預填充-解碼解耦:將推論的兩個階段分開
閱讀順序
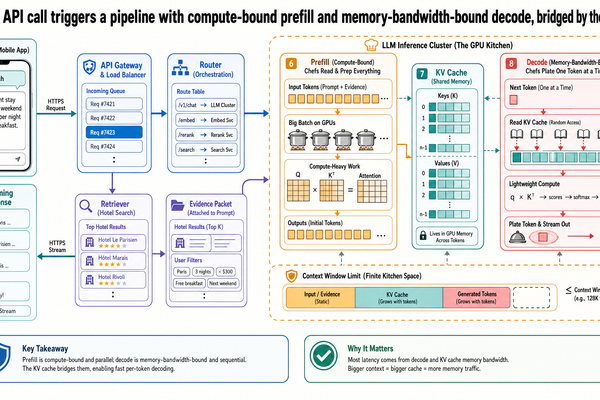
LLM Inference Infrastructure
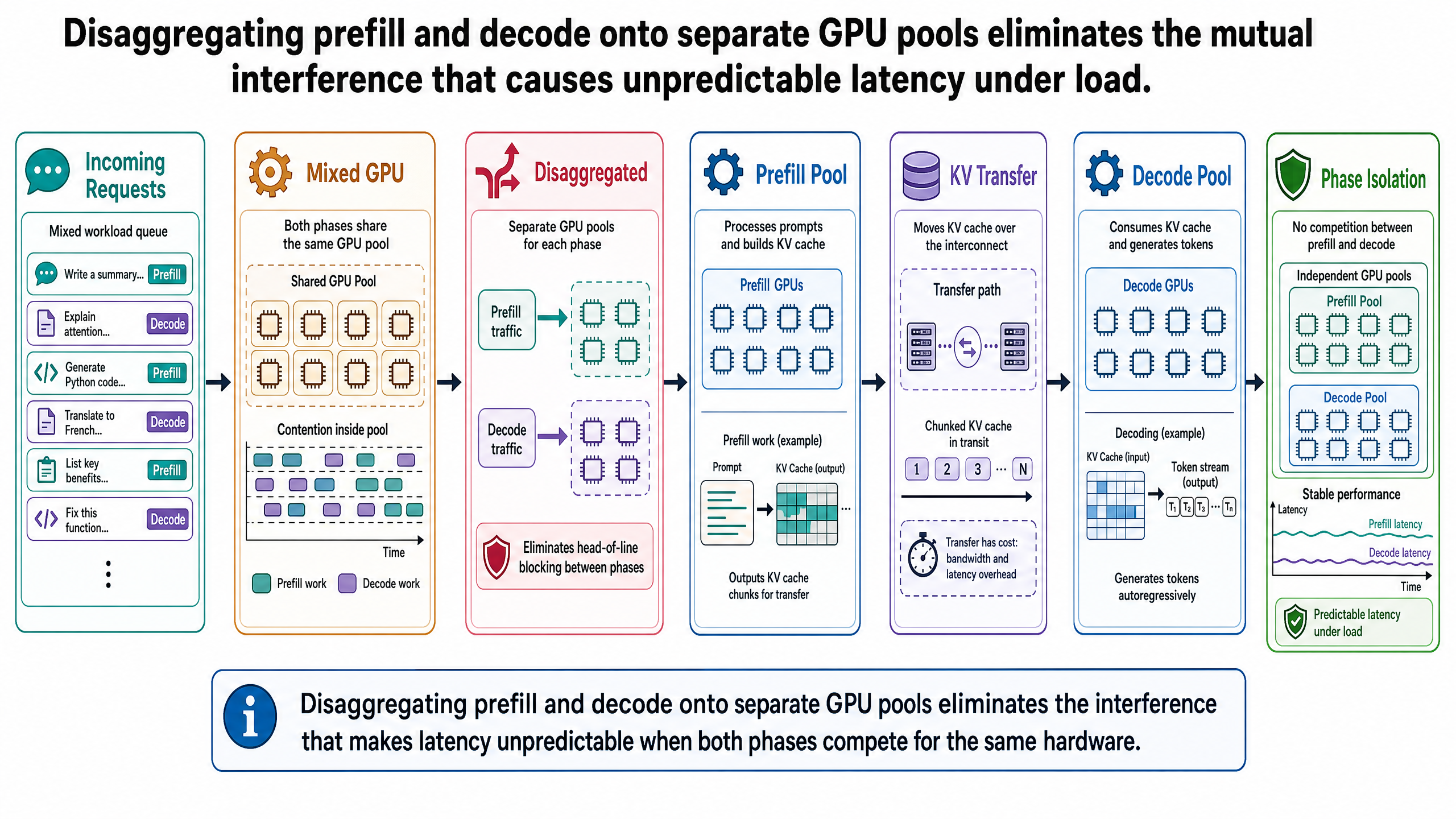
I-00 確立了 LLM 推論具有兩個資源特性截然不同的階段。預填充以平行方式處理所有輸入 token,屬於運算瓶頸(compute-bound)——GPU 的運算單元是限制因素。解碼則逐一生成 token,屬於記憶體頻寬瓶頸(memory-bandwidth-bound)——限制因素在於從 GPU 記憶體讀取模型權重和 KV 快取的速度。I-01 介紹了連續批次處理,它透過在迭代層級而非批次層級進行排程,讓 GPU 保持滿載。I-02 則展示了 PagedAttention 如何消除記憶體浪費,讓更多請求能同時處於活躍狀態。
這些優化加在一起確實提升了 GPU 使用率,但同時也帶來了一個新問題。連續批次處理讓批次保持滿載,意味著新到達請求的預填充操作會與活躍請求的解碼操作同時運行——在同一張 GPU 上,搶同樣的資源。這兩個階段的瓶頸恰好相反,硬要它們共用同一套硬體,結果就是兩邊都跑不到最佳狀態。這種干擾(interference)就是這篇要談的重點。
兩個特性不同的階段
先快速回顧一下這兩個階段,因為後面的討論都建立在這個基礎上。
當一個請求到達時,模型在預填充期間以單次前向傳播處理所有輸入 token。這是運算瓶頸階段。GPU 手上有充足的資料——所有輸入 token 都已就緒——但運算單元必須完成注意力和模型各層所需的矩陣乘法。套用 I-00 的廚房類比:儲藏室裡食材堆得滿滿的,瓶頸在於廚師切菜和擺盤的速度。
預填充把 KV 快取填滿之後,模型就進入解碼階段。每一步生成一個 token,但每一步都必須從 GPU 記憶體讀取完整的模型權重和不斷增長的 KV 快取,才能完成計算。運算單元很快就算完了;真正的瓶頸在於資料從記憶體載入的速度。廚師閒著沒事做,在等人從儲藏室把食材一樣一樣搬過來。
這不只是兩種碰巧不同的工作負載——而是資源需求完全相反的工作負載。預填充需要運算吞吐量,解碼需要記憶體頻寬。針對其中一個優化的 GPU 配置,對另一個來說都不是最佳選擇。然而在使用連續批次處理的標準推論引擎中,兩個階段就是在同一時間、同一硬體上運行。
干擾問題
連續批次處理大幅提升了 GPU 使用率,但同時也讓預填充-解碼共同排程(co-scheduling)變得更加頻繁。每當一個新請求進入批次,它的預填充就會和批次中所有其他活躍請求的解碼同時運行。在短提示、低並行度的情況下,這種干擾幾乎感覺不到。但在長提示、高並行度的情況下,它就成了延遲變異的主要來源。
干擾是雙向的。當一個運算密集的預填充在執行時,它會佔滿 GPU 的運算單元,拖慢所有共同排程請求中記憶體頻寬瓶頸的解碼迭代。那些解碼請求會經歷 ITL 突波——串流回應會明顯卡頓。反過來,解碼操作對記憶體頻寬的需求也會拖慢預填充。兩個階段互相拖累。
