Paged KV Cache: GPU Memory Management for LLM Serving
Reading order
LLM Inference Infrastructure
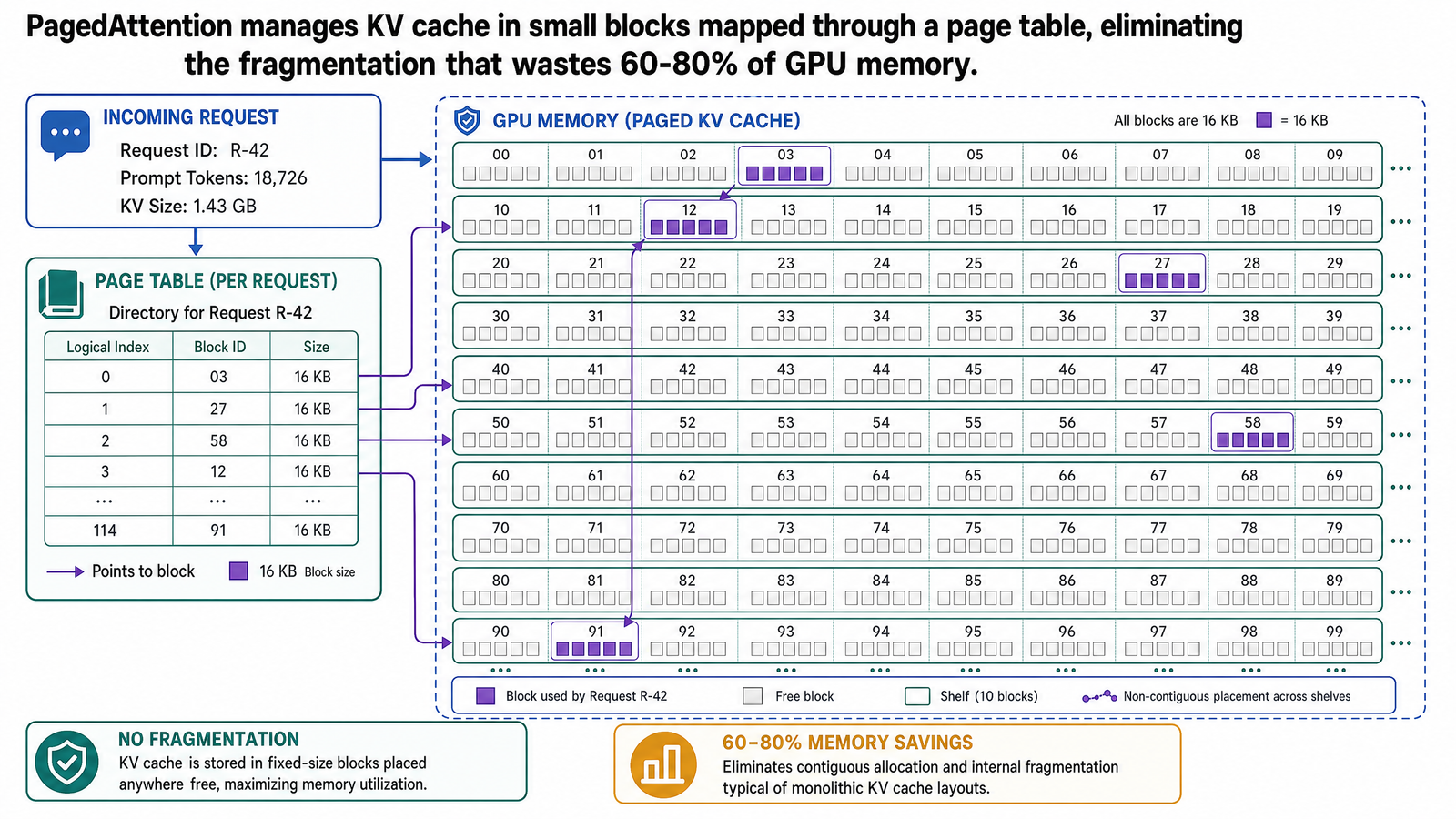
Table of Contents
- The Memory Problem
- How Existing Systems Waste Memory
- The Virtual Memory Analogy
- PagedAttention: How It Works
- Block Tables and Non-Contiguous Allocation
- Running Example: 50 Copilot Users, Before and After
- Before PagedAttention
- After PagedAttention (block size = 16 tokens)
- Impact on Serving Capacity
- What This Post Is Not
- Source Notes
In Post I-00, we traced a single API call through the inference pipeline and introduced the KV cache: the data structure that stores attention key-value vectors so the model does not recompute them at every decode step. The KV cache grows with every generated token, and it must reside in GPU memory for the entire duration of a request. Post I-01 introduced continuous batching, which keeps more requests active simultaneously by scheduling at the iteration level rather than waiting for the slowest request in a batch to finish.
