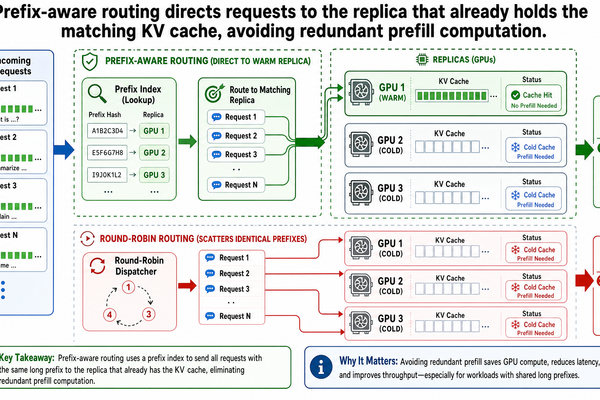
前綴感知路由:考量快取狀態的請求分配
在 I-02 篇中,我們看到 PagedAttention 讓不同的請求能在同一個模型副本(model replica)上共用物理 KV 快取區塊。兩個使用相同系統提示詞(system prompt)的請求可以指向相同的物理區塊,不需要儲存重複的副本。這個共用機制確實有效——但前提是兩個請求必須落在同一個副本上。
Huang Tzu Lin
6 posts
在 I-02 篇中,我們看到 PagedAttention 讓不同的請求能在同一個模型副本(model replica)上共用物理 KV 快取區塊。兩個使用相同系統提示詞(system prompt)的請求可以指向相同的物理區塊,不需要儲存重複的副本。這個共用機制確實有效——但前提是兩個請求必須落在同一個副本上。
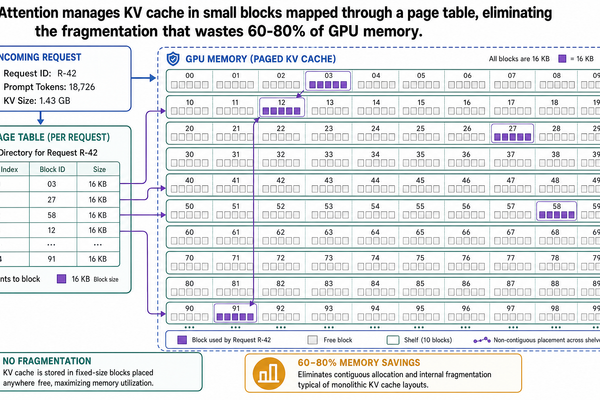
在 I-00 篇中,我們走過了一次 API 呼叫從頭到尾通過推論管線的完整流程,也認識了 KV 快取(key-value cache)——一種用來儲存注意力機制中 key-value 向量的資料結構,讓模型不必在每個解碼步驟重複計算這些向量。KV 快取會隨著每個生成的 token 不斷增長,而且在整個請求期間都必須留在 GPU 記憶體裡。到了 I-01 篇,我們又認識了連續批次處理(continuous batching):它在迭代層級進行排程,不再傻等批次中最慢的請求跑完,因此能讓更多請求同時保持運作。
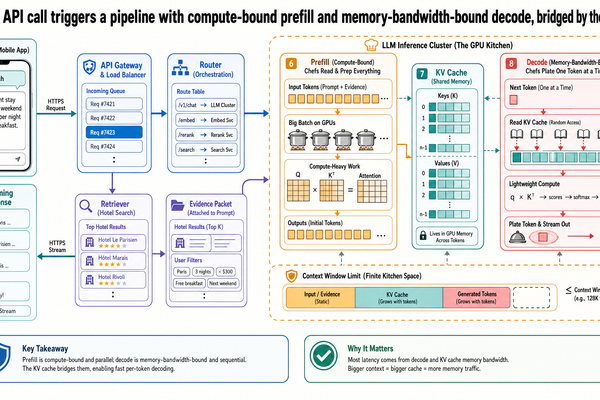
你已經建好一個旅遊小助理。使用者輸入一段查詢,你的應用程式把它送到 LLM 供應商的 API,幾秒後回應串流回來。對應用程式開發者來說,那就是一次函式呼叫。但從基礎設施的角度來看,這一次呼叫觸發了一整條流程(pipeline),牽涉到不同的運算階段、專用的記憶體結構、排程決策,還有硬體限制。這些因素加在一起,決定了使用者實際感受到的延遲、吞吐量和成本。
In Post I-02, we saw that PagedAttention enables different requests to share physical KV cache blocks on the same replica. Two requests with the same system prompt can point to the same physical blocks rather than storing duplicate copies. That sharing mechanism is real and it works -- but only i...
In Post I-00, we traced a single API call through the inference pipeline and introduced the KV cache: the data structure that stores attention key-value vectors so the model does not recompute them at every decode step. The KV cache grows with every generated token, and it must reside in GPU memo...
You have built a travel copilot. A user types a query, your application sends it to an LLM provider's API, and a few seconds later a response streams back. From the application developer's perspective, that is one function call. From the infrastructure's perspective, that function call triggers a...