這導致 TTFT 和 ITL 之間產生耦合,讓系統從根本上變得難以調校。優先處理預填充來壓低 TTFT,活躍的解碼就會停滯;抑制預填充來保護解碼,新請求就要等更久才能拿到第一個 token。排程器沒辦法同時對兩個指標做優化,因為問題的根源在物理層面:兩種資源需求相反的工作負載在爭奪同一套硬體。
DistServe(Zhong et al., OSDI 2024)——首篇將解耦(disaggregation)具體化為系統架構的論文——將這個現象描述為「強烈的預填充-解碼干擾」(strong prefill-decoding interferences),指出這種干擾「迫使兩個階段必須綁定相同的資源分配與平行化策略」。Splitwise(Patel et al., ISCA 2024)則從硬體效率的角度獨立得出相同結論。兩邊切入的角度不同,但觀察到的問題一樣:「生成式 LLM 推論的每個階段具有不同的延遲、吞吐量、記憶體和功耗特性」,把它們擠在一起只會迫使兩者都妥協,結果兩邊都服務不好。
混合運行時會發生什麼事
回到那 50 位並行旅遊代理人的範例。訂房旺季,查詢持續湧入。大多數是例行查詢:600 到 1,000 個輸入 token,生成 100 到 200 個輸出 token。在連續批次處理下,系統處理得很順。ITL 穩定在大約 25 毫秒,回應串流很順暢。
接著,一位資深旅遊代理人提交了一筆複雜的多段行程查詢。小助理的系統提示(200 個 token)、檢索到的飯店資料庫上下文(1,200 個 token)、鐵路通票時刻表(400 個 token),加上詳細的使用者查詢(200 個 token),總計約 2,000 個輸入 token——大約是平均的兩倍。
在一張跑連續批次處理的混合 GPU 上,情況會是這樣:
這筆 2,000 個 token 的查詢與其他代理人的 7 個活躍解碼請求一起進入批次。
預填充開始。GPU 的運算單元被佔滿,正在處理 2,000 個 token 通過所有注意力層。這次預填充大約需要 80 毫秒的運算密集處理。
在這 80 毫秒內,7 個解碼請求無法正常取得記憶體頻寬瓶頸的迭代服務。它們的 ITL 從穩定的 25 毫秒飆升到 90 毫秒以上。那些代理人正在看的串流回應明顯卡頓。有兩位代理人碰到超過 200 毫秒的輸出間隙——長到使用者明顯感受到停頓,甚至懷疑系統是不是當掉了。
長預填充完成後,新請求開始解碼,所有人的 ITL 回落到 25 毫秒,系統隨即恢復正常。
但這種影響會不斷累積。在持續負載下,長預填充每隔幾秒就會冒出來一次,每次都造成相同的干擾模式。TTFT 和 ITL 變得不可預測。系統確實達到了總體吞吐量目標——請求持續在消化——但有 30% 到 40% 的請求違反延遲 SLO。