Put those two facts together and the problem becomes visceral. You have 50 travel agents using the OptiVerse copilot during peak booking season. Each agent's request is generating tokens one at a time, growing its KV cache with every step. Continuous batching means many of those requests are active at the same time. And the GPU has a fixed amount of memory to hold all of them.
The question is not whether to cache -- KV caching is not optional, as I-00 established. The question is how to manage the memory that caching requires. Get it wrong, and a GPU with 80 GB of memory might effectively serve only 8-12 concurrent requests. Get it right, and the same hardware serves 40-50.
The Memory Problem
Model weights are large, but they are fixed. Once loaded onto the GPU, they do not grow or shrink during serving. The KV cache is different. It is dynamic: it starts empty, grows with every token, varies in size across requests, and must be allocated and freed as requests arrive and depart.
This dynamism makes the KV cache the dominant variable consumer of GPU memory during inference. For a typical 7-billion-parameter model served in half-precision (FP16), the model weights occupy roughly 14 GB. The KV cache for a single request can consume hundreds of megabytes, and it scales linearly with sequence length. With 50 concurrent requests, the aggregate KV cache easily exceeds the memory used by the model itself.
The deeper problem is unpredictability. When a request arrives, the inference engine knows the input length but does not know the output length. A hotel-availability query might generate 100 tokens or 500, depending on how many matching hotels exist. The engine must allocate memory for the KV cache before the output length is known.
This creates a decision that existing systems, as of 2023, handled badly.
How Existing Systems Waste Memory
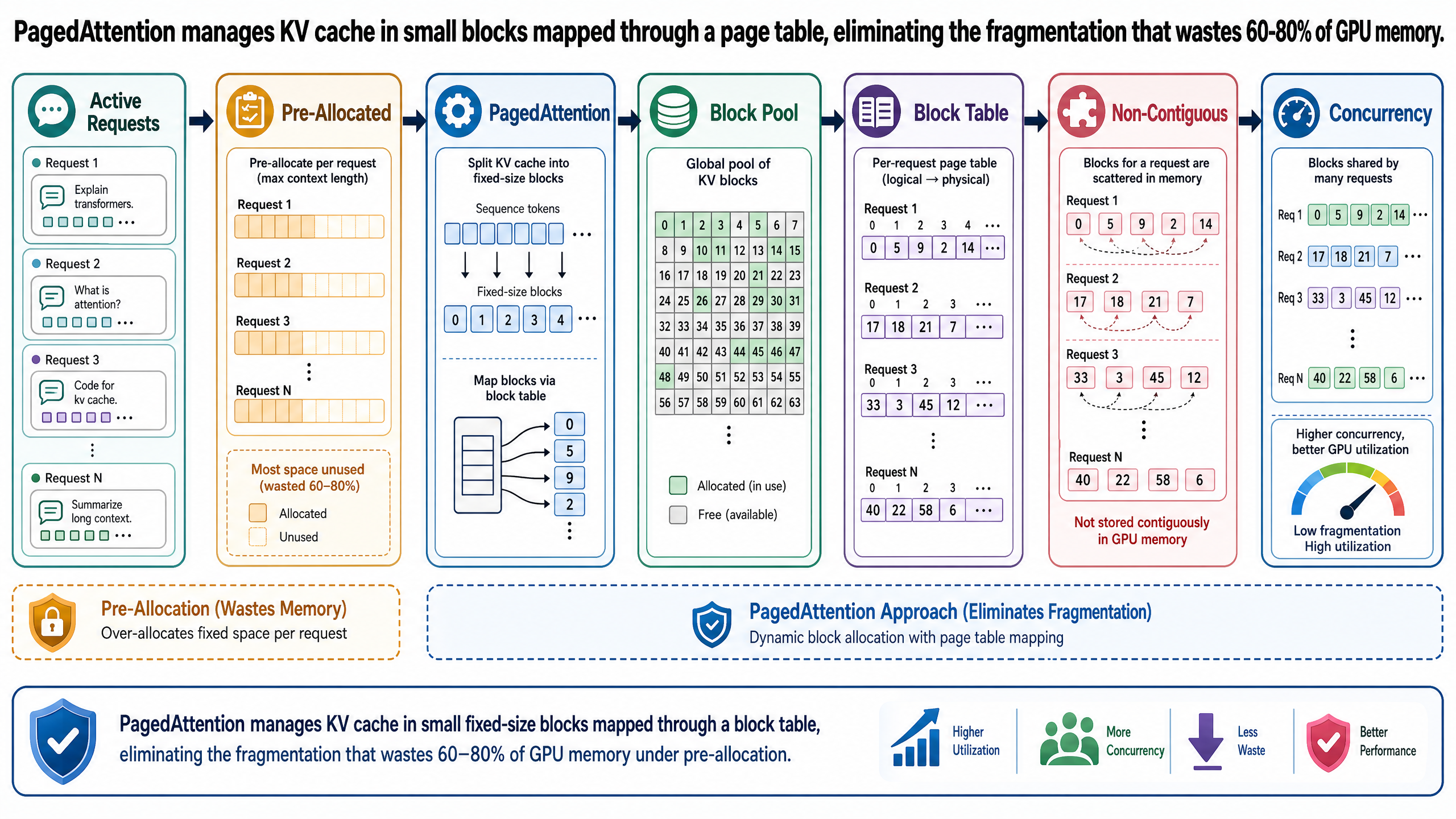
