當 RAG 不夠用時:快取增強生成(CAG)、混合檢索與工作記憶
閱讀順序
Building AI Systems
下一章
尚無可用文章
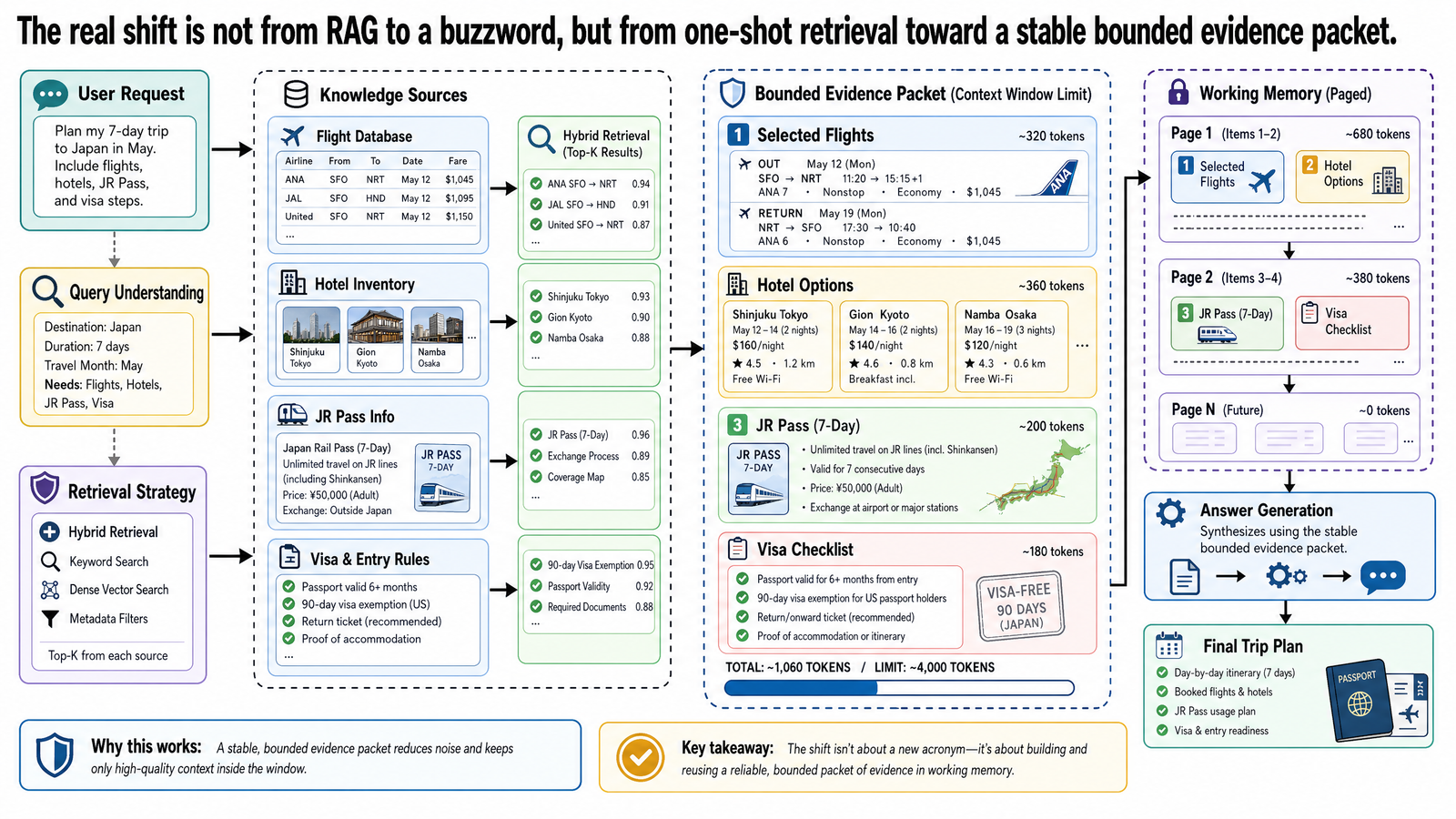
基本的檢索增強生成(RAG)到現在還是多數正式環境系統最常用的基礎模式。語料庫很大、更新頻繁、又需要展示答案來源?檢索依然是最乾淨的起點。不過實務上會碰到一種極限情境——簡單的 RAG 開始力不從心:系統確實找到了正確的文件,但任務現在需要的是針對一組有限的證據持續推理,同時回答同一案件的多次後續追問。
這正是團隊開始亂用術語的節點。有人把下一步叫「長上下文 AI」,有人叫「記憶」,有人叫「CAG」。這些術語不能互換,架構選擇也不只是表面差異。本文不是又一篇通用的記憶科普,而是在處理一個具體問題:當任務需要在多次後續追問中維持穩定的證據封包時,進階的基礎化(grounding)該怎麼做?如果目標是打造可靠的基礎化系統,有五件事最好先釐清:標準 RAG、大型上下文視窗、新興的 CAG 術語、混合檢索模式,以及暫時性工作記憶。
本文從這個邊界情境切入。重點不在於 RAG 是否過時了,而在於什麼時候純檢索互動覆蓋不了整個設計,什麼時候該加入一個有界限的證據封包,讓模型可以反覆在上面推理。代理迴圈(agent loop)是一個常見場景,但更深層的議題其實更廣:反覆進行的調查型工作流程,需要比每次重新跑 top-k 檢索更穩定的基礎化。
為什麼基本 RAG 仍然是預設選擇
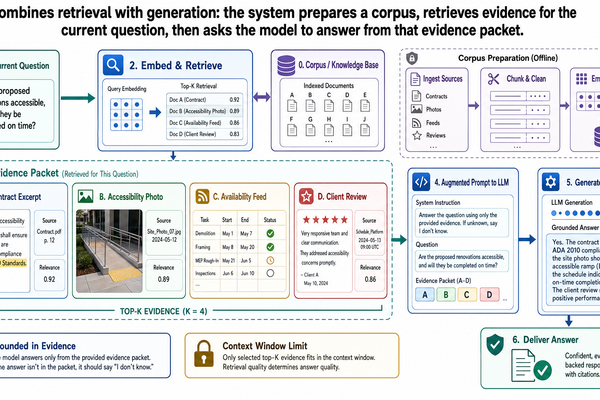
RAG 之所以仍是標準做法,是因為它能妥善解決一個常見的正式環境問題:模型需要存取那些太動態、太龐大或太特定於組織的資訊——光靠模型權重撐不住。檢索器搜尋語料庫,回傳一組聚焦的段落,模型就從這些材料中作答,而不是從無依據的回憶中編造。