這就是隊首阻塞(head-of-line blocking):一個請求的長預填充拖延了同一張 GPU 上所有其他活躍請求的解碼迭代。這個術語借自網路領域,指的是佇列前端的一個大封包延遲了後面每一個封包。類比非常精確——長預填充就是那個大封包;共同排程的解碼就是被卡住等待的所有後續封包。
問題不在於系統整體速度慢,而在於它不可預測。每當一位使用者提交一個長提示,其他七位使用者就會感受到服務品質下降。監控儀表板上的吞吐量數字看起來很健康;使用者的實際體驗卻完全是另一回事。
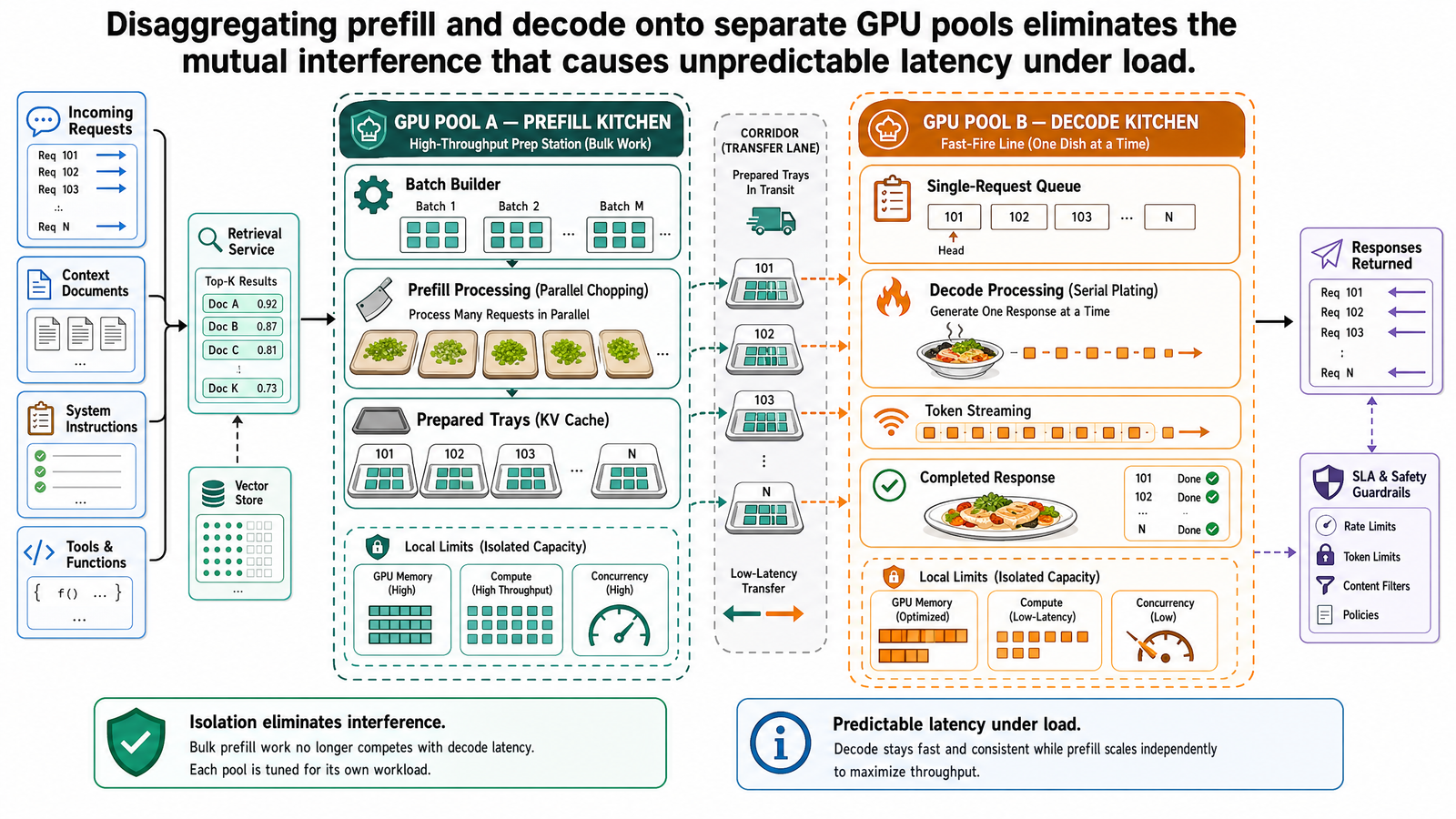
解耦:獨立的資源池
解法就是物理上的分離。把預填充和解碼分配到不同的 GPU 資源池,每個資源池針對該階段的資源特性做配置。
預填充池負責處理輸入。它的 GPU 被配置為追求運算吞吐量——高度平行化,針對數千個輸入 token 上注意力所需的大型矩陣操作做優化。預填充池不需要為大量並行解碼串流維護長期的 KV 快取。它的任務就是處理輸入、計算 KV 快取,然後交給解碼池。
解碼池負責 token 生成。它的 GPU 被配置為追求記憶體頻寬效率——針對反覆載入模型權重和 KV 快取、產生一個 token、再載入一次的循環模式做優化。解碼池不需要處理運算密集的預填充突發,它的工作負載穩定且可預測。
架構的運作方式如下:當一個請求到達時,排程器將它路由到預填充池。一張預填充 GPU 處理所有輸入 token 並計算 KV 快取。預填充完成後,KV 快取被序列化並透過網路傳輸到解碼 GPU,解碼在解碼 GPU 上開始,回應串流回使用者。
結果就是階段隔離(phase isolation):每個階段各自運行,不會影響另一個階段的效能。那筆 2,000 個 token 的行程查詢的預填充在一張預填充 GPU 上跑。解碼池上的 7 位正在解碼的代理人完全不受干擾,ITL 全程維持在 25 毫秒。沒有卡頓,沒有干擾,沒有不可預測的延遲突波。
獨立擴充是第二個結構性優勢。在共置系統中,多加一張 GPU 就是同時為預填充和解碼增加等量容量——不管工作負載實際上需不需要。有了解耦的資源池,比例可以按工作負載來調配。提示密集的工作負載(長輸入、短輸出)需要更多預填充 GPU;生成密集的工作負載(短輸入、長輸出)需要更多解碼 GPU。Splitwise 進一步提出使用不同等級的硬體:最新世代的 GPU 用於運算瓶頸的預填充池,較便宜的硬體用於記憶體頻寬瓶頸的解碼池,有望在維持甚至提升吞吐量的同時降低成本。
這已經不只是學術研究層面的概念了。到 2025-2026 年,預填充-解碼解耦已經進入面向正式環境的推論堆疊。NVIDIA Dynamo 將解耦服務列為一等設計,vLLM 也提供具備多種 KV 傳輸後端的解耦預填充能力。這不代表每個部署都應該使用解耦,也不代表每個框架的實作方式相同;它代表這個模式已經從論文架構走向可被正式團隊依照工作負載、互連品質與延遲 SLO 評估的實務選項。