Before PagedAttention, inference engines managed KV cache memory through a straightforward approach: when a request arrives, pre-allocate a contiguous block of GPU memory large enough to hold the maximum possible sequence length. If the model supports up to 2,048 tokens, reserve space for 2,048 tokens of KV cache, regardless of how many tokens the request will actually use.
This strategy produces three distinct types of waste.
Internal fragmentation. A request is allocated space for 2,048 tokens but generates only 400. The remaining 1,648 token slots sit allocated but empty for the lifetime of that request. No other request can use them. The memory is not technically "free" from the system's perspective -- it belongs to the active request -- but it holds nothing useful.
External fragmentation. Requests have different lifetimes. Some finish quickly; others run long. As shorter requests complete and free their memory, the resulting gaps are scattered across GPU memory. Even if the total free memory is sufficient for a new request, no single contiguous region may be large enough to hold a new 2,048-token allocation. The memory exists, but it is unusable.
Over-reservation. Because the system cannot predict output length, it must reserve for the worst case. A request that will generate 200 tokens is allocated the same memory as one that will generate 2,000. The excess is locked away, inaccessible to other requests, for no benefit.
The combined effect is severe. Kwon et al., in the 2023 paper that introduced PagedAttention, found that existing systems waste 60-80% of KV cache memory through these three mechanisms. Only 20-38% of allocated KV cache memory actually held useful data. The rest was fragmentation and over-reservation (Kwon et al., "Efficient Memory Management for Large Language Model Serving with PagedAttention," SOSP 2023).
To put that in concrete terms: a GPU with 40 GB available for KV cache was effectively using 8-15 GB. The remaining 25-32 GB was allocated but wasted.
