超越 OCR 的文件智慧(Document Intelligence):版面分析、表格與證據重建
閱讀順序
Document & Multimodal Intelligence
多數團隊第一次接觸文件處理,都是從 OCR 開始。問題看起來很直覺:把頁面轉成文字、為文字建索引,然後讓檢索系統或 LLM 來回答問題。
在乾淨、簡單的文件上這樣做沒問題,碰到真實文件就常常出事。
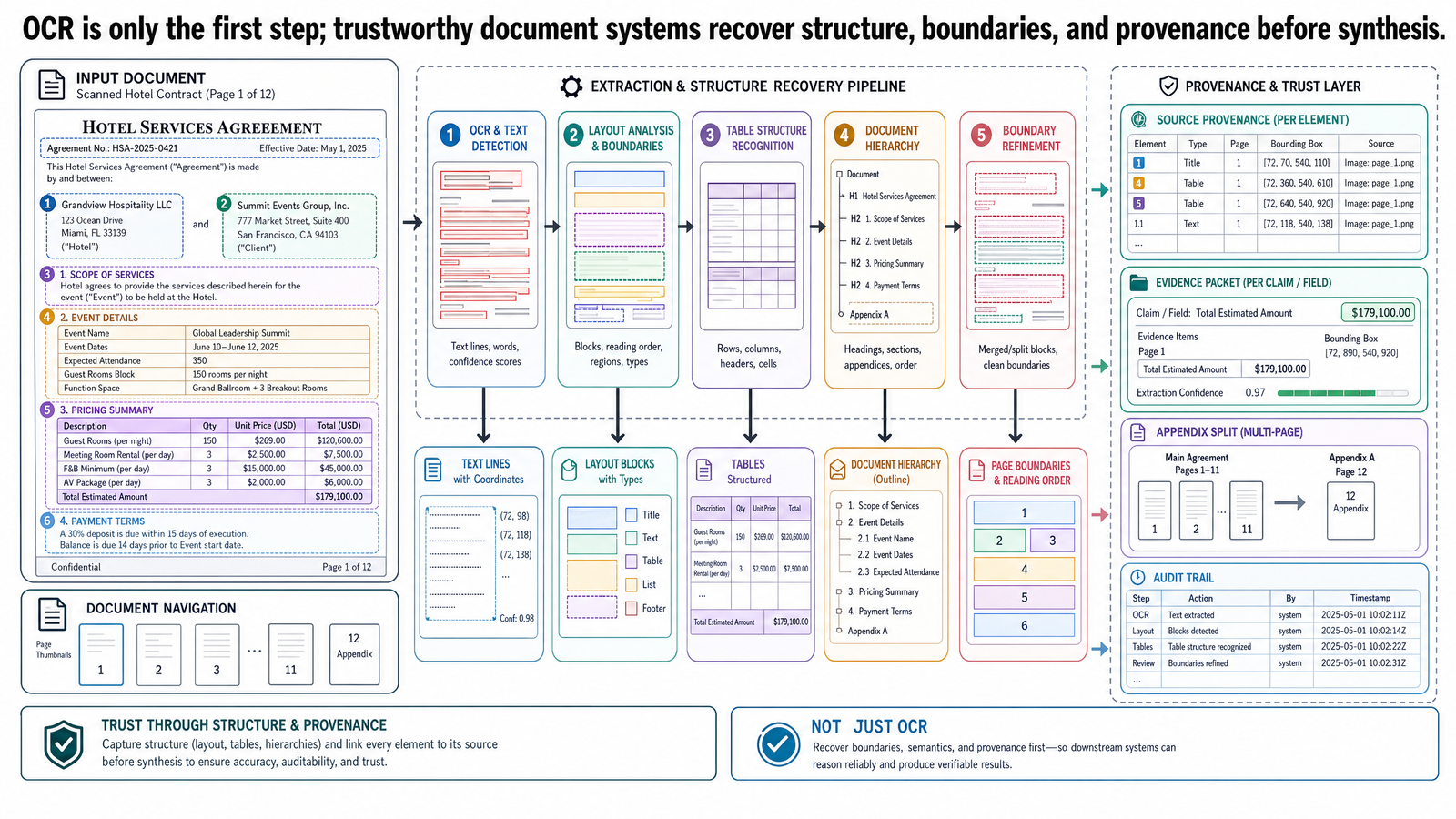
一篇研究論文不只是句子。一份飯店合約不只是段落。一份 PDF 封包可能包含封面頁、一張跨多頁的季節性房價表(含房型分類)、取消條款、無障礙附錄,以及黑名單日期表。系統要是把這些通通當成扁平的文字流來處理,就會失去那些告訴你什麼內容屬於一起、什麼是標題、什麼是圖說、什麼是表頭,以及哪個房價對應哪個房型和季節的結構資訊。
這就是純文字檢索在真實文件上失敗的根本原因:文件不是文字塊,而是結構化的證據物件。工程上的挑戰不只是把文字還原出來,更在於還原足夠的結構,讓下游系統能組裝可信賴的證據。
本文以 OCR 為基準,逐步往上推。我們會談到正式環境文件智慧系統真正需要的東西:版面分析(layout analysis)、閱讀順序、表格結構、文件分割、文件層級關係,以及帶有溯源的證據擷取。貫穿全文的範例是一個為 OptiVerse Travel 設計的旅行規劃 Copilot,它必須橫跨飯店合約、費率附錄、無障礙規格書和預訂確認函來重建證據封包。
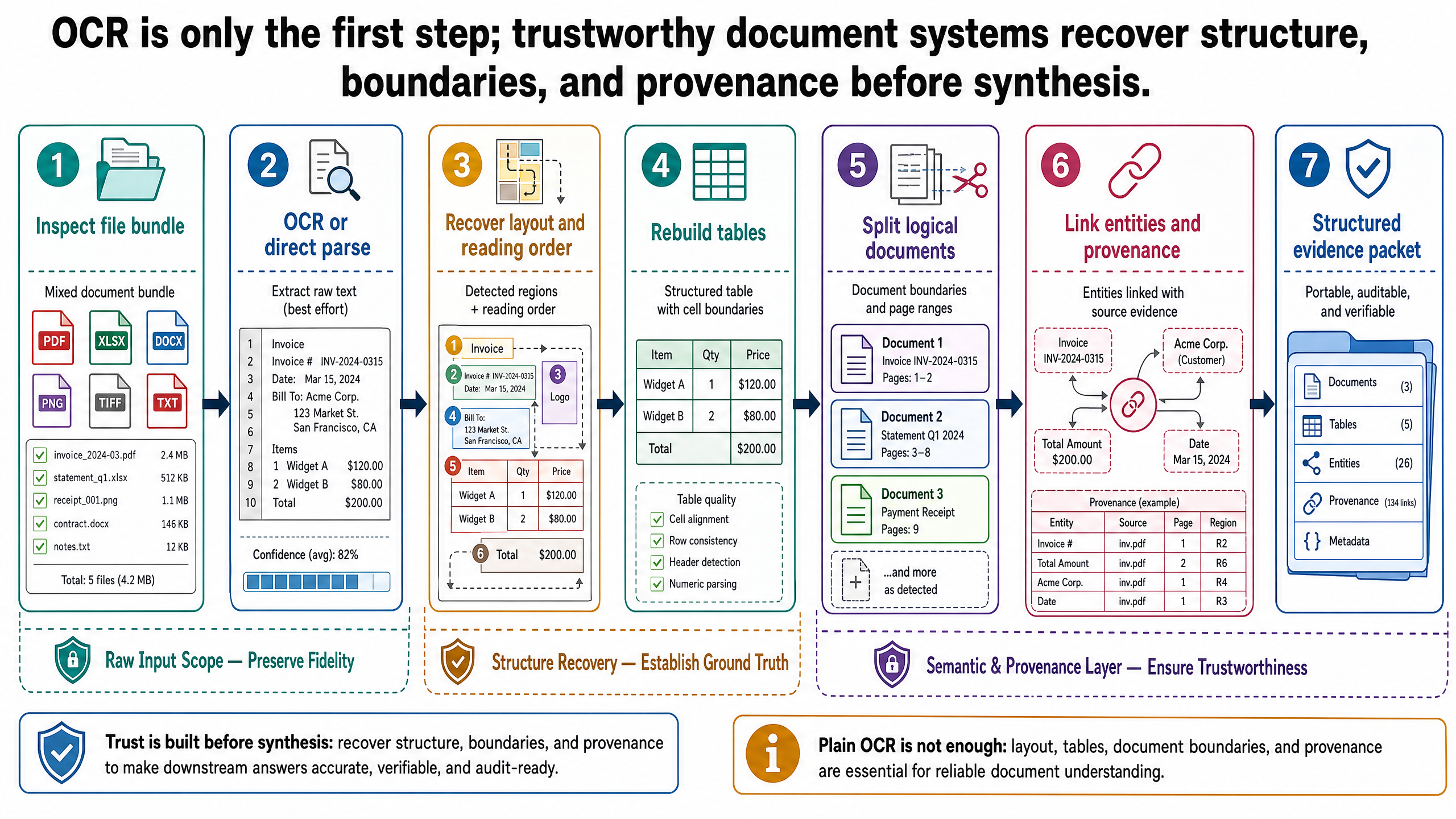
為什麼純文字檢索在真實文件上失敗
假設一位旅行規劃師提出以下需求:
針對合約 KYO-H12,從合約條款、費率附錄、無障礙附錄和預訂確認函中擷取所有房價和無障礙規格,然後標記任何不一致之處。
一個純文字的檢索流程聽起來可行:
從每個檔案中擷取文字。
將文字分割成區塊。
為區塊建立索引。
檢索與
KYO-H12相關的段落。請 LLM 摘要回答。
但這在架構層面——不只是表面層面——就會出問題。
第一,閱讀順序經常是含混的。雙欄合約被扁平化為單一文字流時,左右欄的內容可能被錯誤地交錯在一起。註腳可能插入正文中間。圖說可能與它們所解釋的表格脫離。
第二,文件層級關係會遺失。標題不只是另一行文字,它統轄其下方的內容。章節邊界一旦消失,檢索可能拉回看似相關、實際上來自不同定價季節、附錄或免責條款章節的句子。
第三,表格經不起扁平化處理。表格儲存格之所以有意義,靠的是它的列和欄上下文。如果文字擷取器輸出:
KYO-H12 Standard 18500 22000 26000 Accessible 21000 25000