KV 快取傳輸:代價
解耦並非沒有代價。它引入了共置系統所沒有的一個步驟:預填充完成後,KV 快取必須被序列化,從預填充 GPU 透過網路連線傳送到解碼 GPU。
這次傳輸有具體的大小。回想 I-02 提到的,KV 快取為每個輸入 token 在模型的每一層儲存 key 和 value 向量。每個 token 的 KV 快取記憶體用量可以用以下公式估算:2(key 和 value)乘以層數、KV head 數、head 維度,以及精度的位元組數。以一個 700 億參數的模型(例如 Llama 2 70B)為例,處理 2,000 個輸入 token、使用 FP16 精度時,KV 快取大約是 1.25 GB。而這只是單一請求的快取大小。
傳輸速度夠不夠快,完全取決於互連(interconnect)的品質。在同一節點內使用高速 NVLink 時,傳輸延遲幾乎可以忽略不計。DistServe 報告,當預填充和解碼 GPU 位於同一節點內、使用節點內 NCCL 頻寬時,KV 快取傳輸開銷不到總服務時間的 0.1%。在這個水準下,傳輸成本微乎其微,基本上可以忽略。
但並非所有部署都在同一節點上。在較慢的跨節點連結上,情況就不一樣了。Splitwise 算過,OPT-66B 上一筆 512 個 token 的請求會產生約 1.13 GB 的 KV 快取。在每秒 10 個請求的速率下,要撐住這個傳輸率需要大約 90 Gbps 的頻寬才不會變成瓶頸。如果可用頻寬更低,KV 快取傳輸本身就會成為瓶頸,反而是在增加延遲而非消除延遲。
研究社群已經發展出緩解策略。Splitwise 透過在預填充計算期間觸發非同步的逐層傳輸,讓 KV 快取傳輸與預填充計算重疊進行:一旦某一層的 KV 向量在預填充期間算完,就立刻開始傳送到解碼 GPU,同時下一層繼續計算。如此一來,大部分傳輸延遲就被藏在本來就在進行的計算背後了。vLLM 支援多種傳輸後端——NCCL、NixL 和 Mooncake——各自針對不同的網路拓撲做了優化。
坦白說,在連線良好的節點內,KV 快取傳輸的成本低到可以忽略。但在頻寬有限的跨節點環境中,或在非常高的請求速率下,它是一個需要實際量測、不能想當然耳的真實限制。
有效吞吐量:真正重要的指標
這裡值得介紹一個指標,它準確反映了解耦到底在優化什麼。
原始吞吐量——每秒處理的請求數——無法反映使用者的實際體驗品質。一個每秒處理 100 個請求但有 40% 違反 TTFT 目標的系統,稱不上是在提供良好的服務。監控儀表板顯示吞吐量健康,使用者看到的卻是卡頓、延遲和不可預測的回應時間。
DistServe 引入了有效吞吐量(goodput)來處理這個落差。有效吞吐量是在目標百分比的請求——例如 90%——同時滿足 TTFT 和 TPOT(每個輸出 token 的時間,等同於 ITL)SLO 的條件下,系統所能維持的最大請求速率。它衡量的是吞吐量與延遲品質的交集,只有滿足延遲目標的請求才被計入。
