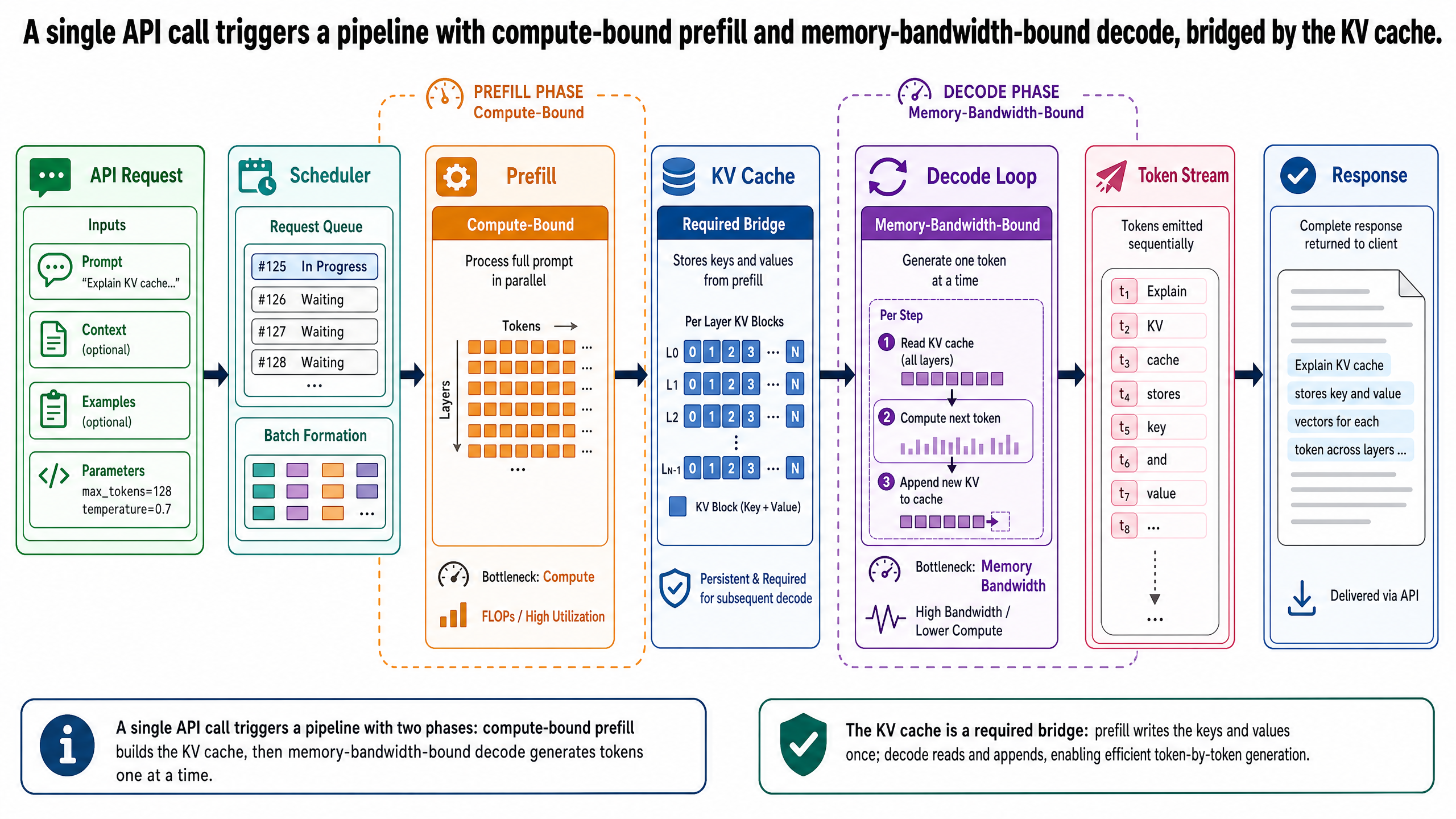
呼叫 API 之後發生了什麼事
閱讀順序
LLM Inference Infrastructure
上一章
尚無可用文章
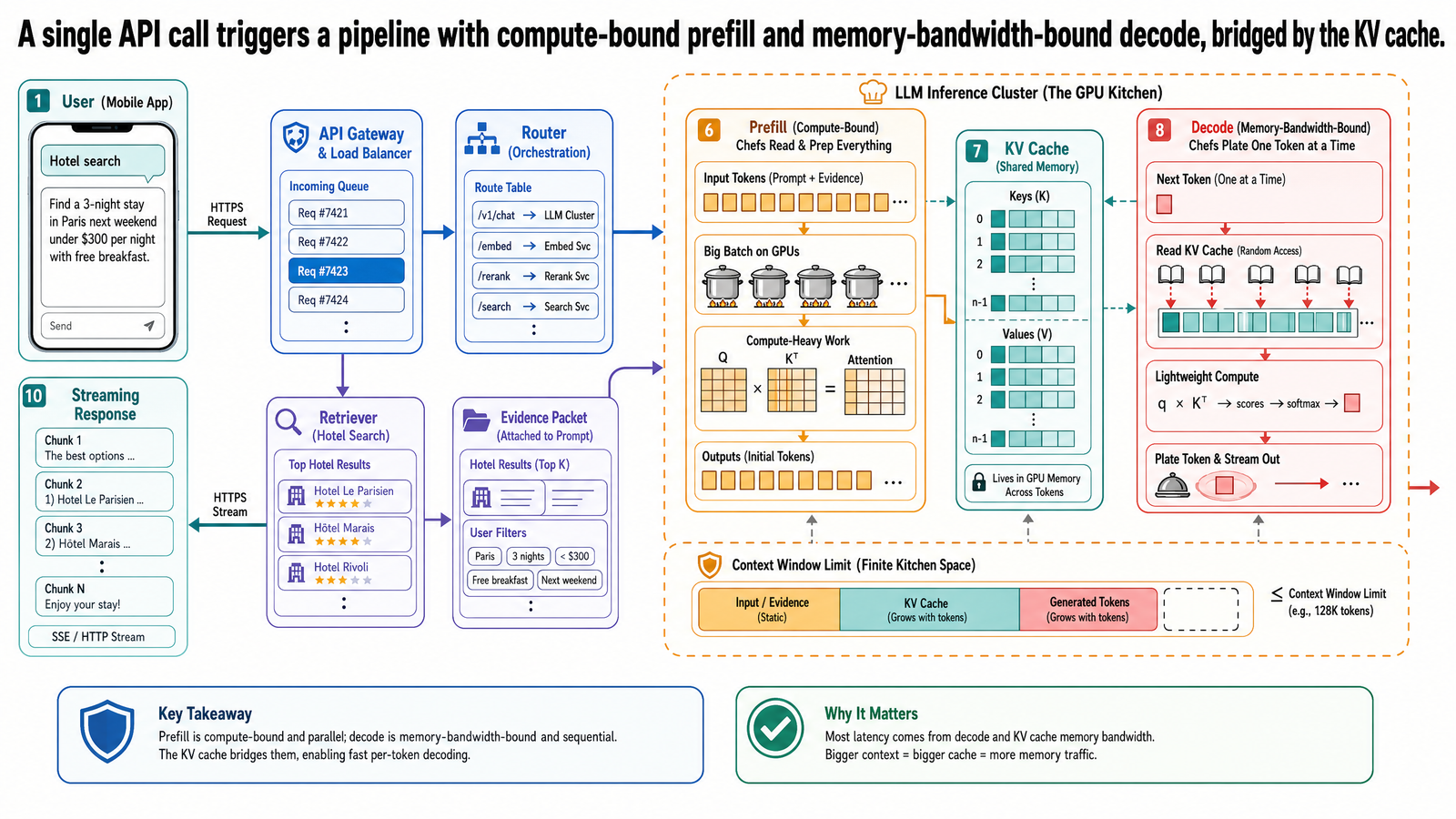
你已經建好一個旅遊小助理。使用者輸入一段查詢,你的應用程式把它送到 LLM 供應商的 API,幾秒後回應串流回來。對應用程式開發者來說,那就是一次函式呼叫。但從基礎設施的角度來看,這一次呼叫觸發了一整條流程(pipeline),牽涉到不同的運算階段、專用的記憶體結構、排程決策,還有硬體限制。這些因素加在一起,決定了使用者實際感受到的延遲、吞吐量和成本。
這篇要做的就是打開這條流程。這裡不討論怎麼開發應用程式——那是主系列的工作。目的是幫你理解 API 底下的機制,這樣你就不會覺得系統的效能特性像個看不透的黑箱。如果你曾經好奇為什麼第一個 token 出現的時間比後續的長、為什麼很長的系統提示詞並沒有像預期那樣拖慢生成速度、或者為什麼供應商對輸入和輸出 token 的收費不同——答案就在這條流程裡。
我們會追蹤一筆查詢——一次無障礙飯店搜尋——從它離開你的應用程式到最後一個 token 送達為止的完整旅程。過程中,我們會介紹五個概念,本系列後續每一篇文章都以此為基礎:注意力機制(attention mechanism)、KV 快取(key-value cache)、生成的兩個階段、GPU 資源限制,以及衡量推論效能的指標。
你已經知道的事
本系列假設你已經讀過 00-1 大型語言模型到底在做什麼 和 00-2 提示、上下文窗口,以及你如何跟 LLM 對話。主應用系列則從 01:從模型到複合式 AI 系統 接續。
讀過 00-1 和 00-2 的話,你就具備了本文所需的詞彙基礎。
從 00-1,你知道大型語言模型透過下一個 token 預測(next-token prediction)來生成文字。模型檢視目前序列中的所有 token——你的輸入加上它已經生成的部分——然後預測下一個 token 的機率分布,從中選一個、附加到序列裡,接著重複。整個回應就是這樣一次一個 token 產出的。
從 00-2,你知道提示和回應共用一個有限的上下文窗口(context window)。你知道 token 是衡量窗口大小和計費的單位。而且你可能注意到一個很容易被略過的重點:輸出 token 比輸入 token 貴。00-2 的定價表顯示,在各大供應商之間,輸出成本大約是輸入的 2 到 10 倍。當時的說明很簡短:「輸出之所以更貴,是因為每個 token 需要循序生成,而非平行處理。」
那句話其實就是本文的出發點。輸入 token 可以平行處理。輸出 token 必須逐一生成。這兩種處理模式各自有截然不同的運算特性、硬體瓶頸與記憶體需求。它們其實是推論中兩個截然不同的階段——理解這件事,是掌握後續所有服務優化的前提。
但要理解為什麼這兩個階段的行為不同,我們得先理解模型在推論過程中到底在計算什麼。00-1 將模型描述為一套系統:根據所有先前的 token 預測下一個 token。這沒錯,但有個關鍵問題還沒回答:模型怎麼判斷前面的 token 中,哪些與當前的預測有關?
答案是一種叫做注意力(attention)的機制。