這種架構有幾項實際優勢:
比起把整個語料庫放入每個提示詞,擴展性好得多
無需重新訓練就能反映最新資料
提供溯源和答案歸因的路徑
在知識儲存和答案生成之間建立清晰的邊界
以本系列的旅行 Copilot 為例,標準 RAG 非常適合這類問題:「我們之前是否在櫻花季期間預訂過京都的無障礙飯店?」相關證據可能散布在供應商合約、過往行程、無障礙稽核報告和季節性空房資料中。語料庫太廣、變動也太頻繁,無法全部預先載入,所以檢索是正確的第一步。
這個標準做法之所以重要,是因為許多團隊跳過它的速度太快了。如果工作負載主要是對一個龐大且持續變動的語料庫做一次性問答,基本 RAG 通常還是夠用的。本文中更複雜的模式,是為那些檢索必要、但單靠檢索已經不夠的情況準備的。
標準 RAG 開始力不從心的地方
簡單的 RAG 迴圈通常假設一種狹窄的互動模式:
接收查詢
檢索最相關的證據
生成答案
當答案可以從一小組檢索結果中得到基礎化、使用者也不太會進一步深挖時,這種方式運作良好。但一旦使用者想反覆質詢同一批證據、比較跨文件的多個片段,或提出依賴完全相同上下文封包的後續問題,效果就大打折扣。
來看旅行 Copilot 的這個任務:
對於預訂 JPN-2026-0417,組建旅行檔案:比較我們三個候選航班選項與四個依輪椅無障礙程度評級的飯店候選,然後交叉比對兩個旅遊套裝方案、JR Pass 分析和簽證清單,以便旅行顧問能回答關於取捨的後續問題。
前半段看起來還像 RAG——系統搜尋更大的知識庫,找到相關的航班庫存、飯店合約、無障礙審查和供應商條款。但一旦找到這些證據,挑戰就不一樣了。模型不再只是從幾個孤立片段中作答,而是必須跨整個旅行檔案進行推理:
三個航班選項的比較,含轉機和無障礙細節
四個飯店候選的輪椅無障礙評級和定價
兩份涵蓋日間遊覽的旅遊套裝提案
JR Pass 成本效益分析、簽證清單,以及與同一預訂綁定的無障礙備註
如果每次後續提問都觸發一輪新的檢索、產生不同的 top-k 切片,麻煩就來了:
證據可能在不同的檢索結果間碎片化
微小的排序變化導致不同輪次之間答案不一致
系統花時間重新發現同樣的旅行檔案材料
引用產生漂移,因為每個答案都是從略有不同的子集中拼出來的
這就是團隊開始在純檢索之外另尋方案的實際邊界。問題不是檢索失敗了,而是目前進行中的任務需要一個穩定、有界限的工作集合。
CAG 的真正含義
CAG——Chan et al. 論文中所稱的快取增強生成(cache-augmented generation)——應該看成新興術語,而非已確立的業界教條。論文的核心概念比許多網路摘要暗示的要窄:如果相關知識資源有限且規模可控,你可以把它們預載到模型的上下文中,為那組知識增強的提示詞預先計算鍵值對(KV)快取,然後在後續查詢中重複使用這個快取狀態,而不是每次都做即時檢索。KV 快取預計算正是使其具備實用性的關鍵機制:後續查詢跳過知識部分的檢索和提示詞處理,只需支付將新查詢編碼到已快取前綴上的成本。
這個框架有用,但也有邊界。
首先,CAG 不是 RAG 的通用替代品——它假設語料庫小到能整個放進設計裡。其次,它不等同於「模型有一個很大的上下文視窗」。長上下文是一種能力,CAG 是在受限條件下利用這個能力的架構模式。第三,這個術語在業界還不算穩定的類別。許多行為類似的系統根本不用這個名稱。
最簡單的理解方式:
RAG問的是:如何從更大的儲存庫中擷取正確的證據?CAG問的是:當相關知識有限,是否應該預載它並重複使用已載入的狀態?