有效吞吐量正是讓解耦的價值變得具體可見的指標。一個共置系統和一個解耦系統可能有相似的原始吞吐量,但如果共置系統因為預填充-解碼干擾而有三分之一的請求違反延遲 SLO,它的有效吞吐量就會低很多。解耦透過消除導致違規的干擾來提升有效吞吐量——即使原始請求速率不變。
從這個角度來看,研究成果相當亮眼。DistServe 在各種 LLM 和延遲要求下,相較於最先進的共置系統,達到了最高 7.4 倍的有效吞吐量,或者能以 12.6 倍更嚴格的 SLO 界限服務相同的請求速率。這裡的「或者」很重要:這是衡量改善的兩種方式,不是同時達成的結果。Splitwise 從硬體效率的角度切入,報告了最高 1.4 倍的吞吐量提升同時降低 20% 成本,或者在相同的功耗和成本預算下達到 2.35 倍的吞吐量。兩組數字都經過驗證,但都需要搭配各自的基準線和測量條件一起解讀。
實際範例:50 個小助理查詢,混合 vs. 解耦
回到具體場景。同一筆 2,000 個 token 的行程查詢,同樣 50 位並行代理人,同樣的硬體。唯一的差異是服務架構。
混合資源池
那筆 2,000 個 token 的查詢與 7 個活躍解碼請求一起進入批次。預填充跑了約 80 毫秒,期間 7 個解碼請求的 ITL 從 25 毫秒飆升到 90 毫秒以上。排在長預填充後面的短查詢也碰到了偏高的 TTFT。在持續負載下,偶爾出現長提示時:
P90 TTFT:320 毫秒
P90 ITL:85 毫秒
在目標 SLO(TTFT < 200 毫秒、TPOT < 50 毫秒)下的有效吞吐量:每秒 12 個請求
系統確實在處理請求,只是有很大一部分違反了延遲目標。
解耦資源池
那筆 2,000 個 token 的查詢被路由到預填充池。一張預填充 GPU 在約 80 毫秒內處理所有 2,000 個 token——運算成本相同。產生的 KV 快取(對這個 700 億參數等級的模型約 1.25 GB)透過節點內 NVLink 在大約 5 毫秒內傳到解碼池。解碼在一張解碼優化的 GPU 上開始。
與此同時,解碼池上的 7 位代理人全程不受干擾。他們的 ITL 維持在穩定的 25 毫秒。沒有卡頓,沒有突波,沒有干擾。
P90 TTFT:130 毫秒
P90 ITL:28 毫秒
在相同 SLO 下的有效吞吐量:每秒 45 個請求
有效吞吐量提升了 3.75 倍——不是因為硬體更快,而是因為系統不再把延遲預算浪費在干擾上。資深代理人的 TTFT 約 85 毫秒(80 毫秒預填充加 5 毫秒傳輸),而另外 7 位代理人根本不會注意到那次長預填充曾經發生過。
何時該解耦(何時不該)
解耦不是在所有情況下都更好。它增加了基礎設施的複雜度——兩個資源池、一套傳輸機制、一層路由,以及一套協調協定。它也增加了總 GPU 記憶體消耗,因為兩個資源池都必須持有完整的模型權重。它在預填充和解碼之間多了一個共置系統不需要的網路跳躍。只有當工作負載的干擾嚴重到足以抵消這些成本時,解耦才值得導入。