API 呼叫的旅程
在深入模型內部之前,我們先從高層次追蹤一筆請求的完整旅程。
你的旅遊小助理把以下查詢送到 LLM 供應商的 API:
幫我找京都每晚 200 美元以下、有溫泉且無障礙的飯店。
這筆查詢不是單獨抵達模型的。你的應用程式已經組裝好一份完整的輸入:一段定義小助理行為和格式規則的系統提示(大約 200 個 token)、一段從你資料庫檢索出來的飯店上下文(大約 800 個 token),以及使用者的查詢本身(大約 25 個 token)。總輸入大約 1,025 個 token。
接下來的流程大致如下:
API 伺服器收到你的請求,交給排程器(scheduler)。
排程器把你的請求放進佇列,跟其他同時抵達的請求一起排隊。在正式部署中,可能同時有幾十到幾百筆請求。以我們的例子來說,假設還有另外 49 個代理在差不多的時間提交查詢。
當你的請求排到隊首,GPU 開始處理它。輸入在一個叫做預填充(prefill)的階段中被處理。
預填充完成後,模型在解碼(decode)階段中逐一生成輸出 token。每個 token 一產生就即時串流回你的應用程式。
大約 150 個輸出 token 之後,模型生成一個停止 token,回應完成。
以上是整個流程的骨架。接下來我們會補上細節:注意力在每次前向傳播中計算了什麼、為什麼它的輸出必須被快取、預填充和解碼有什麼不同,以及從使用者端看起來是什麼體驗。
注意力機制如何運作
在下一個 token 預測的過程中,模型必須判斷序列中哪些先前的 token 與預測下一個 token 有關。這可不是只看前一個字那麼簡單。當模型即將在飯店描述中生成「溫泉」這個詞時,相關的上下文可能包括使用者查詢中的「無障礙」(確保溫泉設施本身也是無障礙的)、提示前面出現的「京都」(從正確的地理上下文提取資訊),以及「每晚 200 美元以下」(維持在價格篩選範圍內)。這些 token 散布在輸入的各處,中間隔著好幾百個其他 token。
注意力就是負責這種選擇性聚焦的機制。名稱本身就很直觀:模型「注意」(attend to)序列中與當前預測相關的部分。
概念上,它的運作方式是這樣的。對於序列中的每個位置,模型計算三個東西:
一個
查詢向量(query vector):「我在找什麼?」代表當前位置需要從序列其他部分取得什麼。一個
鍵向量(key vector):「我包含什麼?」代表一個位置能提供給其他正在搜尋的位置的東西。一個
值向量(value vector):「我攜帶什麼資訊?」匹配成功時,實際被提取出來的就是這個。
打個比方。你正在撰寫一份飯店推薦,需要確認前面有沒有提到價格限制。你的查詢是「價格限制」。你翻閱筆記,每張筆記上都有一個標籤(鍵),標示這張筆記涵蓋的內容。當你找到一張標籤跟你要找的東西吻合的筆記——上面寫著「預算:每晚 200 美元以下」——你就從那張筆記中提取詳細資訊(值),用到你正在寫的內容裡。
注意力的運作原理完全相同,差別在於它同時在序列的每個位置上平行進行。模型計算每個查詢與每個鍵的匹配程度,然後提取對應值的加權組合。鍵高度相關的位置對結果貢獻更多;鍵不相關的位置幾乎沒有貢獻。
