Document Intelligence Beyond OCR: Layout, Tables, and Evidence Reconstruction
Reading order
Document & Multimodal Intelligence
Previous chapter
No adjacent chapter
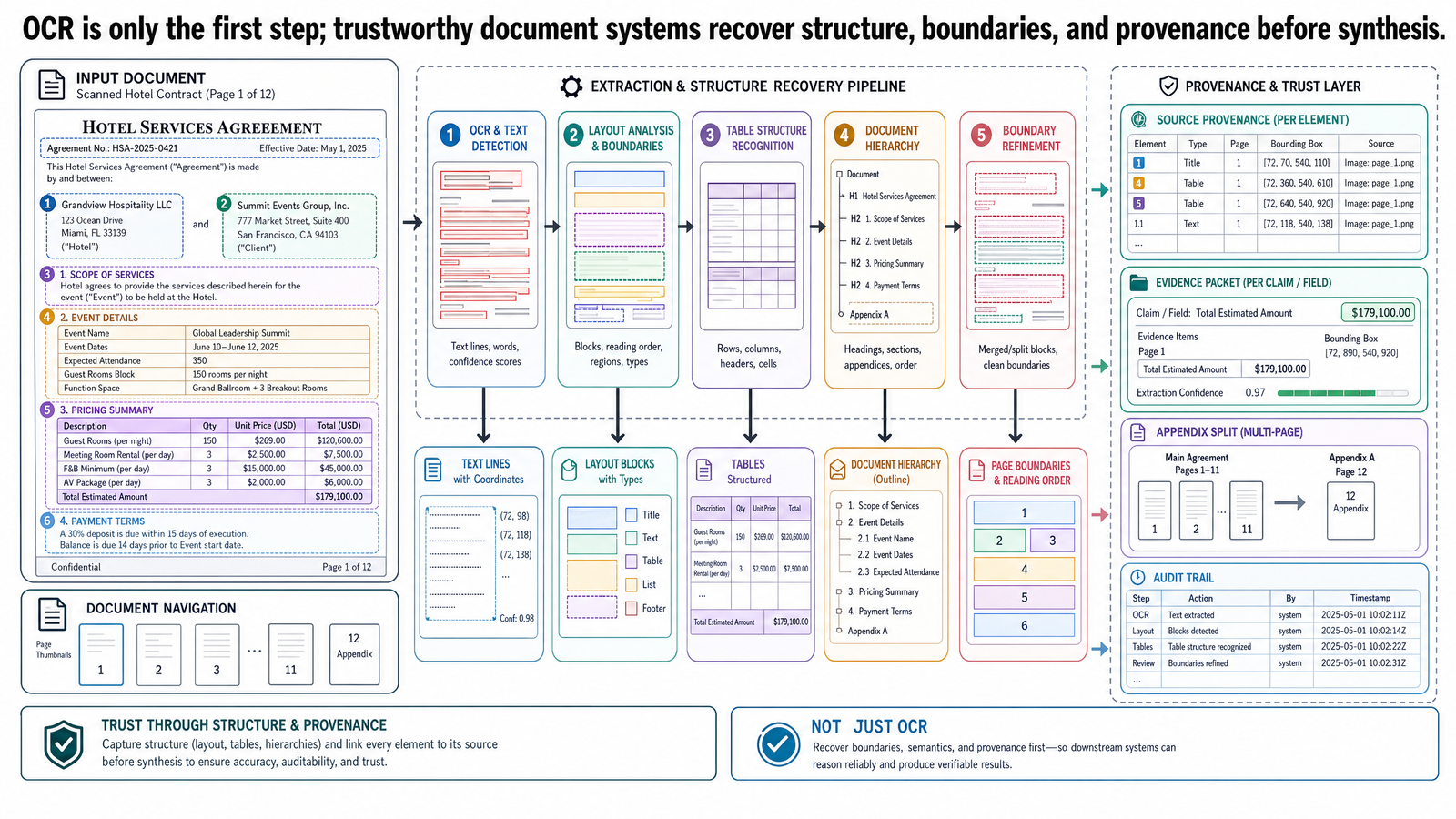
Table of Contents
- Why Plain-Text Retrieval Fails on Real Documents
- OCR Is Necessary, but It Is Only a Baseline
- Layout and Reading Order Carry Meaning
- Tables Are Structural Objects, Not Paragraphs with Delimiters
- One File May Contain Many Logical Documents
- Within-Document Structure and Across-Document Relationships
- Running Example: Reconstructing an Evidence Packet
- What This Post Is Not
- Misconceptions That Cause Bad System Design
- Common Failure Modes in Production
- Practical Design Guidance
- Why This Leads Naturally to Multimodal Evidence Systems
- Source Notes
Most teams first meet document processing through OCR. The problem seems straightforward: convert pages into text, index the text, and let retrieval or an LLM answer questions from it.