這個區別之所以重要,是因為它讓決策回歸到語料庫特性,而不是品牌行銷。一個更新頻率低的小型產品手冊助理,可能是合理的偏 CAG 案例。一個持續更新的大型法律研究語料庫就不是。
長上下文不是免費的智慧
更大的上下文視窗催生了一種取巧的設計慣性:檢索太難?那就把更多文字放入提示詞。但這不是證據選擇的可靠替代方案。
長上下文模型仍然需要在視窗內關注正確的材料。Lost in the Middle 的研究結果(Liu et al., 2024)是一個有用的警示:當相關資訊被埋在長輸入的中間——尤其是重要細節不在開頭或結尾時——效能可能下降。這種效應的嚴重程度因模型而異,在較新的架構中似乎有所改善,因此應視為經驗上觀察到的傾向,而非鐵律。但底層的教訓不變:更大的視窗不能消除策劃和結構化上下文的需求。
這帶來兩個實際後果。
第一個是品質問題。把一個過大的封包放入上下文,模型可能忽略飯店比較中的關鍵價格欄位、過度重視重複的取消條款,或無法把正確的無障礙備註對應到正確的物業列表。更大的視窗提高了可納入內容的上限,但不保證這些材料會被有紀律地使用。
第二個是經濟問題。大型提示詞有實際的前綴填充成本和延遲。就算模型技術上接受了這些上下文,反覆重建同一個前綴可能太慢或太貴。任何聲稱長上下文「更快」的說法,都得附帶攤銷條件:只有當同一個大型前綴被重複使用夠多次、足以合理化初始成本時,才說得通。
所以「把整個知識庫放入上下文」通常是誤判了類別。有限語料庫或範圍很緊的任務可能適用,但它不是通用的基礎化策略。
提示詞快取與此不同
提示詞快取(prompt caching)是另一個容易混淆的地方。廠商提供的提示詞快取是一種執行時期最佳化,在提示詞前綴被重複使用時降低成本和延遲。它本身不定義系統怎麼選擇知識、怎麼更新證據,也不區分持久儲存和暫時上下文。
之所以容易混淆,是因為一個系統可能同時用到:
組裝有界限證據封包的架構
為後續呼叫快取重複前綴的平台功能
這兩者互補,而非等價。提示詞快取不會把糟糕的證據封包變好,不會改善檢索的召回率,也不會讓過時的材料變新鮮。最好把它理解成一種執行最佳化,疊加在更高層級的基礎化設計之上。
對技術決策者來說,這是一個實用的健全性檢查:如果有人提案說「我們不需要檢索,因為平台會快取提示詞」,那就是把系統的兩個不同層次混為一談了。一個是執行效率,另一個是知識架構。
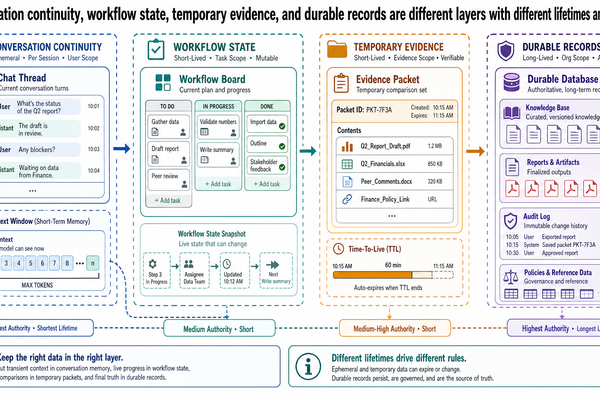
工作記憶是暫時的,不是持久的
「工作記憶(working memory)」這個說法比單獨說「記憶」更精確。它指的是模型當前用來處理任務的活躍材料,不是持久的真理儲存庫,也不是組織知識的長期記錄。
在 JPN-2026-0417 旅行檔案中,一個有界限的證據封包可以作為當前案件的工作記憶:
三個候選航班選項,含轉機和無障礙細節
四份飯店比較,含輪椅無障礙評級
兩份旅遊套裝提案
