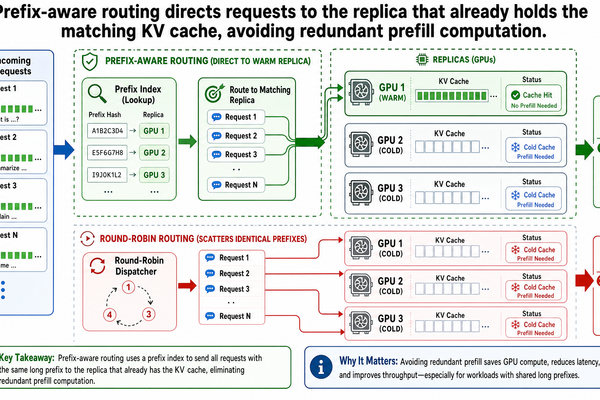
前綴感知路由:考量快取狀態的請求分配
在 I-02 篇中,我們看到 PagedAttention 讓不同的請求能在同一個模型副本(model replica)上共用物理 KV 快取區塊。兩個使用相同系統提示詞(system prompt)的請求可以指向相同的物理區塊,不需要儲存重複的副本。這個共用機制確實有效——但前提是兩個請求必須落在同一個副本上。
Huang Tzu Lin
4 篇文章
在 I-02 篇中,我們看到 PagedAttention 讓不同的請求能在同一個模型副本(model replica)上共用物理 KV 快取區塊。兩個使用相同系統提示詞(system prompt)的請求可以指向相同的物理區塊,不需要儲存重複的副本。這個共用機制確實有效——但前提是兩個請求必須落在同一個副本上。
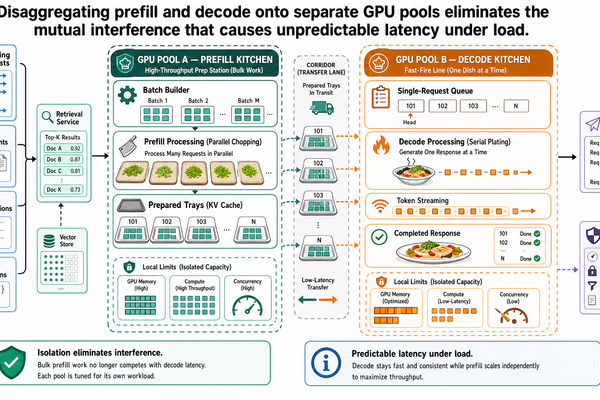
I-00 確立了 LLM 推論具有兩個資源特性截然不同的階段。預填充以平行方式處理所有輸入 token,屬於運算瓶頸(compute-bound)——GPU 的運算單元是限制因素。解碼則逐一生成 token,屬於記憶體頻寬瓶頸(memory-bandwidth-bound)——限制因素在於從 GPU 記憶體讀取模型權重和 KV 快取的速度。I-01 介紹了連續批次處理,它透過在迭代層級而非批次層級進行排程,讓 GPU 保持滿載。I-02 則展示了 PagedAttention 如何消除記憶體浪費,讓更多請求能同時處於活躍狀態。
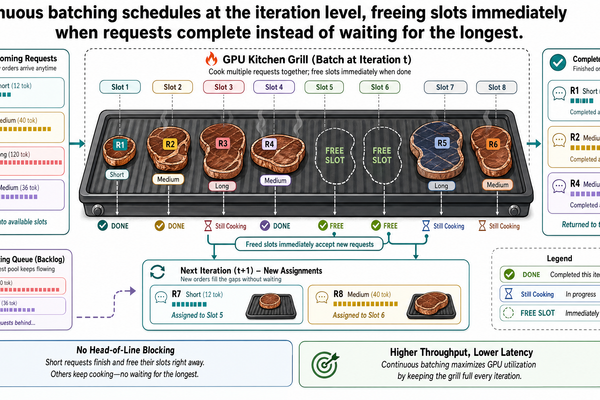
I-00 追蹤了單一請求通過推論流程的完整路徑:預填充(prefill)以平行方式處理所有輸入 token,解碼(decode)逐一生成輸出 token,而 KV 快取(key-value cache)隨著每一步不斷增長。在那篇文章的結尾,我們注意到還有 49 個其他代理人幾乎同時提交了查詢。這個觀察不是隨口帶過——它直接指向推論服務的核心運作問題。
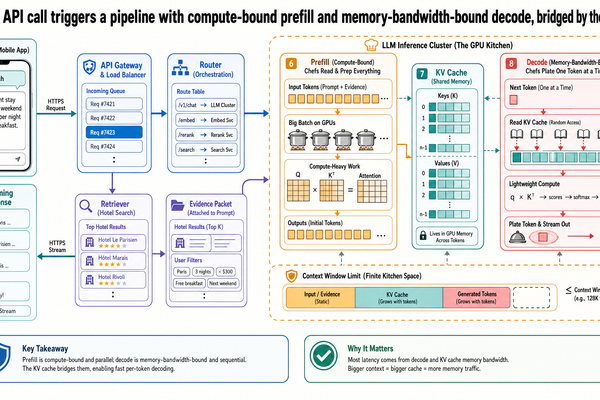
你已經建好一個旅遊小助理。使用者輸入一段查詢,你的應用程式把它送到 LLM 供應商的 API,幾秒後回應串流回來。對應用程式開發者來說,那就是一次函式呼叫。但從基礎設施的角度來看,這一次呼叫觸發了一整條流程(pipeline),牽涉到不同的運算階段、專用的記憶體結構、排程決策,還有硬體限制。這些因素加在一起,決定了使用者實際感受到的延遲、吞吐量和成本。