That approach works on clean, simple documents. It fails much more often on real ones.
A research paper is not just sentences. A hotel contract is not just paragraphs. A PDF packet may contain a cover page, a multi-page seasonal rate table with room categories, cancellation terms, an accessibility appendix, and a blackout-date schedule. If a system treats all of that as one flat text stream, it loses the structure that tells you what belongs together, what is a heading, what is a caption, what is a table header, and which rate is actually tied to which room category and season.
This is the core reason plain-text retrieval fails on real documents: documents are not text blobs. They are structured evidence objects. The engineering task is not only to recover words, but to recover enough structure that downstream systems can assemble trustworthy evidence.
In this post, OCR is the baseline. Then we move into what production document intelligence systems actually need: layout analysis, reading order, table structure, document splitting, document hierarchies, and evidence extraction with provenance. The running example is a travel-planning copilot for OptiVerse Travel that must reconstruct an evidence packet across hotel contracts, rate appendices, accessibility specifications, and booking confirmations.
Why Plain-Text Retrieval Fails on Real Documents
Suppose a travel planner asks:
For contract KYO-H12, extract every room rate and accessibility specification from the contract terms, the rate appendix, the accessibility appendix, and the booking confirmation, then flag any disagreement.
A text-only retrieval pipeline sounds plausible:
Extract text from every file.
Chunk the text.
Index the chunks.
Retrieve relevant passages for
KYO-H12.Ask an LLM to summarize the answer.
This breaks down for reasons that are architectural, not cosmetic.
First, reading order is often ambiguous. A two-column contract flattened into one text stream can interleave the left and right columns incorrectly. Footnotes can be inserted into the middle of the body text. Captions can be separated from the tables they explain.
Second, document hierarchy is lost. A heading is not just another line of text. It governs the material below it. If section boundaries disappear, retrieval may pull sentences that look relevant but are actually from a different pricing season, appendix, or disclaimer section.
Third, tables do not survive flattening well. A table cell is meaningful because of its row and column context. If the text extractor emits:
KYO-H12 Standard 18500 22000 26000 Accessible 21000 25000
that is not yet evidence. Which values are peak-season rates, which are shoulder-season rates, what currency applies, and whether the values came from the base-rate or meal-inclusive columns all depend on table structure.
Fourth, one file may contain several logical documents. A single uploaded PDF may include the contract terms, a rate appendix, and an accessibility appendix. If the system treats the file as one unit, retrieval and answer synthesis can blur claims that should remain distinct.
Fifth, cross-document matching is fragile. The contract terms may refer to KYO-H12, the rate appendix may use a booking reference, the accessibility appendix may use a property code, and the booking confirmation may encode the same hotel in a reservation-system field. A plain-text pipeline rarely resolves those relationships reliably.
What fails here is not only retrieval quality. The entire evidence model is too weak. A useful system needs to recover structure before it can retrieve, normalize, and compare evidence.
