連續批次處理:用一張 GPU 服務大量請求
閱讀順序
LLM Inference Infrastructure
I-00 追蹤了單一請求通過推論流程的完整路徑:預填充(prefill)以平行方式處理所有輸入 token,解碼(decode)逐一生成輸出 token,而 KV 快取(key-value cache)隨著每一步不斷增長。在那篇文章的結尾,我們注意到還有 49 個其他代理人幾乎同時提交了查詢。這個觀察不是隨口帶過——它直接指向推論服務的核心運作問題。
當一個請求佔用 GPU 時,硬體確實在做有用的工作,但做的量遠遠不夠。單一解碼步驟只處理一個新 token,卻必須從 GPU 記憶體載入整個模型的權重才能完成計算。運算單元很快就算完了,然後就在那邊等下一輪權重載入。GPU 大部分時間其實都花在搬資料,不是在算東西。這就是 I-00 提到的記憶體頻寬瓶頸——對單一請求來說,GPU 的運算能力被嚴重浪費了。
解法是批次處理(batching):同時處理多個請求,把載入模型權重的成本分攤出去。每個解碼步驟只載入一次權重,但計算會替批次(batch)中的每一個請求執行。如果批次包含 8 個請求,GPU 就以大致相同的記憶體傳輸成本完成 8 倍的有用工作。
批次處理就是推論引擎(inference engine)把低度利用的 GPU 變成高效 GPU 的方式。但 LLM 生成有可變長度的特性——正是這個特性讓推論在本質上有別於影像分類或推薦系統——這代表天真的批次處理會引入另一種浪費。如何消除這種浪費,就是本文的主題。
為什麼批次處理對 GPU 使用率至關重要
先想像批次處理的反面:逐一處理。GPU 一次處理一個請求。它先預填充請求 A,解碼 A 的所有輸出 token,釋放 KV 快取,然後才處理請求 B。如果 50 位旅遊代理人同時提交查詢,他們就得排隊。第 50 個請求要等前面 49 個請求各自跑完才能開始。
問題不只是排隊延遲,更關鍵的是硬體浪費。每個解碼步驟中,GPU 得從記憶體載入完整的模型權重,卻只用到算術容量的一小部分。一張 A100 GPU 每秒可以執行大約 312 兆次浮點運算,但單一請求的一個解碼步驟可能只需要幾十億次運算。剩下的運算能力全部閒置——GPU 就只是在等下一次記憶體傳輸。