這個機制最早的完整描述來自 Vaswani et al. 的 "Attention Is All You Need"(2017),也就是引入 Transformer 架構的那篇論文。對我們來說,重點不在數學,而在於一件事:注意力會為每一個被處理的 token 產出一組鍵向量和值向量,編碼該 token 對未來預測的貢獻。這些向量在推論過程中被計算出來,而且必須存在某個地方——這就引出了推論基礎設施中最重要的資料結構。
KV 快取:為什麼推論需要記憶
回想一下,生成是一次一個 token 進行的。模型生成第一個輸出 token 之後,需要生成第二個。要預測第二個 token,它必須注意所有先前的 token:整個 1,025 個 token 的輸入加上剛生成的那一個。要預測第三個 token,它要注意所有 1,026 個先前的 token。以此類推。
如果不做任何優化,每生成一個新 token 都得重新計算前面所有 token 的鍵向量和值向量。第一個輸出 token 需要對 1,025 個 token 做注意力運算。第二個需要對 1,026 個。第 150 個需要對 1,174 個。總運算量隨序列長度呈二次方成長——而對於一個 150 個 token 的回應,模型會對那最初的 1,025 個輸入 token 重複計算相同的鍵值對 150 次。
這不是什麼能輕易優化掉的邊緣狀況,而是必須從架構上正面解決的根本瓶頸。沒有快取的話,即使是中等長度的回應,生成速度也會慢到無法接受。
KV 快取就是解決方案。它儲存已經算好的鍵向量和值向量,讓每個後續 token 生成時可以直接重用。模型在預填充階段處理輸入時,為所有 1,025 個輸入 token 計算鍵向量和值向量,並存入 KV 快取。生成第一個輸出 token 時,把該 token 的鍵值對加入快取。生成第二個輸出 token 時,只需要計算新 token 的查詢、鍵和值向量——所有先前的鍵值對都已經在快取裡了。
你可以把它想成一本筆記本:隨時記錄重點,這樣每次要接著寫的時候,不必從頭重讀整段對話。每寫一句新的,只需要翻閱筆記、加一條新紀錄,而不是重讀整份文件。
KV 快取會隨著每個生成的 token 而增長。預填充之後,它包含大約 1,025 筆條目(每個輸入 token、每一層模型各一組鍵值向量)。生成 150 個輸出 token 之後,它包含大約 1,175 筆條目。以一個有 80 層的模型來說,那就是 1,175 組鍵值對乘以全部 80 層——資料量相當可觀,而且必須留在 GPU 記憶體中以便快速存取。
所以 KV 快取不是一種優化,而是一種必要。每一個正式的推論引擎(inference engine)——vLLM、SGLang、TensorRT-LLM 等——都把 KV 快取當作服務架構的基礎組件來實作,而不是可選的加速功能。
生成的兩個階段:預填充與解碼
有了 KV 快取的概念,我們現在可以精確描述這兩個階段了。
預填充
當你的 1,025 個 token 輸入抵達 GPU 時,模型在一次前向傳播中處理所有 1,025 個 token。這就是預填充階段,也叫提示處理(prompt processing)。預填充期間,模型為每一個輸入 token 計算注意力的鍵向量和值向量,並存入 KV 快取。因為所有輸入 token 事先都已知,這個運算可以平行進行——模型同時處理所有 1,025 個 token,而不是逐一處理。