OCR Is Necessary, but It Is Only a Baseline
Optical character recognition, or OCR, is the foundational step that converts page images or scans into machine-readable text. That remains essential. Many real document workflows still begin with scans, photographed pages, or PDFs whose embedded text is incomplete or unreliable.
OCR solves an important problem: character recovery.
It does not, by itself, solve document understanding.
This distinction matters because teams often over-credit OCR. If the extracted text looks readable in a debug view, it is tempting to assume the system has understood the document. In practice, OCR output is only one layer in a larger representation. It may recover the words on the page while still failing to preserve the structure needed for extraction.
This is one of the recurring misconceptions in document systems:
If OCR got the words right, the document has been understood.
That is false in the same way that transcription is not the same as analysis. The characters may be correct while the reading order is wrong, the section boundaries are missing, the table headers are detached, or the footnotes are merged into the main text.
OCR also introduces its own failure modes. Recognition errors can cascade into later steps, especially when downstream extraction depends on exact IDs, units, or numeric values. If KYO-H12 becomes KYO-H1Z, or a decimal point is dropped in a nightly rate, the later retrieval and comparison steps can fail silently unless the system preserves provenance and validation signals.
This is why document intelligence should be framed as a pipeline or architecture layer, not as a single OCR feature.
Layout and Reading Order Carry Meaning
Once text is recoverable, the next question is how the document is organized on the page.
Layout analysis asks the system to identify meaningful regions such as titles, paragraphs, headers, footnotes, lists, tables, and other blocks. Reading order determines the sequence in which those regions should be interpreted. Bounding boxes give the system spatial references for where text and regions appear.
These are not presentation details. They change meaning.
In the running example, imagine a hotel contract PDF with:
a title page and contract summary
a two-column rate schedule section
a table spanning both columns
a footnote clarifying that one rate applies only during cherry-blossom season with a minimum-stay requirement
an accessibility appendix appended to the same PDF
If the system gets the reading order wrong, it may join text from column two before finishing column one. If it fails to keep the footnote attached to the relevant rate, it may present a price without the qualifier that changes its interpretation. If it does not recognize the appendix boundary, it may mix accessibility specifications into the main rate schedule without telling the user.
Layout-aware systems reduce these errors by treating page regions and positions as part of the input representation. This is one of the important architectural shifts in document AI over the last several years: the field moved from text recovery toward jointly modeling text and layout because layout itself carries information.
For engineers, the practical takeaway is simple: if your answer depends on what was above, below, beside, or inside something else on the page, you do not have a text-only problem.
Tables Are Structural Objects, Not Paragraphs with Delimiters
Tables deserve separate treatment because they are one of the most common ways document pipelines fail.
A table is not merely a compact way to display text. It is a structured object with relationships among header cells, row labels, column groups, units, merged cells, and often footnotes. A downstream system needs those relationships intact if it is going to answer quantitative questions correctly.
Consider a seasonal rate table spread across two pages in the contract appendix. The first page contains the header row and the first set of room categories. The second page continues the rows, repeats only part of the header, and includes a note indicating that some rates are subject to blackout-date surcharges. A flat text extractor might produce something that looks readable, but the semantic structure is damaged:
repeated headers may be dropped
merged cells may be expanded incorrectly
currencies may be separated from the values they qualify
continuation rows may be treated as a new table
notes may be detached from the cells they modify
If the system then retrieves text snippets instead of reconstructed table structure, it may answer with the wrong column, the wrong currency, or the wrong pricing season.
This is why table extraction typically involves several distinct tasks:
detecting where the table is
reconstructing row and column structure
identifying which cells function as headers
linking notes, currencies, and continuation pages back into the table
That separation is useful both conceptually and operationally. It reminds teams that table text extracted successfully is not the same as table structure recovered successfully.
For the travel-planning copilot, this distinction is decisive. A user asking for every room rate and accessibility specification is effectively asking for structured table evidence. If the system cannot reconstruct headers and row-column relationships, it cannot compare values with confidence.