批次處理的做法是把多個請求合併到同一個解碼步驟。模型權重只載入一次,GPU 同時替批次中的每個請求計算下一個 token。批次裡有 8 個請求,就代表每次權重載入能完成 8 倍的有用運算。原本在單一請求解碼期間幾乎閒置的算術單元,現在終於派上用場了。
可以用餐廳的烤架來比喻。一個一次只烤一塊牛排的廚師,會加熱整個烤架表面,卻只用到其中一小部分。從閒置表面散失的熱量完全是浪費。一個把烤架擺滿的廚師,用同樣的能源成本就能服務更多客人。批次處理就是把烤架擺滿。
不過有個問題。烤架上的牛排大小差不多,烤的時間也差不多。但 LLM 的請求可不是這樣。
天真批次處理及其浪費
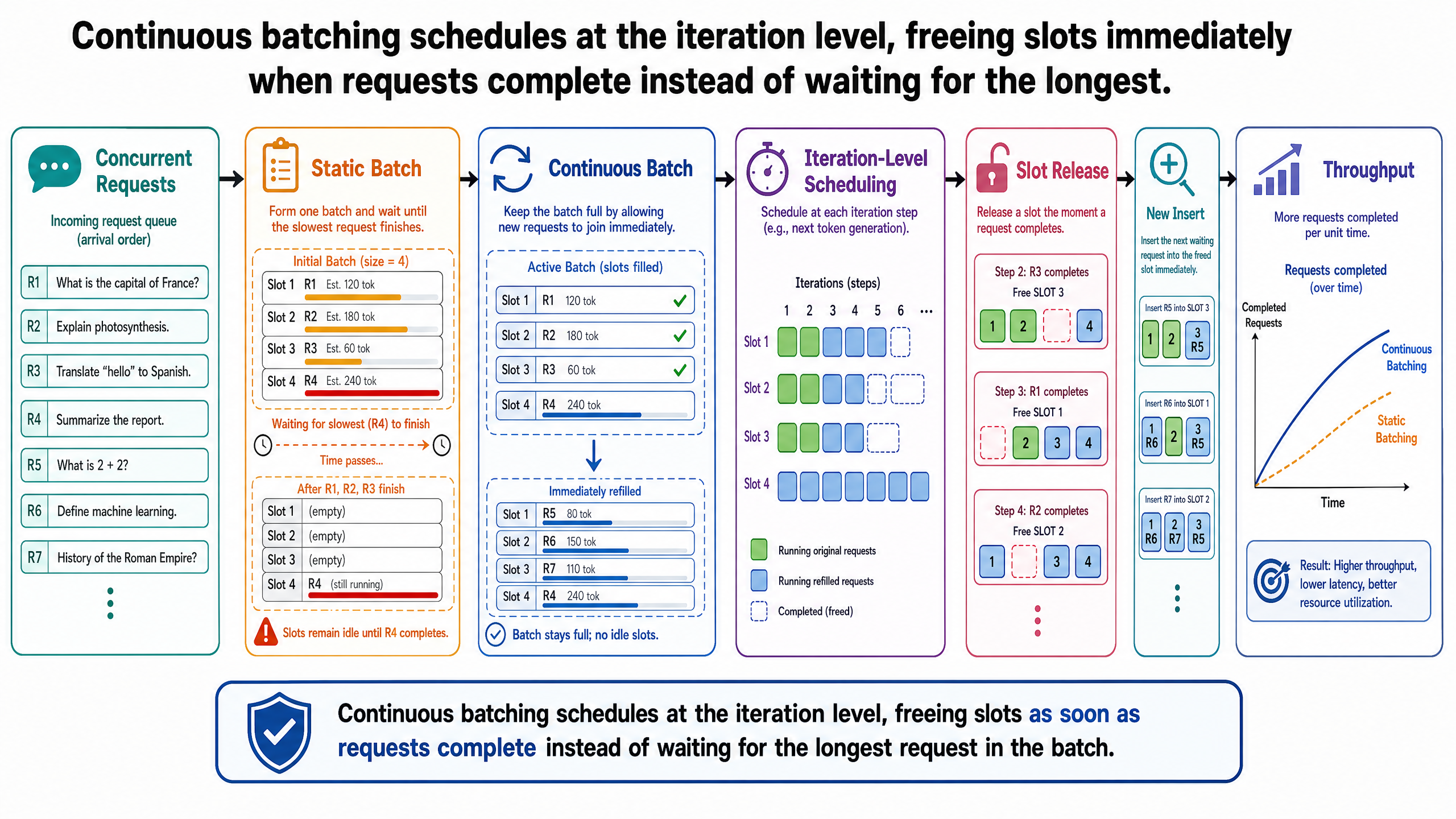
最簡單的批次處理策略——有時稱為靜態批次處理(static batching)——做法是這樣的:收集固定數量的請求,將所有輸入序列填充(padding)到最長序列的長度,然後處理整個批次直到每個請求都生成完畢。
以 50 位旅遊代理人中的 8 位幾乎同時提交查詢為例:
請求 — 輸入 token 數 — 輸出 token 數
A — 800 — 20
B — 1,200 — 45
C — 950 — 80
D — 1,100 — 120
E — 750 — 150
F — 1,050 — 90
G — 900 — 60
H — 1,300 — 200
在靜態批次處理下,8 個請求全部進入批次。預填充為每個請求執行,填入各自的 KV 快取。接著解碼開始:每一輪迭代中,GPU 同步地為 8 個請求各生成一個 token。
到了解碼迭代 20,請求 A 發出了結束序列 token。它的回應已經完成——20 個 token,就這樣。但批次不會釋放 A 的位置。批次繼續跑,A 的位置被填充佔據:虛假的計算不產生任何有用的輸出。GPU 在每個後續迭代中繼續處理 A 的填充 token,把運算週期浪費在毫無意義的計算上。
到了迭代 45,請求 B 結束。又一個位置變成填充。迭代 60,請求 G 結束。然後是 C 在 80、F 在 90、D 在 120、E 在 150。每當一個請求完成,它的位置就變成浪費,但批次照樣繼續跑。