預填充是運算瓶頸(compute-bound)的。瓶頸在 GPU 的算術處理單元。GPU 有足夠的資料可用(全部 1,025 個 token 都在記憶體裡,隨時可以處理),但需要的是原始運算吞吐量來執行注意力和其他層所需的矩陣乘法。想像晚餐尖峰時段的廚房:食材庫存充足,備料都整齊地放在工作台上。瓶頸在於廚師切菜、炒菜、擺盤的速度。再往工作台上堆更多食材也沒用——廚師的手已經忙不過來了。
解碼
預填充完成後,模型進入解碼階段,也叫生成階段。它逐一生成輸出 token。每生成一個新 token,模型就執行一次前向傳播:用新 token 的查詢向量對 KV 快取中所有鍵值對做注意力運算,生成該 token,把鍵值對加入快取,接著處理下一個。
每一步解碼只處理一個新 token,但它必須從 GPU 記憶體中讀取完整的模型權重和整個 KV 快取。相對於需要載入的資料量,實際的運算量其實很小。
解碼是記憶體頻寬瓶頸(memory-bandwidth-bound)的。瓶頸不在 GPU 的算術單元——那些很快就算完了——而在於資料從 GPU 記憶體讀取並傳送到處理單元的速度。回到廚房的比喻:這時廚師反而閒著,在等食材送過來。助手從食材庫搬運食材的速度有限。廚師幾秒鐘就能處理好一份食材,但從食材庫到工作台的搬運比烹飪本身還花時間。瓶頸就從廚師的處理速度,變成了助手的搬運速度。
這種不對稱是理解 LLM 推論的關鍵。同一套硬體負責兩個階段,但每個階段的瓶頸不同。預填充受限於運算能力。解碼受限於記憶體頻寬。優化其中一個階段不一定能改善另一個,而有利於預填充的策略(更多算術單元)對解碼(需要更快的記憶體存取)可能完全無效。
這也解釋了 00-2 提到的成本不對稱。輸出 token 比輸入 token 貴,是因為每個輸出 token 都需要自己的循序解碼步驟,連帶全部的記憶體頻寬開銷。相比之下,輸入 token 在預填充時一批就平行處理完了。一千個輸入 token 大致相當於一次預填充傳播的運算量;一千個輸出 token 則要一千次循序解碼傳播。
為什麼 LLM 推論不一樣
如果你有其他機器學習系統的經驗——影像分類器、推薦模型、詐欺偵測器——你可能以為 LLM 推論不過就是「載入模型、跑一次前向傳播、回傳結果」的又一個版本。其實不是。LLM 推論有五個根本不同之處,每一個都對應到一個基礎設施問題,由本系列後續的文章來處理。
1. 可變長度的運算。 影像分類器永遠處理 224x224 像素的輸入,回傳固定的類別機率。LLM 接收的輸入從 50 到 100,000 個 token 不等,產出從 1 到 10,000 個 token 不等。每筆請求所需的運算和記憶體完全取決於它的輸入和輸出長度。這種可變長度的特性正是批次處理問題的根源——沒辦法在請求完成時間各異的情況下,直接把它們打包成批次處理。(I-01 會處理這個問題。)
2. 雙階段資源特性。 傳統的模型推論只有一個階段:一次前向傳播。LLM 推論有兩個,而且硬體瓶頸剛好相反。預填充是運算瓶頸;解碼是記憶體頻寬瓶頸。針對其中一個階段優化的 GPU 配置,對另一個階段往往不是最佳的。這種不匹配催生了把兩個階段分配到不同硬體上執行的設計思路。(I-03 會處理這個問題。)