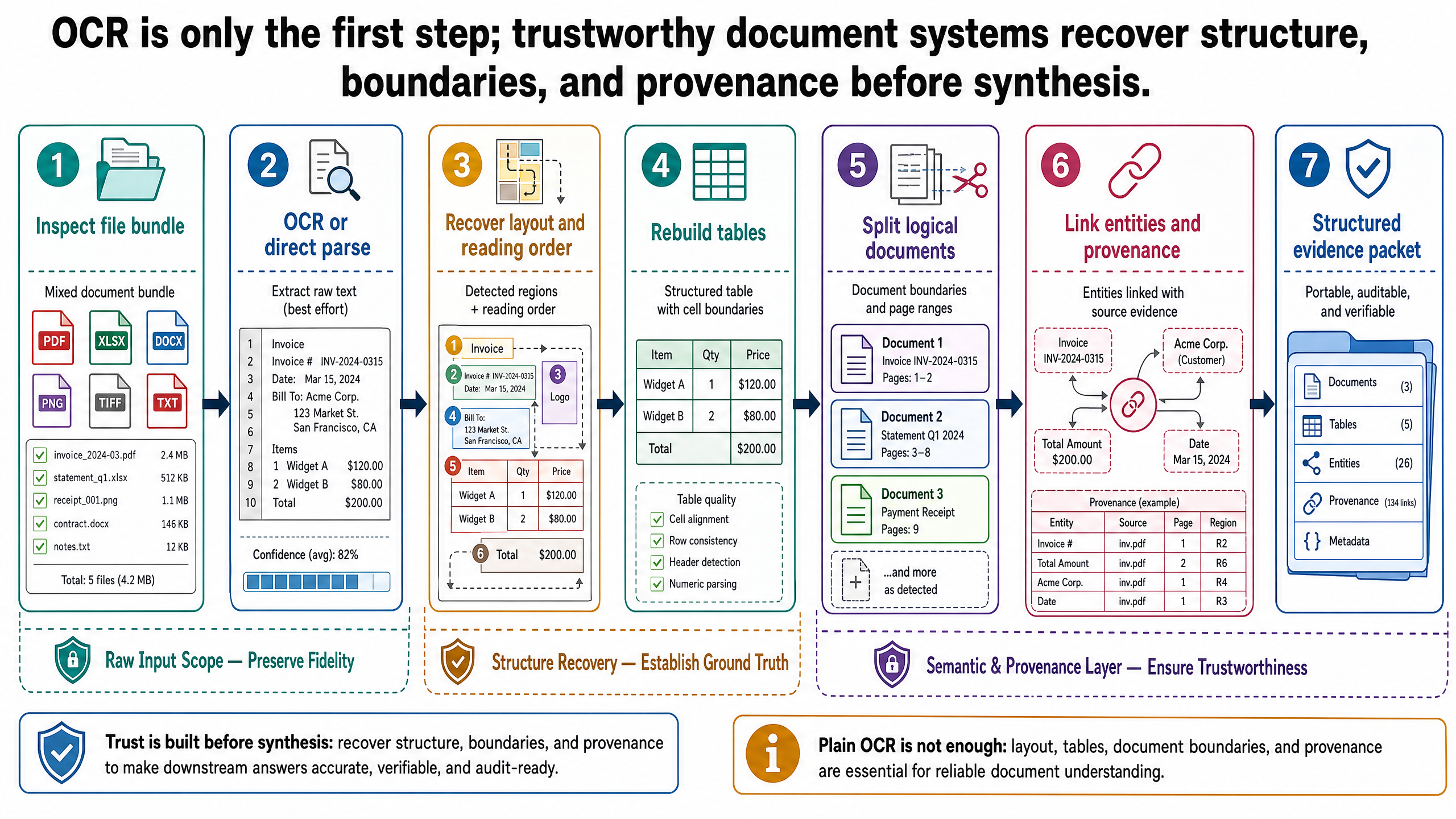
One File May Contain Many Logical Documents
Another failure mode appears before extraction even begins: assuming a file is the same thing as a document.
