR alone is not enough. That becomes even more important here. Before a multimodal system can reason over figures, it first has to recover the document relationships around them.
Figure grounding starts with structure:
where the figure is on the page
which caption belongs to it
whether the figure has multiple panels
which nearby paragraphs discuss it
whether there is a linked table or measurement summary
what metadata identifies the associated property, booking, or document section
Without that structure, the system risks making the oldest multimodal mistake: talking about the wrong thing with high confidence.
In an accessible-travel workflow, that mistake is easy to make. A hotel's documentation may contain several photos across multiple pages, each showing slightly different room types, angles, and accessibility features. If the system mis-pairs a photo with the wrong caption, or treats a nearby paragraph from another room category as explanatory context, the downstream answer may still sound coherent while being materially wrong.
So figure grounding is not a single model feature. It is an evidence-alignment task across image region, caption text, nearby discussion, document layout, and property metadata.
Figure Grounding Requires More Than A Caption
Captions matter, but captions are rarely sufficient on their own.
In technical documents, captions are usually compressed summaries. They often omit assumptions that the surrounding prose takes for granted. A caption may say that a photo shows "accessible bathroom with grab bars," but the details needed for interpretation may be distributed elsewhere: doorway width measurements, room type designation, ADA compliance tier, floor plan annotations, and a paragraph discussing why the shown configuration meets one accessibility standard and not another.
That is why a grounded multimodal system should repeatedly align four elements:
image: the visible evidence itself, including regions, room layout, fixtures, labels, and measurement annotationscaption: the explicit textual description attached to the figurecontext: nearby paragraphs, section headings, and references in the body textmetadata: property IDs, room categories, accessibility ratings, and linked specifications
That pattern matters more than any single model choice.
Consider a central accessible-travel question:
Does the hotel photo in photo set ACC-09 actually show a roll-in shower matching the accessibility spec sheet from Contract KYO-H12, and does that match the architectural floor plan measurements for the same room type?
No text-only system can answer this well unless the relevant visual evidence has already been reduced into perfect text, which is rarely true. The phrase "roll-in shower" depends on visible bathroom layout. The phrase "matching the accessibility spec sheet" depends on linking a hotel-provided photo to a specification document, its description, and compliance criteria. The phrase "match the architectural floor plan measurements" depends on joining the visual evidence to structured property records.
Even a strong VLM should not answer this from image content alone. The correct system path is narrower and more disciplined:
recover the spec sheet's figure region, caption, and nearby explanatory paragraphs from the parsed document bundle
locate the hotel-provided photo and its property metadata
retrieve the relevant floor plan measurements and accessibility ratings for the same room type
compare the published accessibility description with the actual photo under the correct dimensional and compliance metadata
produce a bounded conclusion that states what aligns, what does not, and where the evidence is ambiguous
The point is not to make the model "look harder." The point is to preserve the link between visual evidence and the rest of the verification record.
What Multimodal Retrieval Actually Means
Multimodal retrieval means the system can retrieve evidence across different modalities rather than only within one. In this post, the most practical version is cross-modal retrieval: a text query can retrieve images, figures, or visually rich document pages, and an image or page can help retrieve relevant text or related examples.
That is a meaningful architectural shift.
In a text-only retrieval stack, the system usually embeds chunks of text and returns the nearest matches for a text query. That works when the answer is mostly expressed in prose. It works less well when the decisive evidence is carried by image structure, floor plan design, route map layout, or page appearance that never survives parsing cleanly.
Cross-modal retrieval gives the system more than one path to evidence:
a text query can retrieve a page image because the page visually contains the relevant floor plan or photo
a text query can retrieve a hotel accessibility photo whose visual content aligns with the requested compliance feature
a figure or image can retrieve related paragraphs, captions, or internal property records
a page image can be ranked highly even when OCR text is sparse or noisy
For engineers, the key design point is that multimodal retrieval does not replace text retrieval outright. In most serious systems, it complements it. Text retrieval still matters for specification sections, compliance discussion, booking notes, and measurement tables. But when visual evidence carries part of the meaning, text retrieval alone is an incomplete index.