JR Pass 分析和簽證清單
當前的問題以及已比較內容的中間筆記
這個封包可以支撐初始的行程建議和接下來幾個問題。但它仍然是暫時狀態。它不能取代來源儲存庫,也不能自動用於其他預訂。如果它過時或不完整了,正確做法是從權威來源重新組裝,而不是假裝暫時的上下文已經變成持久知識。
這種區分在營運上非常重要。團隊一旦把活躍的任務上下文當成經過策劃的知識庫,就會出問題。結果通常是無聲的漂移:舊的票價報價還留在封包中、較新的供應商庫存從來沒被拉進來,系統卻自信滿滿地根據昨天的工作集合作答。
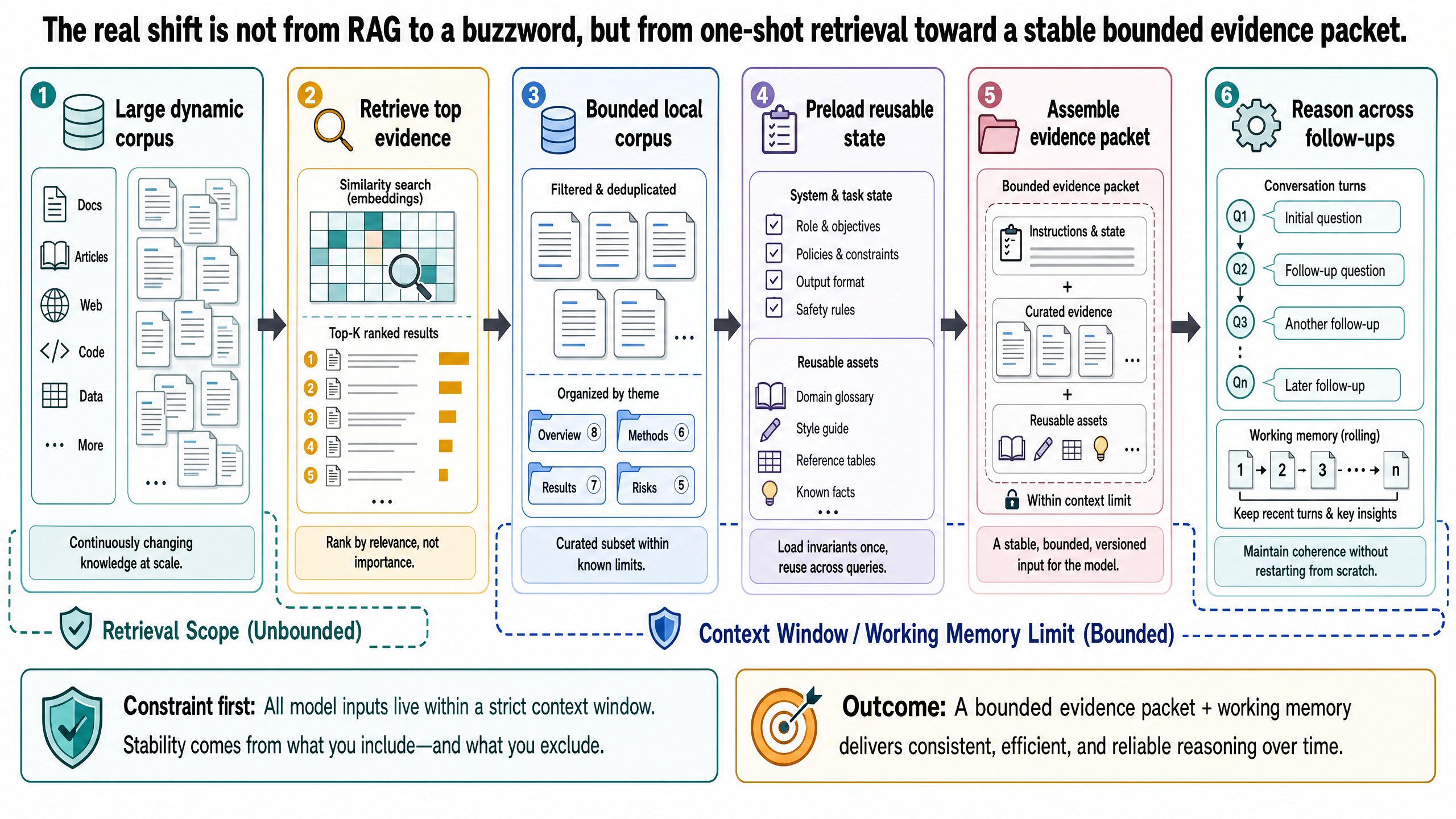
混合基礎化:廣泛檢索、局部推理(Retrieve Broadly, Reason Locally)
在許多進階系統中,最實用的模式不是「RAG 對上 CAG」,而是混合式:從更大的語料庫中廣泛檢索,然後在有界限的證據封包上做局部推理。
與其把它當流行語,不如理解成一種設計模式。架構很直觀:
透過檢索搜尋大型且動態的語料庫
組裝任務專屬的證據封包
將封包放入模型的活躍上下文中,作為暫時的工作記憶
從該有界限的封包中回答主要問題和後續問題
任務改變或證據過時時,重新整理或重建封包
對旅行 Copilot 來說,檢索仍然負責在廣泛的知識庫中找到正確的航班庫存、飯店合約、無障礙稽核和供應商條款——這些工作不可或缺。但一旦系統把 JPN-2026-0417 旅行檔案隔離出來,模型就可以在接下來幾輪分析中持續錨定在這個局部封包上。
這種模式有幾個具體優勢:
搜尋和可擴展性與外部語料庫綁定,不受限於上下文視窗大小
後續答案可以更一致,因為來自同一個封包
系統可以刻意地結構化封包,而不是每一輪都依賴新的 top-k 結果
同一封包被重複使用時,執行時期快取可能有幫助,但不改變架構邊界
同樣重要的是,混合基礎化也有其明確的失敗模式:
初始檢索仍然可能遺漏關鍵證據
封包可能膨脹,重新製造出它原本要解決的長上下文問題
合成橫跨太多鬆散組織的片段時,引用忠實度可能下降
團隊可能不再更新封包,即使來源語料庫已經改變
所以混合不等於「塞更多文字」。它是一種兩階段設計,分工明確:檢索負責廣泛搜尋,有界限的上下文負責局部推理。
決策標準:RAG、偏 CAG,還是混合式
在這些模式之間做選擇,最清楚的判斷依據是四個變數:語料庫大小、更新頻率、後續追問深度,以及對預載成本的容忍度。
適合以 RAG 為主的設計:
語料庫龐大或持續變化
每個問題可能需要不同的證據切片
溯源和新鮮度是首要需求
多數互動是一次性或淺層的後續追問
適合偏 CAG 的設計:
相關知識資源確實有限且規模可控
更新頻率低到預載在營運上合理
同一個已載入的上下文將被重複使用足夠多次來合理化其成本
系統不依賴於在更大儲存庫中進行開放式搜尋
適合混合設計:
語料庫太大或太動態,無法整體預載
活躍任務在檢索後收窄到一個有界限的案件檔案