批次要到迭代 200 才結束——也就是請求 H,最長的那個,終於發出停止 token 的時候。
浪費一目了然。請求 A 佔了一個批次位置 200 個迭代,但它只需要 20 個。也就是說,200 個迭代裡有 180 個——90%——都是填充。綜觀全部 8 個請求,平均每個請求需要大約 96 個輸出 token,但每個都被留在批次裡整整 200 個迭代。大約 52% 的 GPU 解碼總運算花在對任何回應都毫無貢獻的填充 token 上。
與此同時,請求 9 到 16——排在佇列中的其他代理人——得等整個 200 迭代的批次跑完才能開始。他們的佇列等待時間不取決於自身回應的長度,而取決於請求 H 碰巧需要多長的生成時間。
這就是靜態批次處理的根本低效之處。它把批次視為一個原子性的單位:在最長的請求結束之前,不接納新請求、也不釋放已完成的請求。當輸出長度差異很大時——這在 LLM 生成中是常態——既浪費 GPU 運算(填充),也浪費使用者時間(佇列延遲)。
動態批次處理:組批方式更好了,根本問題沒變
動態批次處理(dynamic batching)改進的是批次的組成方式。排程器不再等固定數量的請求到齊,而是根據時間窗口(把過去 50 毫秒內到達的請求湊成一批)或大小觸發條件(一累積到 8 個請求就組批)來形成批次。這樣可以減少請求等待分組的時間。
但動態批次處理不會改變批次形成之後發生的事。一旦批次開始處理,還是整批跑到結束。提前完成的請求照樣佔著被填充的位置,直到最長的請求結束。組批方式是靈活了,但執行方式依然僵化。
對於突發性到達的工作負載,動態批次處理相比靜態批次處理確實是有意義的改進,但它沒有解決核心問題:可變長度的輸出代表可變的完成時間,而批次級排程在請求真正完成和批次最終結束之間,浪費了每一個運算週期。
連續批次處理:迭代級排程
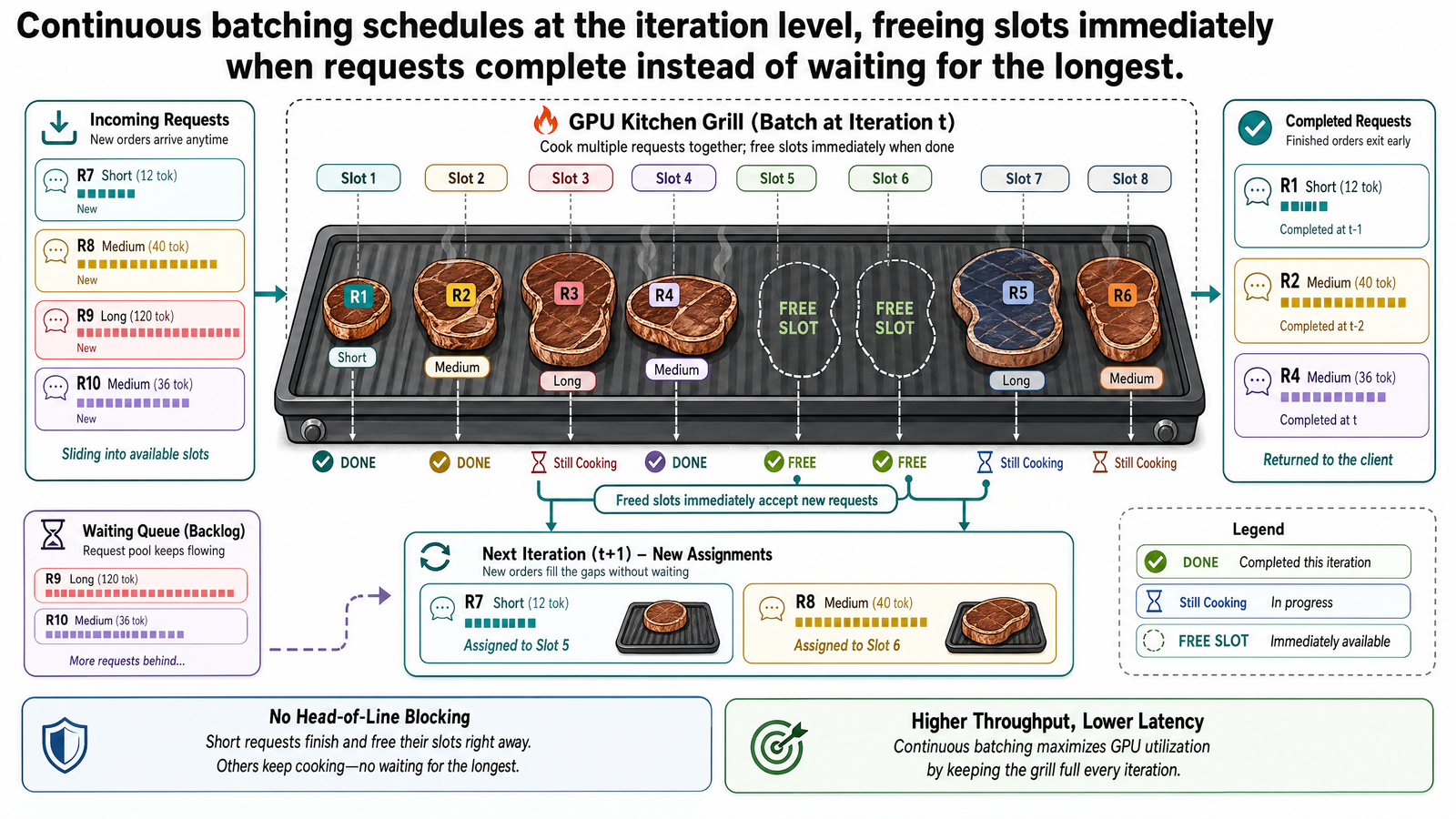
連續批次處理(continuous batching)背後的核心想法其實很簡單:別把批次當成原子性的單位。改成在每一個解碼迭代之後,重新評估批次的組成。
每個解碼步驟結束時,排程器會問兩個問題:
當前批次中有沒有請求剛剛發出了結束序列 token?