When this retrieval layer feeds a grounded answer-generation step, you can think of the overall pattern as multimodal RAG: retrieval-augmented generation where the retrieved evidence includes images, figures, page renderings, captions, and structured records rather than text chunks alone.
Running Example: An OptiVerse Travel Evidence Chain
Assume a travel planner asks the copilot whether a hotel-provided photo from an accessible room actually supports the roll-in shower compliance described in the property's accessibility specification.
The system should not jump straight into answer generation. It should build an evidence chain.
It starts with the spec sheet. The document pipeline has already identified the accessibility specification section, its diagrams, and the paragraphs that reference them. The retrieval layer can now treat that specification as an object with multiple linked representations: cropped figure image, page image, caption text, section context, and contract metadata.
It then moves to the hotel evidence. Photo set ACC-09 is not just a collection of images. It should be linked to a property ID, room type, accessibility tier, booking reference JPN-2026-0417, and contract metadata from KYO-H12. If the system cannot establish that link, it should be less willing to make compliance comparisons at all.
Next comes the structured evidence. Architectural floor plan measurements, doorway widths, and accessibility rating tables may not prove the visual claim directly, but they constrain interpretation. If the photo appears to show a compliant roll-in shower while the floor plan measurements indicate insufficient turning radius, that weakens the conclusion that the room truly meets the specified accessibility standard.
At this point, the system can perform multimodal retrieval and ranking:
retrieve specification documents and pages discussing roll-in shower and accessible bathroom requirements
retrieve hotel photos from the same or adjacent room types
retrieve captions, notes, and measurement summaries tied to those images
rerank candidates using both text similarity and visual-document relevance
Only after that should a synthesis layer answer the user. A careful answer might say that the bathroom layout in ACC-09 is visually consistent with the specification's roll-in shower requirement in broad terms, but that the turning radius, grab bar placement, or threshold height differs enough that the system cannot claim full compliance without on-site verification. That is a useful answer. It is grounded, conditional, and tied to inspectable evidence.
What This Post Is Not
This is not a general introduction to vision models or image generation. It is not about image-chat demos or creative image understanding. The focus is narrower: how multimodal evidence fits into a governed verification system where provenance, alignment, and review boundaries matter. Post 8 covered the document-intelligence foundation that this post builds on. Post 10 will show how multimodal evidence becomes one layer inside the full capstone architecture.
Common Misconceptions
The first misconception is that if a model can describe an image, it has verified the claim about the image. Description is not verification. A fluent summary of "roll-in shower with grab bars along the back wall" may still ignore turning radius, threshold height, or the fact that the compared specification was written for a different room category.
The second misconception is that captions contain all the meaning needed for retrieval. They do not. Captions are one part of the evidence chain. They often underspecify what a planner would inspect directly in the photo or what the specification document clarifies.
The third misconception is that cross-modal retrieval is just OCR plus embeddings. In visually rich documents, the page image itself can preserve evidence that text extraction loses: floor plan structure, room layout relationships, annotations, measurements embedded in diagrams, or the fact that a table and photo are presented together as one argument.
The fourth misconception is that visual similarity is strong evidence of compliance equivalence. It is not. Two hotel bathroom photos may look similar while representing different room types, accessibility tiers, or renovation stages. Retrieval should suggest candidates, not settle the conclusion.
Failure Modes And Limits
Multimodal systems add capability, but they also add new ways to fail.
One failure mode is wrong figure-caption alignment. If the parsing or layout step attaches the wrong caption or nearby paragraph to a photo, the answer inherits that error. Another is missing or ignored dimensional information. A compliance comparison without measurements can overstate similarity between features that are not actually comparable.
A third failure mode is metadata drift. A hotel photo may be associated with the wrong property ID, room type, or booking reference. That turns a technically sophisticated retrieval result into a provenance error. A fourth is visual hallucination or oversimplification. A VLM may confidently summarize floor plan features, room configurations, or photo details that are weak, ambiguous, or absent.
There is also a more subtle systems failure: unsupported compliance inference. The model may retrieve a visually similar specification diagram and then leap from similarity to full compliance confirmation. That is especially risky in accessibility planning. Matching appearance is not the same as establishing that a space meets a defined accessibility standard.