That assumption is often wrong.
A single PDF upload may contain a hotel contract followed by a rate appendix. An internal booking packet may bundle cover pages, itinerary details, insurance terms, and accessibility specifications. A procurement packet may combine a letter, quote, item table, and invoice in one scan. Physical packaging and logical structure are different things.
Document splitting is the task of identifying those logical boundaries. In practice, this can involve page classification, section transition detection, metadata cues, or workflow rules that inspect titles, recurring headers, or attachment markers.
In the running example, the system may receive a file that looks like one PDF but actually contains:
the contract terms for hotel KYO-H12
a rate appendix with the seasonal pricing table
an accessibility appendix with room and facility specifications
a scanned addendum page with handwritten annotations
If those are left merged, several downstream behaviors degrade:
retrieval scopes become noisy
provenance becomes harder to explain
answer synthesis can combine incomparable evidence
comparison logic may miss that the same property is being described in different document roles
This is another place where plain-text RAG tends to underperform. Text retrieval assumes the chunks already represent sensible semantic units. Document intelligence often has to create those units first.
Within-Document Structure and Across-Document Relationships
Once a system has recovered pages, layout, and tables, it still has to reason about hierarchy.
There are two different hierarchy problems here.
The first is within-document hierarchy. This includes relationships such as:
title to section
section to subsection
paragraph to list
section to table
figure to caption
footnote to referenced text
These relationships matter because they define local scope. A nightly rate in the Peak Season Rates section is not equivalent to a superficially similar value in an appendix describing promotional offers or group discounts.
The second is across-document hierarchy. This includes relationships such as:
contract terms to rate appendix
contract to accessibility appendix
booking confirmation to itinerary export
main clause to supporting schedule
Across-document relationships matter because evidence often arrives as a packet, not as a single canonical source. The system must identify which files belong together, which references point across documents, and which identifiers should be matched across naming variations.
This is where evidence packets become a useful design pattern. Instead of asking the model to read a pile of text and improvise a synthesis, the system assembles a structured packet of claims, rates, specifications, and references with explicit source links. The answer model then operates over that packet.
That separation is operationally valuable. It allows extraction quality, entity matching, and answer quality to be evaluated independently rather than collapsing everything into one opaque generation step.
Running Example: Reconstructing an Evidence Packet
Let us make the example concrete.
An OptiVerse Travel planner asks for all reported room rates and accessibility specifications for contract KYO-H12, across the contract terms, the rate appendix, the accessibility appendix, and the booking confirmation for itinerary JPN-2026-0417. The system should also flag disagreements.
A document-intelligence pipeline for that request might look like this:
Inspect each uploaded file.
Determine whether each file is a born-digital PDF, a scan, an image-heavy page set, or a merged packet containing multiple logical documents.
Parse text with the right baseline.
Use OCR where the page is image-based; use direct text extraction where the PDF contains reliable embedded text; optionally use an OCR-free parser where that architecture fits the operating constraints.
Recover page structure.
Identify page regions, reading order, headings, lists, footnotes, tables, and likely document boundaries.
Reconstruct tables.
Detect table regions, preserve header structure, and merge continuation pages into one logical table when appropriate.
Split logical documents.
Separate the contract terms from rate appendices and accessibility appendices when they are bundled into one file.
Match entities across documents.
Link KYO-H12, booking references, property codes, and reservation-system IDs where the evidence indicates they refer to the same hotel or itinerary.
Build a structured evidence packet.
Store extracted values, currencies, qualifiers, confidence signals, and page-level or cell-level provenance.
Compare and synthesize.
Only after the evidence packet exists should a downstream model summarize disagreements or produce a user-facing explanation.