3. 持續增長的記憶體需求。 在解碼期間,KV 快取隨著每個生成的 token 不斷增長。一筆請求起初的 KV 快取佔用量可能不大,但經過長時間的生成之後,可能消耗遠超預期的 GPU 記憶體。系統必須動態管理這種增長——需要時分配記憶體、請求完成時回收,並避免因不同長度的請求交錯開始和結束而造成碎片化浪費。(I-02 會處理這個問題。)
4. 快取感知的路由。 傳統的服務系統中,任何副本都能處理任何請求,負載平衡器用輪替(round-robin)之類的簡單策略分配流量就好。但在 LLM 推論中,如果兩筆請求共用同一段系統提示詞,一個已經快取了該提示詞鍵值向量的副本就可以跳過重新計算。把請求路由到錯誤的副本,等於白白浪費預填充的運算。智慧路由需要知道每個副本已經快取了什麼。(I-04 會處理這個問題。)
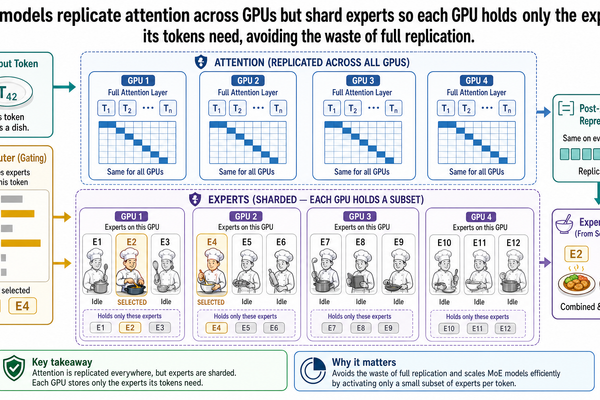
5. 依架構而異的分片策略。 有些現代 LLM 使用混合專家模型(mixture-of-experts, MoE)架構,模型的不同部分會因不同的輸入而被啟用。把 MoE 模型分散到多個 GPU 上,需要跟密集模型不同的分片(sharding)策略——注意力層應該被複製,而專家層應該被分割。分片策略不是通用的平行化決定;它取決於模型的內部架構。(I-05 會處理這個問題。)
以上五個差異,每一個都是專用推論引擎存在的理由。適用於影像模型或推薦系統的通用服務框架,應付不了 LLM 推論所要求的可變長度、雙階段運算、動態記憶體增長、快取感知路由,以及依架構而定的分片策略。vLLM、SGLang 和 TensorRT-LLM 之所以被打造出來,正是因為 LLM 推論是一類根本不同的問題。
重要的指標:TTFT、TPS 和 ITL
既然你理解了兩個階段,就可以來看工程師用來衡量推論效能的指標了。請求層級有三個重要指標,加上一個系統層級的指標。
首 Token 時間(TTFT, time to first token)
TTFT 衡量的是從你的應用程式送出請求到第一個生成的 token 回傳之間的延遲。以我們的飯店搜尋為例,TTFT 就是從提交查詢到回應的第一個字出現之間的時間。
TTFT 包含解碼開始之前發生的所有事情:網路傳輸、在排程器佇列中等待的時間,以及整個預填充階段。如果你前面有 49 筆請求在排隊,等待時間會計入 TTFT。如果你的輸入是 1,025 個 token,預填充的運算也會計入 TTFT。以一個處理我們飯店查詢的中等負載系統來說,典型的 TTFT 可能在 100 到 500 毫秒之間,取決於負載、輸入長度和硬體。
TTFT 是使用者最直接感受到的指標——就是按下「送出」到看見回應開始出現之間那段沉默。200 毫秒的 TTFT 給人即時回應的感覺。2 秒讓人覺得遲鈍。10 秒則讓人以為系統當機了。
Token 間延遲(ITL, inter-token latency)
ITL 衡量的是解碼階段中連續生成的 token 之間的平均延遲。第一個 token 出現之後,每個後續 token 隔一小段時間到達——那段間隔就是 ITL。
以我們的例子來說,飯店回應的第一個字出現後,ITL 決定了回應後續串流進來的流暢程度。20 到 40 毫秒的 ITL 產生平滑、自然的文字串流。變動劇烈的 ITL——20 毫秒、然後 150 毫秒、然後 30 毫秒——會造成斷斷續續的體驗,即使平均速度還可以接受,使用者仍會明顯感到不流暢。