This is where bounded claims matter. A multimodal verification system should be allowed to say:
the hotel photo is visually similar to the specification diagram under a limited set of attributes
the caption and nearby description support a possible interpretation
the measurement table is consistent or inconsistent with that interpretation
the evidence is insufficient to confirm compliance without on-site review
That style of answer is stronger than an overconfident "yes" because it keeps the evidence chain intact.
Practical Design Guidance
If you are building or evaluating this kind of system, four design choices matter more than model hype.
First, treat figures and pages as retrievable objects, not just attachments to text chunks. A figure should have linked image, caption, page, context, and metadata references. Second, preserve modality links through the pipeline. Do not let ingestion flatten images into isolated alt-text-like summaries and call the problem solved.
Third, combine retrieval paths. In most verification systems, text retrieval, page-image retrieval, and metadata filtering should work together. The right answer often depends on intersection, not any one index alone. Fourth, make provenance visible in the final response. A user reviewing an accessibility claim should be able to inspect which photo, caption, paragraph, table, and property record the answer relied on.
This also changes evaluation. You should not evaluate the system only on answer fluency. You should test whether it retrieves the right figure, keeps caption pairing correct, respects metadata boundaries, and abstains when the visual signal is ambiguous. Those are system-quality questions, not just model-quality questions.
What Still Needs Human Review
Multimodal grounding improves evidence handling, but it does not eliminate expert judgment.
Travel planners still need to review cases where the interpretation depends on subtle spatial layout, disputed compliance criteria, unclear measurements, or incomplete metadata. Accessibility specialists may also need to check whether a retrieved photo is genuinely comparable or merely visually adjacent. In other words, multimodality expands what the system can surface, but it does not remove the need for review where the consequences of a wrong interpretation are high.
That is consistent with the broader theme of this series. Strong systems are not the ones that hide uncertainty most effectively. They are the ones that route uncertainty into explicit boundaries, provenance, and approval boundaries.
Where This Fits In The Series
Post 8 showed that document intelligence is not just OCR. This post extends that logic: multimodality is not just image understanding. It is the systems work required to align visual evidence with text, structure, and metadata so claims remain grounded.
That leads directly to the capstone architecture. In the final post, the pieces come together: document parsing, text retrieval, multimodal retrieval, tool use, approval gates, and auditability inside one production travel copilot. The architecture question is no longer "can the model read this photo?" It is "how do we build a verification system that can use multimodal evidence without losing control of provenance, reliability, and review?"
Source Notes
This post draws on the following primary and practitioner sources:
Radford, A., Kim, J. W., Hallacy, C., et al. "Learning Transferable Visual Models From Natural Language Supervision." Reference for shared image-text representation learning and cross-modal retrieval basics. arxiv.org/abs/2103.00020
Li, J., Li, D., Savarese, S., and Hoi, S. "BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models." Reference for a practical VLM architecture connecting vision encoders and language models. arxiv.org/abs/2301.12597
Faysse, M., Sibille, H., Wu, T., et al. "ColPali: Efficient Document Retrieval with Vision Language Models." Reference for visually rich document retrieval beyond OCR-only pipelines. arxiv.org/abs/2407.01449
Yu, S., Tang, Z., Zhang, Z., et al. "VisRAG: Vision-based Retrieval-augmented Generation on Multi-modality Documents." Reference for multimodal document retrieval and generation framing. arxiv.org/abs/2410.10594
National Institute of Standards and Technology. "Artificial Intelligence Risk Management Framework: Generative Artificial Intelligence Profile." Reference for trustworthy design, traceability, and human review requirements in high-stakes multimodal systems. nist.gov/publications/artificial-intelligence-risk-management-framework-generative-artificial-intelligence
Huang Tzu Lin
With over five years in autonomous robotics, there's a strong passion for incorporating cutting-edge technologies and innovative approaches. Dedicated to transforming the latest research and insights into practical applications, this journey pushes the limits of possibility.
Related Posts
Stay Updated
Get the latest technical insights delivered to your inbox.