佇列中有沒有請求在等待?
如果有請求完成了,它的位置立即釋放。如果有請求在等待,就插入到空出的位置中。新請求在那個位置開始預填充,其餘請求繼續解碼。批次的組成在每一個迭代都可能改變。
這個機制由 Yu et al. 在 Orca 論文(OSDI 2022)中提出,他們稱之為迭代級排程(iteration-level scheduling)——以單一模型前向傳遞的粒度進行排程,而非以完整請求為單位。同一個機制在一般用法中被稱為「連續批次處理」,在 NVIDIA 的 TensorRT-LLM 中則稱為即時批次處理(in-flight batching),因為新請求在其他請求仍在處理中(in-flight)時就開始執行。三個術語講的是同一件事,本文此後統一使用「連續批次處理」。
這裡的關鍵轉變是從批次級排程到迭代級排程。靜態和動態批次處理在批次級進行排程:一個批次開始、運行、結束。連續批次處理在迭代級進行排程:每個解碼步驟都是一次排程決策。
實際運作方式:逐步說明
回到 8 個旅遊代理人的請求。在連續批次處理下,前 20 個迭代跟靜態批次處理看起來一樣:所有 8 個請求都在批次中,同步生成 token。
到了迭代 20,請求 A 完成。在靜態批次處理中,A 的位置會變成填充。但在連續批次處理下,排程器立即把 A 移出批次並檢查佇列。請求 9 正在等待。排程器將請求 9 插入 A 原本的位置。請求 9 開始預填充,請求 B 到 H 則繼續解碼。
到了迭代 45,請求 B 完成。排程器把 B 移出批次,插入請求 10。迭代 60,請求 G 完成,請求 11 進來。這個模式就這樣持續下去:每當一個短請求結束,一個等待中的請求立即遞補。
到了迭代 200,當請求 H 終於結束時,系統處理的已經不只是一個 8 個請求的單一批次。它運作的是一個成員不斷輪替的批次,已經服務了從請求 A 到大約第 20 個請求——甚至更多,取決於後續請求的輸出長度。批次始終保持滿載,沒有任何位置被浪費在填充上。
GPU 使用率的差距非常明顯。靜態批次處理下,GPU 使用率隨著請求陸續完成而下降:到了迭代 100,原始 8 個請求中只剩 4 個還在生成有用的 token,大約一半的批次運算都是填充。到了迭代 180,只剩請求 H 還在跑——使用率已降到批次容量的大約 12%。
在連續批次處理下,批次始終保持滿載。一個位置空出來,一個迭代內就會被填滿。GPU 使用率穩定維持在 90% 以上,因為每個位置都被一個正在積極生成有用輸出的請求佔據。
貫穿範例:8 個小助理查詢
把上述概念對應到具體的吞吐量(throughput)數字上。假設每個解碼迭代需要 25 毫秒(與 I-00 貫穿範例中的 ITL 一致)。
在靜態批次處理下,批次跑了 200 個迭代:200 x 25 毫秒 = 5,000 毫秒。這 5 秒內系統完成了 8 個請求。總輸出為 20 + 45 + 80 + 120 + 150 + 90 + 60 + 200 = 765 個 token,5 秒內完成,系統吞吐量約為每秒 153 個 token。但 GPU 只在大約 45% 的解碼容量中做了有用的工作——其餘都是填充。
在連續批次處理下,同樣的 200 個迭代也需要 5,000 毫秒。但系統產出的不只 765 個 token。隨著請求完成、新請求遞補空位,額外的請求正在被平行處理。如果後續請求具有類似的輸出長度分佈,系統在同樣的 5,000 毫秒窗口內大約能處理 12 到 14 個請求,產出約 1,100 到 1,300 個有用 token。系統吞吐量大約翻了一倍——不是因為 GPU 跑得更快,而是因為它不再把運算週期浪費在填充上。
對於請求 9 到 16(在靜態批次處理下會被排入佇列的那些代理人),改善更加直接。在靜態批次處理下,請求 9 要等整整 5 秒才能開始生成第一個 token。在連續批次處理下,請求 9 在迭代 20 就進入批次——流程開始後僅 500 毫秒。它的首 Token 時間(TTFT)從超過 5 秒降到不到 1 秒。佇列基本上消失了。
那些吞吐量數字到底代表什麼
你可能看過連續批次處理達到「23 倍吞吐量提升」的說法。這個數字是真實的,但需要拆開來看。