使用者針對同一證據封包提出多個後續問題
輪次間的一致性比每次重新執行檢索更重要
這裡也該直接指出一個常見誤解:這些不是互斥的類別。許多正式環境系統的外層是以 RAG 為主,只在局部任務邊界內呈現類 CAG 行為。
本文不討論的內容
這不是第二篇記憶文章。第四篇已區分了對話記憶、任務狀態、工作記憶和持久知識。本文將工作記憶視為既定概念,專注在如何填充它:何時標準檢索就夠了、何時有界限的預載有幫助,以及何時混合基礎化才是正確模式。這也不是一篇文件智慧(document intelligence)文章——表格、版面和跨文件匹配的結構性挑戰留到第八篇討論。
常見的誤解
一個常見的錯誤是以為文件放得進上下文,架構問題就算解決了。其實不然。相關性選擇、證據排序和封包結構仍然很重要。
另一個錯誤是把 CAG 當成一個成熟的傘式術語,期待它能替業界做出清楚的分類。實際上辦不到。概念有用,但標籤仍在形成中,應該謹慎使用。
第三個錯誤是以為混合基礎化就是把更多資料放入提示詞。真正的模式是有選擇性的:先廣泛檢索,再建立一個為當前任務量身打造的有界限封包。
最後一個反覆出現的錯誤是把案件封包當成長期記憶。工作記憶是暫時的。持久的知識仍然屬於受治理的來源系統和索引儲存庫。
需要在設計中預防的失敗模式
進階基礎化策略往往會以可預測的方式失敗。
過時的上下文是其中之一。預載的手冊、舊的證據封包或重複使用的前綴,可能悄悄地偏離真理來源。
中段上下文遺失(middle-context loss)是另一個。即使正確的事實確實在封包中,一旦封包過大或組織不當,模型可能無法好好利用它。
攤銷假設在實務中也可能不成立。大型前綴只有在被重複使用夠多次時才划算。每一輪都重建不同封包的話,預期的延遲優勢就消失了。
成長也可能打破有限語料庫的假設。適用於小型手冊或狹窄產品目錄的模式,一旦語料庫擴張或更新頻率提高,可能就不再適用了。
最後,在合成壓力下引用品質可能下降。模型跨多個片段推理時,更容易產出聽起來有根據、卻分不清哪個來源支撐哪個主張的答案。這是系統設計問題,不只是模型問題。
工程師的實務指引
先假設純 RAG 就夠了,直到工作負載證明並非如此。更複雜的架構應該自行承擔舉證責任。
簡單 RAG 開始力不從心時,找具體的症狀,別追趨勢標籤。使用者是否針對同一批證據反覆追問?檢索是否回傳了正確文件卻沒維持穩定的案件上下文?延遲是否被同一前綴的反覆重建拖慢了?這些都是考慮加入有界限工作記憶層的具體理由。
如果你採用混合模式,把邊界說清楚:
哪個檢索系統負責選擇封包
封包裡放什麼、以什麼結構
封包存活多久
何時必須刷新
引用如何保留回來源記錄
這種明確性才是讓「混合基礎化」不淪為空話的關鍵。每一層都有清楚的職責,整個設計才真正有用。
通往文件智慧的橋樑
本文主要把證據當成文字加上擷取的結構化資料。這個簡化即將不夠用了。