這算不上證據。哪些值是旺季、哪些是肩季、用什麼幣別、來自基本房價欄還是含餐房價欄,全都取決於表格結構。
第四,一個檔案可能包含多個邏輯文件。一份上傳的 PDF 可能同時包含合約條款、費率附錄和無障礙附錄。系統一旦把它視為一個單元,檢索和答案合成就可能混淆本應區分的主張。
第五,跨文件比對是脆弱的。合約條款可能引用 KYO-H12,費率附錄使用預訂參考號,無障礙附錄使用物業代碼,而預訂確認函在訂房系統欄位中編碼同一家飯店。純文字流程很少能可靠地解析這些關係。
這裡失敗的不僅是檢索品質,整個證據模型都太薄弱了。有用的系統需要先還原結構,才能可靠地檢索、正規化和比較證據。
OCR 是必要的,但它只是基準
光學字元辨識(OCR)是將頁面影像或掃描件轉換為機器可讀文字的基礎步驟,至今仍不可或缺——許多真實的文件工作流程仍然始於掃描件、拍照頁面,或內嵌文字不完整的 PDF。
OCR 解決的是字元恢復。但它本身不解決文件理解。
這個區別很重要,因為團隊經常把太多功勞歸給 OCR。擷取出來的文字在除錯視圖中看起來可讀,大家就很容易以為系統已經理解了文件。其實 OCR 輸出只是更大表示層中的一層——文字可能還原了,但擷取所需的結構仍然缺失。
這是文件系統中反覆出現的誤解:
如果 OCR 正確辨識了文字,文件就算被理解了。
道理跟「轉錄不等於分析」一樣。字元可能都對了,但閱讀順序可能錯誤、章節邊界可能遺失、表頭可能脫離、註腳可能被併入正文。
OCR 本身也有失敗模式。辨識錯誤可能一路連鎖到後續步驟,尤其是下游擷取依賴精確的 ID、單位或數值的時候。KYO-H12 變成 KYO-H1Z,或者每晚房價的小數點被遺漏,後續的檢索和比較步驟就可能靜默地失敗——除非系統保留了溯源和驗證信號。
所以文件智慧應該看成一整套流程或架構層,而不是一個單一的 OCR 功能。
版面和閱讀順序承載意義
文字還原之後,接下來的問題是文件在頁面上怎麼組織的。
版面分析(layout analysis)要求系統辨識出有意義的區域:標題、段落、頁首、註腳、列表、表格和其他區塊。閱讀順序決定這些區域要依什麼順序來解讀。邊界框(bounding box)則提供文字和區域在頁面上出現位置的空間參照。
這些不是呈現細節,而是會改變含義的東西。
以我們的範例來看,想像一份飯店合約 PDF 包含:
一個標題頁和合約摘要
一個雙欄的費率表章節
一張橫跨兩欄的表格
一則註腳,說明某個費率僅適用於櫻花季且有最低住宿天數
一份附加在同一 PDF 中的無障礙附錄
系統誤判閱讀順序,可能第一欄還沒讀完就接上第二欄的文字。沒把註腳附著在相關費率上,可能呈現一個價格卻漏掉了改變解讀方式的限定條件。沒辨識出附錄的邊界,可能把無障礙規格混進主費率表卻不告知使用者。