ITL 主要由解碼階段的記憶體頻寬瓶頸決定。每一步解碼都要從 GPU 記憶體中讀取模型權重和 KV 快取,而那次讀取所花的時間,就為 ITL 設定了下限。
每秒 Token 數(TPS, tokens per second)
TPS 衡量的是模型在解碼期間每秒生成多少個 token。簡單來說,它是 ITL 的倒數:如果 ITL 是 25 毫秒,TPS 就大約是每秒 40 個 token。
以我們 150 個 token 的飯店回應為例,按 40 TPS 計算,解碼階段大約需要 3.75 秒。加上 200 毫秒的 TTFT,使用者幾乎立刻看到第一個字出現,完整回應在 4 秒內完成。這是很流暢的體驗。
TPS 是請求層級的吞吐量指標,告訴你單一使用者的回應生成有多快。
吞吐量(系統層級)
在系統層級,吞吐量衡量的是系統每秒在所有並行使用者間總共產出多少個 token(或完成多少筆請求)。在我們 50 個代理的場景中,吞吐量回答的問題是:每秒有多少個代理的回應被完成?
吞吐量跟單一請求的 TPS 不同,因為它取決於系統批次處理和排程並行請求的效率。一個系統對單一使用者可能以 40 TPS 生成 token,但透過把 50 筆請求打包在一起,在所有使用者間達到每秒 1,500 個 token 的總吞吐量。這個區別——單一請求延遲 vs. 系統吞吐量——正是服務優化的核心張力,也是 I-01 的主題。
實例演練:一筆查詢通過整條流程
接下來,讓我們追蹤飯店搜尋查詢通過完整流程的過程,並在時間線上標注每個指標。
輸入:
系統提示:200 個 token(定義小助理的角色、格式規則、無障礙指引)
檢索的飯店上下文:800 個 token(資料庫中京都無障礙且有溫泉的飯店結果)
使用者查詢:25 個 token(「幫我找京都每晚 200 美元以下、有溫泉且無障礙的飯店。」)
總輸入:約 1,025 個 token
T = 0 ms。 你的應用程式向 API 送出請求。
T = 5 ms。 API 伺服器收到請求,交給排程器。排程器看到還有另外 49 筆請求正在處理或排隊中。你的請求進入佇列。
T = 45 ms。 你的請求排到隊首。排程器將它分配給一個 GPU。預填充階段開始。
T = 45-190 ms。 預填充平行處理所有 1,025 個輸入 token。GPU 在每一層執行注意力運算,為每個輸入 token 在每一層產出鍵向量和值向量。這些向量被寫入 KV 快取。預填充結束時,KV 快取在每一層持有大約 1,025 筆條目。這是一個受運算能力限制的操作——瓶頸在 GPU 的算術處理單元。
T = 190 ms。 第一步解碼執行。模型生成第一個輸出 token 並串流回你的應用程式。TTFT = 190 ms。 使用者看到回應的開頭。
T = 190-3,940 ms。 解碼階段再生成 149 個 token,逐一產出。每一步解碼從 GPU 記憶體中讀取模型權重和持續增長的 KV 快取,對所有已快取的鍵值對為新 token 計算注意力,生成 token,將其鍵值對加入快取,並將 token 串流給客戶端。平均 ITL = 25 ms。 KV 快取從每層約 1,025 筆條目增長到約 1,175 筆條目。