在真實的旅行和企業系統中,許多最棘手的檢索問題不在於找到正確的文件,而在於找到文件裡正確的費率表、無障礙證明、取消條款、版面區域和跨頁關係。一旦證據封包包含了供應商 PDF、比較圖表、物業平面圖和視覺結構,組裝工作記憶就變成了一個文件智慧(document intelligence)問題,不再只是檢索問題了。
這就是通往下一篇的橋樑。在系統能為長上下文推理建立可靠的證據封包之前,它首先必須理解文件本身是怎麼結構化的。
來源附註
本文參考以下主要與官方來源:
Lewis, P., Perez, E., Piktus, A., et al. "Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks." RAG 作為外部記憶條件化生成的基準參考。arxiv.org/abs/2005.11401
Chan, C.-M., Xu, C., Yuan, R., et al. "Don't Do RAG: When Cache-Augmented Generation is All You Need for Knowledge Tasks." 有界語料 CAG 模式的參考;本文將 CAG 視為仍在形成中的術語,而非穩定產業分類。arxiv.org/abs/2412.15605
Liu, N. F., Lin, K., Hewitt, J., et al. "Lost in the Middle: How Language Models Use Long Contexts." 說明更大上下文窗口並不會消除證據選擇問題的參考。aclanthology.org/2024.tacl-1.9
OpenAI. "Prompt caching." 用來區分執行期提示快取最佳化與檢索、記憶政策或知識架構的官方參考。developers.openai.com/api/docs/guides/prompt-caching
Anthropic. "Context windows." 將上下文視為有界工作記憶,而非無限可靠知識的參考。docs.anthropic.com/en/docs/build-with-claude/context-windows
Huang Tzu Lin
With over five years in autonomous robotics, there's a strong passion for incorporating cutting-edge technologies and innovative approaches. Dedicated to transforming the latest research and insights into practical applications, this journey pushes the limits of possibility.
相關文章
訂閱最新資訊
將最新技術洞察直接送到您的信箱。