解耦有幫助的情境:
工作負載並行度高,且提示長度參差不齊,長預填充頻繁干擾活躍的解碼。應用程式有嚴格的延遲 SLO,P90 或 P99 目標不容妥協——面向客戶的串流應用、AI 小助理、即時助手。叢集擁有充足的 GPU 間頻寬(高速 NVLink 或同等級),讓 KV 快取傳輸成本夠低。提示與輸出的比例變化夠大,獨立的資源池擴充能帶來實質的成本節約。
解耦沒有幫助的情境:
並行度低,干擾本來就少見。如果系統只處理 5 到 10 個並行請求,長預填充撞上活躍解碼的機率本來就低,即使發生了,干擾也很短暫。短提示主導的工作負載——如果預填充每個請求只需 5 毫秒,干擾窗口太小,不會造成明顯的 ITL 突波,用連續批次處理的共置系統就能妥善應對。GPU 間頻寬不足——如果 KV 快取傳輸本身成為瓶頸,解耦反而是在增加延遲。應用程式沒有差異化的延遲需求——批次處理工作負載(離線摘要、大量萃取、資料集生成)在乎的是總體吞吐量,而非 P90 TTFT。當沒有使用者在即時等待串流輸出時,解耦在有效吞吐量上的優勢就不那麼關鍵了。
BentoML 的 LLM Inference Handbook 就明確提醒:如果工作負載太小或 GPU 設定沒有針對解耦做調校,效能可能反而下降 20% 到 30%。KV 快取傳輸的開銷加上維護兩個資源池的基礎設施複雜度,在干擾本身不是大問題時,成本可能超過收益。
一個具體的反例可以說明這一點。假設 10 位代理人在低並行度下提交短查詢——每筆 300 個 token。預填充每筆大約需要 5 毫秒,根本不足以對共同排程的解碼造成明顯干擾。這時解耦每筆請求反而會多出約 2 毫秒的傳輸開銷,卻幾乎沒有收益。在這種情況下,用連續批次處理的共置系統更簡單、更便宜,效果也一樣好。
正確的思考框架不是「解耦比較好」,而是「解耦用基礎設施複雜度換延遲可預測性」。這筆交易值不值得,取決於工作負載、硬體和 SLO。DistServe 的原始論文說得很清楚:解耦可以帶來大幅更好的效能,或者大幅更可預測的效能。這裡的「或者」很重要——不是每次都能同時達成。
本文不涵蓋的內容
這篇說明了預填充-解碼干擾為何發生、解耦如何透過物理分離兩個階段來消除干擾、KV 快取傳輸的代價是什麼,以及何時這筆取捨是划算的。我們也帶入了有效吞吐量這個指標,用來衡量解耦真正在優化的東西——在延遲限制下的服務品質,而不只是原始請求吞吐量。
本文沒有涵蓋如何在特定引擎中實作解耦。vLLM、SGLang、NVIDIA Dynamo 和 Ray Serve 各有自己的配置、傳輸後端和路由策略,那些屬於實作細節,不是架構概念。
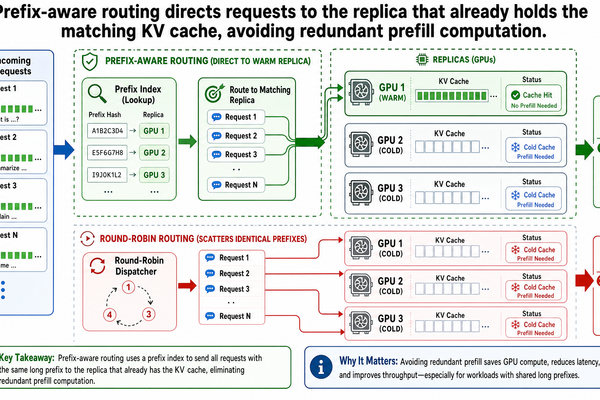