23 倍的數字來自 Anyscale 的基準測試(2023 年 6 月),比較的是 vLLM 對上使用 OPT-13B 模型、A100 40 GB GPU 的原生 HuggingFace Transformers 服務。23 倍的提升其實反映的是兩個優化共同作用的結果:連續批次處理(迭代級排程)和 PagedAttention(一種記憶體管理技術,會在 I-02 討論)。而基準線——未經任何優化的 HuggingFace Transformers——本身就是最容易被超越的合理基準。
當同一個基準測試把 vLLM 和 TGI 比較時——TGI 已經實作了連續批次處理但沒有 PagedAttention——提升大約是 2 倍。這 2 倍歸功於 PagedAttention 的記憶體效率,跟批次處理策略本身無關。
同樣地,Orca 論文(Yu et al., OSDI 2022)報告了在 GPT-3 175B 上相對於 NVIDIA FasterTransformer 的 36.9 倍吞吐量。具體來說,要達到 190 毫秒的延遲目標,FasterTransformer 提供 0.185 請求/秒,而 Orca 提供 6.81 請求/秒。這是在分散式服務環境中,拿 1,750 億參數模型做迭代級排程與請求級排程的比較。
兩個數字都有據可查。但兩者都不是在說連續批次處理本身普遍能帶來多少提升。這裡的教訓是永遠要追問:「跟什麼基準線比?用什麼模型?在什麼硬體上?」相對於天真基準線的 23 倍提升,和相對於已有連續批次處理之系統的 2 倍提升,兩者都是真的——但傳達的訊息截然不同。
如今每一個主要推論引擎都實作了連續批次處理:vLLM、TensorRT-LLM、SGLang、TGI。這個技術已經是基本門檻,不再是區分各引擎高下的賣點。研究與工程的最前線已經轉向連續批次處理所暴露出的問題——記憶體管理、階段干擾、快取感知路由——這些是接下來三篇文章的主題。
取捨:吞吐量不是白來的
連續批次處理優化的是系統整體吞吐量,不是個別請求的延遲。這裡有幾個取捨值得了解。
批次大小與個別請求延遲。 每個解碼迭代處理的是整個批次。批次越大,每個迭代需要的計算就越多,花的時間也越長。如果單一請求的解碼步驟需要 20 毫秒,一個包含 32 個請求的批次每步可能要 30 毫秒。個別請求生成 token 的速度變慢了(ITL 變高),但系統每一步產出 32 個 token 而非 1 個。吞吐量大幅提升;個別請求的延遲則會適度增加。
高負載下的佇列壓力。 當請求到達的速度超過 GPU 的處理能力時,批次保持滿載,佇列不斷增長。新到達的請求必須等一個位置空出——而位置只有在當前請求完成時才會空出。在持續高負載下,佇列等待時間可能主導 TTFT。系統必須實作背壓機制(backpressure)——節流或拒絕請求——來維持延遲目標。TensorRT-LLM 透過排程器策略(如 GUARANTEEDNOEVICT)來處理這個問題,這個策略會阻止排程器為了騰出空間給新請求而驅逐做到一半的請求。
批次飽和。 這裡有個天花板。往批次裡放入更多請求確實能提高吞吐量,但前提是 GPU 記憶體還沒用完。批次中每個並行請求都有一份必須常駐在 GPU 記憶體中的 KV 快取。到了某個臨界點,記憶體滿了,不管剩多少運算能力都無法再納入更多請求。這個記憶體天花板正是 I-02 的直接動機:透過高效的 KV 快取管理,在相同的記憶體預算中容納更多併發請求。
預填充與解碼的干擾。 當一個新請求在連續批次處理下進入批次時,它得先跑預填充階段。預填充是運算受限的(compute-bound);解碼是記憶體頻寬受限的(memory-bandwidth-bound)。在同一張 GPU 上同時執行兩者會互相干擾:預填充的運算跟解碼搶 GPU 資源,可能導致正在生成中的請求出現延遲尖峰。這種干擾正是 I-03 的直接動機:把預填充和解碼分離到不同的硬體上。
本文不涵蓋的內容
本文介紹的是讓 GPU 保持滿載的排程機制:連續批次處理用迭代級排程取代批次級排程,消除填充浪費,大幅提升系統吞吐量。
本文沒有談到的是,這些並行請求的 KV 快取要怎麼高效儲存。連續批次處理讓批次保持滿載,也就意味著更多請求同時在跑,也就意味著更多 KV 快取在搶 GPU 記憶體。天真的記憶體分配會因為碎片化(fragmentation)而浪費 60% 到 80% 的可用 KV 快取空間。那些記憶體到底耗到哪裡去了?推論引擎又怎麼在相同的預算內擠進更多請求?那是 I-02 的主題:分頁式 KV 快取管理,把作業系統虛擬記憶體的概念搬過來用。