The Virtual Memory Analogy
This problem -- dynamic allocation, variable lifetimes, unpredictable sizes, fragmentation -- is not new. General-purpose operating systems solved it decades ago with a technique called virtual memory paging.
If you have not taken an operating systems course, here is the core idea in three paragraphs.
When a program runs on your computer, it sees what looks like a large, contiguous block of memory -- its own private address space. The program can read from address 0, write to address 1,000, jump to address 50,000. From the program's perspective, its memory is one continuous stretch.
In reality, the operating system has divided physical RAM into small, fixed-size units called pages (typically 4 KB each). The program's contiguous address space is an illusion. The data at virtual address 0 might physically reside at RAM location 80,000. The data at virtual address 4,096 might physically reside at RAM location 12,000. The physical locations are scattered, non-contiguous, allocated from wherever free pages are available.
The magic is in the page table: a lookup structure that maps each virtual page to its physical location in RAM. The program says "give me data at address 5,000." The operating system looks up the page table, finds that the corresponding virtual page lives at physical page 312, and retrieves the data from there. The program never knows. It sees contiguous memory. The OS handles the translation. This eliminates fragmentation because pages can be placed anywhere -- there is no need for a contiguous physical region.
PagedAttention applies this same idea to GPU memory for KV cache.
PagedAttention: How It Works
Instead of allocating one large contiguous block per request, PagedAttention divides the KV cache into fixed-size blocks. Each block holds key-value vectors for a fixed number of tokens -- typically 16 tokens per block in practice.
Physical blocks are not pre-reserved for any request. They sit in a global free-block pool shared across all active requests. When a request needs more KV cache space, it draws a block from the pool. When a request completes, its blocks return to the pool immediately.
The critical innovation is that a request's blocks do not need to be contiguous in GPU memory. A request might use Physical Block 7 for its first 16 tokens, Physical Block 3 for its next 16 tokens, and Physical Block 12 for the next batch. The blocks are scattered across GPU memory, allocated from wherever free blocks happen to be available.
The model, meanwhile, sees none of this. From the attention mechanism's perspective, the KV cache is a contiguous sequence of key-value vectors. The mapping between what the model sees and where the data physically resides is handled by a structure called the block table.
Block Tables and Non-Contiguous Allocation
Each request has its own block table. It is a small lookup structure -- the GPU analog of an OS page table -- that maps logical blocks to physical blocks.
Logical blocks are what the model sees: a contiguous sequence of KV cache. Logical Block 0 holds the key-value vectors for tokens 0-15. Logical Block 1 holds tokens 16-31. Logical Block 2 holds tokens 32-47. The model computes attention as if these were laid out in order.
Physical blocks are where the data actually lives in GPU memory. They can be anywhere. The block table records the mapping: Logical Block 0 is at Physical Block 7. Logical Block 1 is at Physical Block 3. Logical Block 2 is at Physical Block 12.
Each block table entry also records how many positions in that physical block are filled. If a request has generated 41 tokens (with a block size of 16), the block table shows:
Logical Block — Physical Block — Filled Positions
0 — 7 — 16 / 16
1 — 3 — 16 / 16
2 — 12 — 9 / 16
When the model generates token 42, its key-value vectors are appended to Physical Block 12, position 10. When that block fills at token 48, a new physical block is allocated from the free pool and linked via a new block table entry. When the request finishes, all three physical blocks return to the pool.
The attention kernel has been modified to work with this indirection. Instead of reading a contiguous memory range, it fetches KV vectors block by block, consulting the block table for each physical location. The overhead of this lookup is small compared to the attention computation itself -- and the memory it recovers is enormous.
One additional capability deserves a brief mention. Because the block table is just a mapping, multiple requests can share the same physical block. If two requests have an identical system prompt, their KV cache for the prompt tokens can point to the same physical blocks rather than storing duplicate copies. This sharing uses reference counting and a copy-on-write mechanism: a shared block is only duplicated when one of the requests needs to modify it. This capability is explored in detail in Post I-04, where prefix-aware routing makes it systematic.