本文也沒有涵蓋前綴感知路由(prefix-aware routing)。有了解耦的資源池,接下來還有一個機會:如果排程器能把請求路由到已經快取了其前綴的解碼 GPU 呢?假如兩筆連續的請求共享相同的系統提示,而第二筆送到了不同的解碼 GPU,那段共享前綴的 KV 快取就得重新預填充或重新傳輸。把請求路由到已持有該前綴快取的副本,就能避免這種浪費。這是 I-04 的主題。
本文同樣沒有涵蓋解耦如何與混合專家(mixture-of-experts)架構互動——在這種架構中,每次推論只會啟用部分專家,分片策略為資源池設計增加了另一個維度。這是 I-05 的主題。
解耦決定了哪個資源池處理每個階段。下一個問題是:資源池中的哪一張特定 GPU 接收請求——而這個決定取決於那裡已經快取了什麼。這就是我們接下來要探討的方向。
來源附註
本文取材自以下原始論文與實務來源:
Zhong, Y., Liu, S., Chen, J., Hu, J., Zhu, Y., Liu, X., Jin, X., and Zhang, H. "DistServe: Disaggregating Prefill and Decoding for Goodput-optimized Large Language Model Serving." OSDI, 2024. 解耦架構、有效吞吐量指標、干擾特徵描述、7.4 倍有效吞吐量 / 12.6 倍更嚴格 SLO 的結果(相較於最先進的共置系統),以及 KV 快取傳輸開銷測量(節點內 NCCL < 0.1%)的主要來源。arxiv.org/abs/2401.09670
Patel, P., Choukse, E., Zhang, C., Shah, A., Goiri, I., Maleki, S., and Bianchini, R. "Splitwise: Efficient Generative LLM Inference Using Phase Splitting." ISCA, 2024. 從硬體角度描述階段特徵、逐層 KV 快取傳輸(與預填充計算非同步重疊)、解耦資源池的異質硬體、1.4 倍吞吐量 / 降低 20% 成本的結果,以及具體的 KV 快取大小計算(512 token OPT-66B 請求需要 1.13 GB,在每秒 10 個請求下需要 90 Gbps)的主要來源。arxiv.org/abs/2311.18677
NVIDIA. "Mastering LLM Techniques: Inference Optimization." NVIDIA Developer Blog. 預填充和解碼階段的運算瓶頸 vs. 記憶體頻寬瓶頸特徵描述的參考資料。developer.nvidia.com/blog/mastering-llm-techniques-inference-optimization