版面感知系統把頁面區域和位置當作輸入表示的一部分,藉此降低這些錯誤。這是近年文件 AI 領域重要的架構轉變之一:從單純還原文字,轉向同時建模文字和版面,因為版面本身就承載資訊。
對工程師來說,實務要點很簡單:如果你的答案取決於頁面上某個元素的上方、下方、旁邊或內部有什麼,那你面對的就不是純文字問題。
表格是結構化物件,不是帶分隔符號的段落
表格值得單獨討論,因為它們是文件流程最常失敗的地方之一。
表格不只是把文字排得比較緊湊而已,它是結構化物件——表頭儲存格、列標籤、欄群組、單位、合併儲存格和註腳之間都存在著關係。下游系統需要這些關係完好無損,才能正確回答量化問題。
來看合約附錄中一張跨兩頁的季節性費率表。第一頁包含表頭列和第一組房型類別,第二頁延續各列、只重複了部分表頭,並附了一則備註說明某些費率受黑名單日期附加費影響。扁平化文字擷取器可能產出看起來可讀的內容,但語義結構已經被破壞了:
重複的表頭可能被丟棄
合併儲存格可能被錯誤展開
幣別可能與對應的數值分離
延續列可能被視為新表格
備註可能與修飾的儲存格脫離
如果系統接著檢索的是文字片段而不是重建的表格結構,就可能用錯誤的欄、錯誤的幣別或錯誤的定價季節來作答。
所以表格擷取(table extraction)通常涉及幾個不同的任務:
偵測表格的位置
重建列和欄的結構
辨識哪些儲存格充當表頭
將備註、幣別和延續頁面連結回表格
把這些任務分開,在概念上和營運上都有好處,也提醒團隊:「表格文字擷取成功」不等於「表格結構還原成功」。
對旅行規劃 Copilot 來說,這個區別至關重要。使用者要求所有房價和無障礙規格,實際上就是在要求結構化的表格證據。系統要是無法重建表頭和列欄關係,就無法有把握地比較數值。
一個檔案可能包含多個邏輯文件
另一個失敗模式在擷取開始之前就出現了:預設一個檔案就等於一份文件。
這個假設往往是錯的。
一份上傳的 PDF 可能是飯店合約後面接費率附錄。內部預訂封包可能把封面頁、行程細節、保險條款和無障礙規格綁在一起。採購封包可能把信函、報價單、品項表和發票合併在一次掃描中。實體的檔案封裝和邏輯結構是兩回事。
文件分割(document splitting)就是辨識這些邏輯邊界的任務。實務上可能需要做頁面分類、偵測章節轉換、利用中繼資料線索,或用工作流程規則去檢查標題、重複出現的頁首或附件標記。
在我們的範例中,系統可能收到一份看似單一 PDF、實際包含以下內容的檔案:
飯店 KYO-H12 的合約條款
一份包含季節性定價表的費率附錄
一份包含客房和設施規格的無障礙附錄
一頁帶有手寫註記的掃描增補文件
這些若保持合併狀態,幾個下游行為就會劣化:
檢索範圍變得嘈雜
溯源變得更難解釋
答案合成可能結合不可比較的證據
比較邏輯可能遺漏同一物業在不同文件角色中被描述的事實