Where this meets the application series. In Post 07 of the application series, the KV cache appeared as an application-level concept: prompt caching and cache-augmented generation as developer-facing features for reducing cost and latency. Here we are looking at something different -- how the KV cache is physically managed inside GPU memory by the inference engine. Post 07 is above the API boundary: what the developer controls. This post is below it: what the inference engine does. Both mention "KV cache," but they operate on different sides of the stack.
Running Example: 50 Copilot Users, Before and After
Return to the 50 concurrent travel agents from I-00 and I-01. Each agent sends a hotel-availability query with a system prompt (200 tokens), retrieved hotel context (400-800 tokens), and a user query (25 tokens) -- roughly 625 to 1,025 input tokens. Output lengths vary from 100 to 500 tokens depending on the number of matching hotels. Total per-request sequence length: 725 to 1,525 tokens, with a model maximum of 2,048.
Before PagedAttention
Each request is pre-allocated a contiguous KV cache for the full 2,048 tokens. Consider a typical request with 625 input tokens and 200 output tokens -- 825 tokens actually used.
Allocated: 2,048 token slots
Used: 825 token slots
Wasted per request: 1,223 token slots (60% internal fragmentation and over-reservation)
With 50 concurrent requests each demanding a 2,048-token contiguous allocation, the GPU runs out of memory fast. In practice, only 8-12 concurrent requests fit. The remaining 38-42 agents are queued, waiting. Their users stare at a loading spinner.
As those 8-12 requests finish and free their memory at different times, external fragmentation sets in. The released memory is scattered in chunks that may not be large enough for a new 2,048-token contiguous allocation. The GPU has free memory but cannot use it. Effective utilization: 20-38% of allocated KV cache memory.
After PagedAttention (block size = 16 tokens)
The same 825-token request now occupies ceil(825 / 16) = 52 blocks. Each block holds exactly 16 tokens of KV cache.
Allocated: 52 blocks (832 token slots)
Used: 825 token slots
Wasted: 7 token slots in the last block (825 mod 16 = 9 filled, 7 empty)
Waste per request: under 1%
Blocks are allocated one at a time, from wherever free blocks are available. There is no contiguous allocation requirement, so there is no external fragmentation. There is no pre-reservation for 2,048 tokens, so there is no over-reservation. The only waste is in the last block of each sequence -- at most 15 tokens per request (block_size - 1).
With near-zero waste, the GPU can hold 40-50 concurrent requests. All 50 travel agents are served simultaneously. Nobody is queued. The same hardware, the same model, the same queries -- the only difference is how memory is managed.
The capacity improvement is 4-5x: from 8-12 concurrent requests to 40-50, on identical hardware.
Impact on Serving Capacity
Memory efficiency translates directly to serving capacity. Every physical block recovered from waste is a block that can serve a real user. This is not an abstract optimization. It is the difference between an infrastructure team needing five GPUs and needing one.
The vLLM system, built on PagedAttention, demonstrated this concretely. Against optimized serving systems that already used continuous batching -- specifically FasterTransformer and Orca -- vLLM achieved 2-4x higher throughput at the same latency level. The improvement comes from memory management alone: continuous batching was already present in the baselines. Against naive serving with HuggingFace Transformers (which uses neither continuous batching nor paged memory management), the improvement reaches up to 24x. That larger number combines both optimizations and should be understood as the ceiling, not the isolated contribution of PagedAttention.
The practical implication for engineers building AI systems is this: memory management is not a secondary infrastructure detail. It is the primary bottleneck for concurrent LLM serving. Two inference engines using the same model on the same GPU can differ by 4-5x in the number of concurrent users they serve, based entirely on how they manage KV cache memory.
This is also why the "just add more GPU memory" instinct is misleading. A GPU with 80 GB of memory running pre-allocated KV caches might effectively use only 16-30 GB for actual data. Adding memory without fixing fragmentation gives you more memory to waste. The leverage is in allocation strategy, not in raw capacity.