T = 3,940 ms。 第 150 個 token 是停止 token。回應完成。TPS = 150 個 token / 3.75 秒 = 每秒 40 個 token。 該請求的 KV 快取被釋放,把 GPU 記憶體讓給其他請求。
使用者的體驗:回應在不到 200 毫秒內開始出現,並在大約 4 秒內流暢地串流完畢。而從基礎設施的角度看,那 4 秒鐘涉及兩個根本不同的運算階段、一個持續增長的記憶體結構,以及在這筆請求和另外 49 筆請求之間取得平衡的排程決策。
這個追蹤是本系列其餘部分的參考範例。當 I-01 討論如何把這筆請求和其他請求做批次處理時,1,025 個輸入 token 和 150 個輸出 token 是具體的數字。當 I-02 討論記憶體管理時,KV 快取從 1,025 增長到 1,175 筆條目是具體的成本。當 I-04 討論前綴快取(prefix caching)時,50 個代理之間完全相同的 200 個 token 系統提示就是具體的優化機會。
本文不涵蓋的內容
本文介紹了推論流程:注意力機制、KV 快取、預填充和解碼、GPU 資源特性,以及描述效能的指標。它追蹤了一筆請求通過完整生命週期的過程。
但它沒有處理的是:當系統必須同時應付大量這類請求時,會發生什麼事。
在正式部署中,那 50 個並行的代理不會整齊地排成順序佇列。它們同時抵達,各自有不同的輸入長度和不可預測的輸出長度。有些請求很快就結束;有些會生成很長的回應。天真的批次處理——把請求打包在一起、等最長的那個跑完——會把 GPU 資源浪費在填充(padding)上,讓批次中多數已完成的請求在等待最慢那筆請求生成完畢的同時閒置。當 50 筆這樣的查詢同時湧入,排程器就必須採取根本不同的做法。
那就是 I-01 的主題:連續批次處理(continuous batching),一種以單次解碼迭代而非完整請求為粒度進行排程的技術。
那個持續增長的 KV 快取呢?它需要存在 GPU 記憶體中——而那塊記憶體是有限的、被所有並行請求共用的,而且會因不同長度的請求在不同時間開始和結束而產生碎片化。如果用天真的方式分配,60% 到 80% 的 KV 快取記憶體都會被浪費掉。
那就是 I-02 的主題:分頁式 KV 快取管理(paged KV cache management),把作業系統虛擬記憶體的概念應用到推論基礎設施中,以消除那些浪費。
本文描述的推論流程是基礎。接下來的每一篇,談的都是怎麼讓它在規模化的環境下高效運作。
來源附註
本文參考了以下主要和實務來源:
Vaswani, A., Shazeer, N., Parmar, N., et al. "Attention Is All You Need." NeurIPS, 2017. 引入 Transformer 架構和查詢-鍵-值注意力機制的基礎論文。arxiv.org/abs/1706.03762
NVIDIA. "Mastering LLM Techniques: Inference Optimization." NVIDIA Developer Blog. 預填充/解碼階段區分及其運算受限 vs. 記憶體頻寬受限的特性分析的主要參考。developer.nvidia.com/blog/mastering-llm-techniques-inference-optimization