這也是純文字 RAG 容易表現不佳的地方。文字檢索假設區塊已經代表合理的語義單元。文件智慧(document intelligence)通常必須先建立這些單元。
文件內部結構與跨文件關係
系統還原了頁面、版面和表格之後,還需要推理層級關係。
這裡有兩個不同層級的問題。
第一個是文件內部層級關係,包括:
標題到章節
章節到子章節
段落到列表
章節到表格
圖片到圖說
註腳到被引用的文字
這些關係之所以重要,是因為它們定義了局部範圍。「旺季房價」章節中的每晚房價,不等同於描述促銷優惠或團體折扣的附錄中一個表面上相似的數值。
第二個是跨文件層級關係,包括:
合約條款到費率附錄
合約到無障礙附錄
預訂確認函到行程匯出
主條款到支援附表
跨文件關係之所以重要,是因為證據通常以封包形式出現,而非來自單一的權威來源。系統必須辨識哪些檔案屬於同一組、哪些引用跨文件指向彼此,以及哪些識別碼即使名稱不同也該比對在一起。
這就是為什麼證據封包是一個實用的設計模式。系統不是叫模型讀一堆文字然後即興合成,而是先組裝一個結構化的封包——包含主張、費率、規格和引用,附帶明確的來源連結。答案模型接著在封包之上運作。
這樣分開在營運上很有價值:擷取品質、實體比對和答案品質可以分別評估,不用把所有東西壓縮成一個不透明的生成步驟。
範例實作:重建證據封包
我們把範例具體化。
一位 OptiVerse Travel 規劃師要求提供合約 KYO-H12 中所有已報告的房價和無障礙規格,橫跨合約條款、費率附錄、無障礙附錄,以及行程 JPN-2026-0417 的預訂確認函。系統還應標記不一致之處。
為了滿足這個需求,文件智慧流程可能會這樣運作:
檢查每個上傳的檔案。
判斷每個檔案是原生數位 PDF、掃描件、圖像密集的頁面集,或是包含多個邏輯文件的合併封包。
使用正確的方法解析文字。
頁面為圖像時用 OCR;PDF 包含可靠內嵌文字時用直接文字擷取;架構符合營運限制時,可選擇無 OCR 解析器。
還原頁面結構。
辨識頁面區域、閱讀順序、標題、列表、註腳、表格和可能的文件邊界。
重建表格。
偵測表格區域,保留表頭結構,必要時將延續頁面合併為一個邏輯表格。
分割邏輯文件。
合約條款與費率附錄和無障礙附錄捆綁在一個檔案中時,將它們分離。
跨文件比對實體。
連結 KYO-H12、預訂參考號、物業代碼和訂房系統 ID——當證據指出它們指向同一家飯店或行程時。
建立結構化的證據封包。
儲存擷取的數值、幣別、限定條件、信心信號,以及頁面層級或儲存格層級的溯源。
比較與合成。
只有在證據封包存在之後,下游模型才應摘要不一致之處或產生面向使用者的說明。
這個架構比 OCR 加 RAG 來得重,但它要解決的問題不一樣。目標不是從鄰近的文字生成一個看似合理的答案,而是忠實地重建證據,讓不一致之處可以被揭露和檢查。