NVIDIA. "Introducing NVIDIA Dynamo: A Low-Latency Distributed Inference Framework for Scaling Reasoning AI Models." NVIDIA Developer Blog. Dynamo 在生產環境中支援解耦的參考資料,於 GTC 2025 發布。developer.nvidia.com/blog/introducing-nvidia-dynamo-a-low-latency-distributed-inference-framework-for-scaling-reasoning-ai-models
vLLM. "Disaggregated Prefilling." vLLM Documentation. vLLM 生產環境解耦實作、傳輸後端(NixlConnector、P2pNcclConnector、MooncakeConnector),以及「相較於分塊預填充,解耦預填充是控制尾部 ITL 更可靠的方式」(a much more reliable way to control tail ITL compared to chunked prefill)觀察的參考資料。docs.vllm.ai/en/latest/features/disagg_prefill
BentoML. "Prefill-decode disaggregation." LLM Inference Handbook. 經實務驗證的警告:當解耦被應用於不適當的工作負載(低並行度、GPU 調校不足)時,效能可能下降 20-30%。bentoml.com/llm/inference-optimization/prefill-decode-disaggregation
Raschka, S. "Understanding and Coding the KV Cache in LLMs from Scratch." June 2025. 傳輸開銷計算中使用的 KV 快取記憶體大小計算公式的參考資料。magazine.sebastianraschka.com/p/coding-the-kv-cache-in-llms
Huang Tzu Lin
With over five years in autonomous robotics, there's a strong passion for incorporating cutting-edge technologies and innovative approaches. Dedicated to transforming the latest research and insights into practical applications, this journey pushes the limits of possibility.
相關文章
訂閱最新資訊
將最新技術洞察直接送到您的信箱。