而當預填充和解碼共用同一張 GPU——正如本文所描述的連續批次處理方案——它們會互相干擾。一個新到達請求的大型預填充可能會拖慢批次中所有其他請求的 token 生成。把兩個階段分離到不同硬體上,是 I-03 的主題。
連續批次處理是基礎。本系列後續的每一項優化,都建立在推論引擎已經在迭代級進行排程這個前提之上。接下來三篇文章要處理的,正是這個基礎所暴露出的問題。
參考資料
本文取材自以下原始論文與實務來源:
Yu, G., Jeong, J. S., Kim, G., Kim, S., and Chun, B. "Orca: A Distributed Serving System for Transformer-Based Generative Models." OSDI, 2022. 提出迭代級排程的論文。本文中 36.9 倍吞吐量數字(GPT-3 175B、FasterTransformer 基準線、190 毫秒延遲目標)出自此論文。usenix.org/conference/osdi22/presentation/yu
Anyscale. "How Continuous Batching Enables 23x Throughput in LLM Inference While Reducing p50 Latency." June 2023. 將「連續批次處理」一詞普及的基準測試。23 倍數字比較的是 vLLM(連續批次處理 + PagedAttention)對上原生 HuggingFace Transformers,使用 OPT-13B / A100 40 GB。anyscale.com/blog/continuous-batching-llm-inference
Anyscale. LLM Continuous Batching Benchmarks(重現程式碼)。github.com/anyscale/llm-continuous-batching-benchmarks
NVIDIA. "Mastering LLM Techniques: Inference Optimization." NVIDIA Developer Blog. GPU 使用率特性與批次處理-使用率關係的參考資料。developer.nvidia.com/blog/mastering-llm-techniques-inference-optimization
NVIDIA TensorRT-LLM documentation. 「即時批次處理」術語與排程器策略(MAXUTILIZATION、GUARANTEEDNO_EVICT)的參考資料。nvidia.github.io/TensorRT-LLM/overview.html
BentoML. "Static, Dynamic and Continuous Batching." LLM Inference Handbook. 三種批次處理策略的實務導向定義。bentoml.com/llm/inference-optimization/static-dynamic-continuous-batching
vLLM documentation. docs.vllm.ai. SGLang project. sgl-project.github.io. 連續批次處理實作的參考,展示該技術在推論引擎間的普遍性。
LMSYS. "SGLang v0.4: Zero-Overhead Batch Scheduler." December 2024. 連續批次處理排程器設計現況的參考資料。lmsys.org/blog/2024-12-04-sglang-v0-4
Huang Tzu Lin
With over five years in autonomous robotics, there's a strong passion for incorporating cutting-edge technologies and innovative approaches. Dedicated to transforming the latest research and insights into practical applications, this journey pushes the limits of possibility.
相關文章
訂閱最新資訊
將最新技術洞察直接送到您的信箱。