What This Post Is Not
This post covered how the inference engine manages GPU memory for KV cache: the fragmentation problem, the OS paging analogy, and how PagedAttention eliminates waste through block-based allocation and block tables.
It did not cover several related topics that belong to other posts.
Application-level caching decisions -- when to use prompt caching, cache-augmented generation, or hybrid retrieval -- are the subject of Main Post 07. Those are developer-facing choices above the API boundary. This post operates below it.
KV cache reuse across requests -- when multiple requests share a common system prompt and can share physical blocks through prefix-aware routing -- is the subject of Post I-04. PagedAttention enables the sharing mechanism (reference-counted blocks, copy-on-write), but making it systematic requires routing intelligence that I-04 covers.
Prefill-decode disaggregation is the subject of Post I-03. PagedAttention solves the memory problem, but prefill and decode still compete for the same GPU compute. A long-context prefill can stall all the decode steps sharing that GPU, spiking latency for every active user. Disaggregation separates the two phases onto different hardware -- and that separation introduces its own question about KV cache: when prefill runs on one machine and decode runs on another, the KV cache computed during prefill must be transferred. How that transfer works, and what it costs, is I-03's territory.
And when multiple requests share a common prefix -- the same system prompt, the same few-shot examples, the same retrieved context -- there is an opportunity to share KV cache blocks across them rather than computing and storing duplicate copies. That opportunity, and the routing architecture required to exploit it, is the subject of Post I-04.
The memory problem is solved. The compute problem is next.
Source Notes
This post draws on the following primary and practitioner sources:
Kwon, W., Li, Z., Zhuang, S., Sheng, Y., Zheng, L., Yu, C. H., Gonzalez, J., Zhang, H., and Stoica, I. "Efficient Memory Management for Large Language Model Serving with PagedAttention." SOSP, 2023. The primary source for the PagedAttention mechanism, the 60-80% memory waste finding, the under-4% waste result, block table design, virtual memory analogy, memory sharing via copy-on-write, and throughput benchmarks (2-4x over FasterTransformer/Orca). arxiv.org/abs/2309.06180
vLLM Project. "vLLM: Easy, Fast, and Cheap LLM Serving with PagedAttention." vLLM Blog, June 2023. Companion blog post to the SOSP paper with accessible explanations, diagrams, and the 24x throughput improvement benchmark against HuggingFace Transformers. blog.vllm.ai/2023/06/20/vllm.html
vLLM Documentation. "Paged Attention." Technical documentation of the block table structure, block manager, and allocation strategy. docs.vllm.ai/en/stable/design/paged_attention/
Raschka, Sebastian. "Understanding and Coding the KV Cache in LLMs from Scratch." June 2025. KV cache concept, memory sizing formula, and from-scratch implementation. Referenced for KV cache memory sizing context. magazine.sebastianraschka.com/p/coding-the-kv-cache-in-llms
Hugging Face. "Caching." Transformers documentation. Framework-level reference for KV cache behavior and the quadratic-to-linear cost reduction that caching provides. huggingface.co/docs/transformers/en/cache_explanation
Red Hat Developer. "How PagedAttention resolves memory waste of LLM systems." July 2025. Clear breakdown of the three fragmentation types (internal, external, over-reservation) in the context of KV cache allocation. developers.redhat.com/articles/2025/07/24/how-pagedattention-resolves-memory-waste-llm-systems
NVIDIA. "Mastering LLM Techniques: Inference Optimization." NVIDIA Developer Blog. KV cache context and inference optimization landscape. developer.nvidia.com/blog/mastering-llm-techniques-inference-optimization
Huang Tzu Lin
With over five years in autonomous robotics, there's a strong passion for incorporating cutting-edge technologies and innovative approaches. Dedicated to transforming the latest research and insights into practical applications, this journey pushes the limits of possibility.
Related Posts
Stay Updated
Get the latest technical insights delivered to your inbox.