This architecture is heavier than OCR-plus-RAG, but it solves a different problem. The goal is not to generate a plausible answer from nearby text. The goal is to reconstruct evidence faithfully enough that disagreements can be surfaced and inspected.
A strong output here is not just a paragraph. It is an evidence packet that might include:
JPY 22,000standard-room peak-season rate from the contract terms, page 4, Clause 4.3, rate schedule rowStandard, columnPeakJPY 25,000accessible-room peak-season rate from the rate appendix, page 11, continuation of seasonal rate table, same contract IDwheelchair-accessible roll-in showerspecification from the accessibility appendix, page 7, sectionAccessible Room Featuresa booking confirmation record linked by itinerary ID
JPN-2026-0417with a timestamp and reserved-room fielda flagged discrepancy note explaining that two reported accessible-room rates differ and should be reviewed
That output is much closer to what a travel planner or agency lead can trust. It is inspectable, and it separates extracted evidence from generated explanation.
What This Post Is Not
This is not a multimodal post. When figures, charts, and images become first-class evidence alongside text and tables, that is a different systems problem addressed in Post 9. It is also not a retrieval-strategy post; the question of when to use RAG, CAG-leaning, or hybrid grounding was covered in Post 7. This post owns document intelligence as its own architectural domain: layout recovery, table structure, document splitting, and evidence reconstruction from structured documents.
Misconceptions That Cause Bad System Design
Several misconceptions recur in document-heavy AI projects.
The first is that RAG over OCR text is enough for most document tasks. It is enough for some retrieval tasks, especially when the documents are clean and the question is mostly prose-based. It is not enough when the answer depends on layout, tables, qualifiers, or cross-document relationships.
The second is that a table is just text with delimiters. In real contracts and PDFs, table semantics are often carried by merged headers, continuation rows, currencies, or notes outside the grid itself. Flattening the table destroys part of the meaning.
The third is that one uploaded PDF should be treated as one document. This fails on bundles, appendices, and supplements, all of which are common in travel operations and enterprise workflows.
The fourth is that OCR-free document models remove the need for structure and validation. They do not. Even if OCR is no longer a separate stage, the system still needs to recover document relationships, preserve provenance, and evaluate extraction quality.
The fifth is that document intelligence is just a preliminary version of multimodality. That is too shallow. Document intelligence is its own systems layer because structure, hierarchy, and extraction quality matter even before figures and images become central.
Common Failure Modes in Production
The most important failures are usually structural.
Broken reading order can interleave columns or detach sidebars from the surrounding text. Section headings can drift away from the paragraphs they govern. Tables can be split at page boundaries and reconstructed incorrectly. Header rows can be lost, leading the system to assign values to the wrong columns. Appendices and supplements can remain merged into the main document. Cross-document identifiers can be matched too aggressively or not at all. Extracted values can be passed downstream without page or cell provenance. OCR errors can silently propagate into retrieval, normalization, and answer generation.
These failure modes are worth calling out because they often produce confident-looking outputs. A user may receive a clean summary and never see that the supporting table was misread or that the rate came from the appendix rather than the main contract. In high-stakes workflows, the main risk is not just visible failure. It is invisible misattribution.
Practical Design Guidance
Treat document intelligence as a separate architecture layer, not a convenience feature attached to retrieval.
Start with a file inspection stage. Before you retrieve anything, determine what kinds of files you have, whether they are scanned or born-digital, and whether one file contains multiple logical documents.
Preserve structure early. Recover page regions, reading order, and table boundaries before chunking for retrieval. If you flatten first, you may destroy the very cues needed for reliable extraction.
Represent tables explicitly. Store row and column structure, headers, currencies, and page references. Do not reduce tables to generic text unless your use case has proved that the loss is acceptable.
Separate extraction from synthesis. Build a structured evidence packet first, then let a downstream model explain or compare the evidence. This makes debugging, evaluation, and review much easier.