強健的輸出不僅是一段文字,而是一個可能包含以下內容的證據封包:
JPY 22,000標準房旺季房價,來自合約條款第 4 頁、Clause 4.3、費率表列Standard、欄PeakJPY 25,000無障礙房旺季房價,來自費率附錄第 11 頁、季節性費率表延續部分、相同合約 ID輪椅無障礙淋浴間規格,來自無障礙附錄第 7 頁、Accessible Room Features章節一筆預訂確認記錄,透過行程 ID
JPN-2026-0417連結,含時間戳記和已預訂房型欄位一則已標記的差異備註,說明兩個已報告的無障礙房價格不同,應予審查
這種輸出才更接近旅行規劃師或業務主管真正能信賴的東西——它可以被逐一檢查,而且把擷取的證據和生成的說明分開了。
本文不討論的內容
這不是一篇多模態文章。當圖片、圖表和影像跟文字及表格一起成為一級證據時,那是另一個系統層面的問題,留到第九篇討論。這也不是檢索策略文章——何時用 RAG、偏 CAG 或混合基礎化的問題在第七篇已經涵蓋。本文專注於文件智慧這個架構領域本身:版面還原、表格結構、文件分割,以及從結構化文件中重建證據。
導致糟糕系統設計的誤解
在以文件為核心的 AI 專案中,有幾個反覆出現的誤解。
第一個是以為在 OCR 文字上做 RAG 對多數文件任務就夠了。對某些檢索任務確實夠——特別是文件乾淨、問題主要圍繞散文的時候。但答案一旦取決於版面、表格、限定條件或跨文件關係,就不夠了。
第二個是以為表格只不過是帶分隔符號的文字。在真實的合約和 PDF 裡,表格的語義通常由合併的表頭、延續列、幣別或表格外的備註承載。把表格扁平化會破壞部分含義。
第三個是以為一份上傳的 PDF 就該視為一份文件。碰到捆綁檔案、附錄和補充文件就會失敗——而這些在旅行營運和企業工作流程中非常常見。
第四個是以為無 OCR 的文件模型就不需要處理結構和驗證了。其實不然。即使 OCR 不再是獨立階段,系統仍然需要還原文件關係、保留溯源,以及評估擷取品質。
第五個是以為文件智慧只是多模態的初級版本。這個看法太表面了。文件智慧是自成一格的系統層——即使在圖片和影像成為核心之前,結構、層級關係和擷取品質就已經至關重要。
正式環境中的常見失敗模式
最重要的失敗通常是結構性的。
錯誤的閱讀順序可能交錯欄位或把側邊欄與周圍文字脫離。章節標題可能偏離其統轄的段落。表格可能在頁面邊界處被分割且重建錯誤。表頭列可能遺失,導致數值被指派到錯誤的欄位。附錄和補充文件可能仍然與主文件合併。跨文件的識別碼可能被過度積極地比對,或完全未比對。擷取的數值可能在沒有頁面或儲存格溯源的情況下就被傳遞到下游。OCR 錯誤可能靜默地傳播到檢索、正規化和答案生成中。