NVIDIA. "LLM Inference Benchmarking: Fundamental Concepts." NVIDIA Developer Blog. TTFT、ITL、TPS 和吞吐量指標的權威定義。developer.nvidia.com/blog/llm-benchmarking-fundamental-concepts
Raschka, Sebastian. "Understanding and Coding the KV Cache in LLMs from Scratch." June 2025. KV 快取用途、機制和增長特性的主要說明。magazine.sebastianraschka.com/p/coding-the-kv-cache-in-llms
BentoML. "How Does LLM Inference Work?" and "Key Metrics for LLM Inference." LLM Inference Handbook. 雙階段推論模型和指標定義的實務導向說明。bentoml.com/llm/llm-inference-basics/how-does-llm-inference-work and bentoml.com/llm/inference-optimization/llm-inference-metrics
Hugging Face. "Caching." Transformers documentation. KV 快取實作與行為的框架級參考。huggingface.co/docs/transformers/en/cache_explanation
Yu, G., et al. "Orca: A Distributed Serving System for Transformer-Based Generative Models." OSDI, 2022. 引入迭代級排程。作為連續批次處理的歷史背景參考。usenix.org/conference/osdi22/presentation/yu
vLLM documentation: docs.vllm.ai. SGLang project: github.com/sgl-project/sglang. NVIDIA TensorRT-LLM: docs.nvidia.com/tensorrt-llm. 作為本文描述的需求所催生的專用推論引擎範例。
Huang Tzu Lin
With over five years in autonomous robotics, there's a strong passion for incorporating cutting-edge technologies and innovative approaches. Dedicated to transforming the latest research and insights into practical applications, this journey pushes the limits of possibility.
相關文章
訂閱最新資訊
將最新技術洞察直接送到您的信箱。