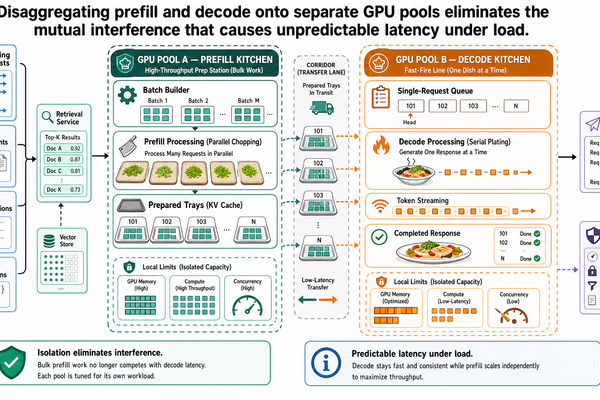
預填充-解碼解耦:將推論的兩個階段分開
I-00 確立了 LLM 推論具有兩個資源特性截然不同的階段。預填充以平行方式處理所有輸入 token,屬於運算瓶頸(compute-bound)——GPU 的運算單元是限制因素。解碼則逐一生成 token,屬於記憶體頻寬瓶頸(memory-bandwidth-bound)——限制因素在於從 GPU 記憶體讀取模型權重和 KV 快取的速度。I-01 介紹了連續批次處理,它透過在迭代層級而非批次層級進行排程,讓 GPU 保持滿載。I-02 則展示了 PagedAttention 如何消除記憶體浪費,讓更多請求能同時處於活躍狀態。
Huang Tzu Lin