要特別指出這些失敗模式,是因為它們經常產出看起來很有信心的輸出。使用者可能收到一份乾淨的摘要,卻完全看不到背後的表格被誤讀、或費率來自附錄而不是主合約。在高風險工作流程中,主要風險不只是可見的失敗,更是看不見的錯誤歸因。
實務設計指引
把文件智慧當成一個獨立的架構層,不是附加在檢索上的便利功能。
從檔案檢查階段開始。在檢索任何東西之前,先釐清你手上有什麼類型的檔案、它們是掃描的還是原生數位的,以及一個檔案裡是否包含了多個邏輯文件。
儘早保留結構。在為檢索做區塊分割之前,先還原頁面區域、閱讀順序和表格邊界。一旦先扁平化了,可能就會破壞可靠擷取所需的關鍵線索。
明確地表示表格。把列和欄的結構、表頭、幣別和頁面引用存下來。別把表格縮減成一般文字,除非你的使用情境已經證明這種損失可以接受。
把擷取和合成分開。先建立結構化的證據封包,再讓下游模型去解釋或比較證據。這樣除錯、評估和審查都更容易。
讓溯源成為一級概念。每個擷取值都要記錄它的來源——理想上到頁面層級,表格的話能到儲存格層級更好。使用者要是無法檢查來源位置,就無法有意義地審查不一致之處。
實體比對要保守。跨文件的合約 ID、預訂參考號和物業代碼連結,應該當成機率性或規則管理的步驟來處理,搭配驗證,而不是隨意做模糊比對。
按文件任務來評估,不要只看答案流暢度。分別衡量表格重建、文件分割、識別碼比對和溯源品質。一個漂亮的最終答案背後,可能藏著結構已經損壞的流程。
把 OCR 當基準,不要當教條。有些系統基於實際原因仍以 OCR 為主,有些則在部分工作流程採用無 OCR 的解析器。關鍵的設計問題不是哪種方式比較現代,而是系統是否保留任務所需的結構。
為什麼這自然地引向多模態證據系統
一旦團隊接受「文件不是文字塊」這件事,下一個架構步驟就變得顯而易見。
旅行合約中許多重要的主張不只存在段落或表格裡,也在平面圖、物業照片、無障礙示意圖、圖說、圖例,以及它們之間的關係中。一個能重建頁面版面、表格結構和文件層級關係的系統,已經超越了純文字檢索,正朝更完整的證據模型邁進。
這就是通往多模態系統的橋樑。
第九篇從此處接續。一旦圖片、圖表和影像與文字及表格一起成為一級證據,文件智慧就擴展為多模態基礎化:在不失去溯源的前提下,將視覺內容與圖說、周圍散文和跨文件主張連結起來。
來源附註
本文參考以下主要與實務來源:
Smith, R. "An Overview of the Tesseract OCR Engine." 將 OCR 錨定為字元辨識,而非完整文件理解的參考。research.google/pubs/an-overview-of-the-tesseract-ocr-engine