Make provenance first-class. Store where every extracted value came from, ideally at page level and, for tables, at cell level when feasible. If users cannot inspect the source location, they cannot meaningfully review disagreements.
Be conservative about entity matching. Cross-document linking of contract IDs, booking references, and property codes should be treated as a probabilistic or rule-governed step with validation, not as a casual fuzzy match.
Evaluate by document task, not just answer fluency. Measure table reconstruction, document splitting, identifier matching, and provenance quality separately. A polished final answer can hide a structurally broken pipeline.
Use OCR as a baseline, not a dogma. Some systems will remain OCR-first for practical reasons. Others may adopt OCR-free parsers for parts of the workflow. The key design question is not which approach sounds more modern. It is whether the system preserves the structure required for the task.
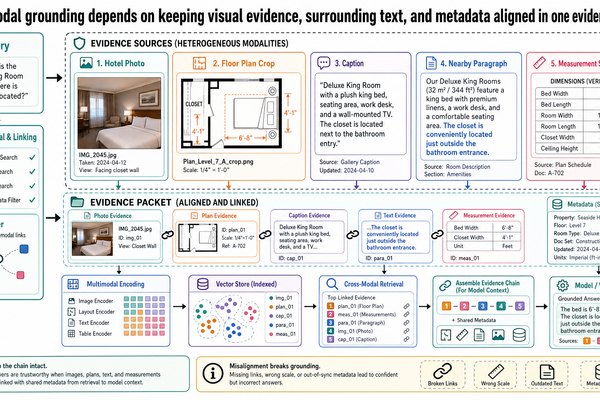
Why This Leads Naturally to Multimodal Evidence Systems
Once a team accepts that documents are not text blobs, the next architectural step becomes obvious.
Many important claims in travel contracts do not live only in paragraphs or tables. They also live in floor plans, property photos, accessibility diagrams, captions, legends, and the relationships among them. A system that can reconstruct page layout, table structure, and document hierarchy is already moving beyond plain-text retrieval toward a fuller evidence model.
That is the bridge to multimodal systems.
Post 9 picks up from here. Once figures, charts, and images become first-class evidence alongside text and tables, document intelligence expands into multimodal grounding: linking visual content to captions, surrounding prose, and cross-document claims without losing provenance.
Source Notes
This post draws on the following primary and practitioner sources:
Smith, R. "An Overview of the Tesseract OCR Engine." Reference for OCR as character recognition, not full document understanding. research.google/pubs/an-overview-of-the-tesseract-ocr-engine
Xu, Y., Li, M., Cui, L., et al. "LayoutLM: Pre-training of Text and Layout for Document Image Understanding." Reference for the claim that layout and style information matter to document understanding. arxiv.org/abs/1912.13318
Li, M., Xu, Y., Cui, L., et al. "DocBank: A Benchmark Dataset for Document Layout Analysis." Reference for fine-grained layout analysis as a distinct task. arxiv.org/abs/2006.01038
Smock, B., Pesala, R., and Abraham, R. "PubTables-1M: Towards Comprehensive Table Extraction From Unstructured Documents." Reference for table detection, structure recognition, and functional analysis as separable tasks. arxiv.org/abs/2110.00061
Kim, G., Hong, T., Yim, M., et al. "OCR-free Document Understanding Transformer." Reference for OCR-free document-understanding approaches and OCR error-propagation cautions. arxiv.org/abs/2111.15664
National Institute of Standards and Technology. "Artificial Intelligence Risk Management Framework: Generative Artificial Intelligence Profile." Reference for provenance, traceability, and review language in high-stakes extraction workflows. nist.gov/publications/artificial-intelligence-risk-management-framework-generative-artificial-intelligence
Huang Tzu Lin
With over five years in autonomous robotics, there's a strong passion for incorporating cutting-edge technologies and innovative approaches. Dedicated to transforming the latest research and insights into practical applications, this journey pushes the limits of possibility.
Related Posts
Stay Updated
Get the latest technical insights delivered to your inbox.