Xu, Y., Li, M., Cui, L., et al. "LayoutLM: Pre-training of Text and Layout for Document Image Understanding." 支援版面與樣式資訊對文件理解重要性的參考。arxiv.org/abs/1912.13318
Li, M., Xu, Y., Cui, L., et al. "DocBank: A Benchmark Dataset for Document Layout Analysis." 細粒度版面分析作為獨立任務的參考。arxiv.org/abs/2006.01038
Smock, B., Pesala, R., and Abraham, R. "PubTables-1M: Towards Comprehensive Table Extraction From Unstructured Documents." 表格偵測、結構辨識與功能分析可分開評估的參考。arxiv.org/abs/2110.00061
Kim, G., Hong, T., Yim, M., et al. "OCR-free Document Understanding Transformer." OCR-free 文件理解方法與 OCR 錯誤傳播風險的參考。arxiv.org/abs/2111.15664
National Institute of Standards and Technology. "Artificial Intelligence Risk Management Framework: Generative Artificial Intelligence Profile." 高風險擷取流程中的來源脈絡、可追蹤性與審查語言參考。nist.gov/publications/artificial-intelligence-risk-management-framework-generative-artificial-intelligence
Huang Tzu Lin
With over five years in autonomous robotics, there's a strong passion for incorporating cutting-edge technologies and innovative approaches. Dedicated to transforming the latest research and insights into practical applications, this journey pushes the limits of possibility.
相關文章
訂閱最新資訊
將最新技術洞察直接送到您的信箱。