分頁式 KV 快取:LLM 推論服務的 GPU 記憶體管理
閱讀順序
LLM Inference Infrastructure
在 I-00 篇中,我們走過了一次 API 呼叫從頭到尾通過推論管線的完整流程,也認識了 KV 快取(key-value cache)——一種用來儲存注意力機制中 key-value 向量的資料結構,讓模型不必在每個解碼步驟重複計算這些向量。KV 快取會隨著每個生成的 token 不斷增長,而且在整個請求期間都必須留在 GPU 記憶體裡。到了 I-01 篇,我們又認識了連續批次處理(continuous batching):它在迭代層級進行排程,不再傻等批次中最慢的請求跑完,因此能讓更多請求同時保持運作。
把這兩件事放在一起看,問題就很具體了。想像你有 50 位旅遊顧問在旺季同時使用 OptiVerse 小助理。每位顧問的請求正一個 token 接一個 token 地生成,KV 快取也跟著一步步膨脹。連續批次處理代表許多請求同時處於活躍狀態,而 GPU 的記憶體就這麼大,得同時塞下所有請求。
問題不在於該不該快取——I-00 篇已經講過,KV 快取不是可有可無的東西。真正的問題在於怎麼管理快取所需的記憶體。管理不好的話,一張 80 GB 記憶體的 GPU 可能只撐得住 8-12 個並行請求;管理得好的話,同一張 GPU 能服務 40-50 個。
記憶體問題
模型權重雖然很大,但它們是固定的。一旦載入 GPU,服務期間就不會變動。KV 快取不一樣——它是動態的:從空的開始、隨著每個 token 增長、每個請求的大小都不同,而且得在請求進來時分配、結束後釋放。
正是這種動態特性,讓 KV 快取成了推論期間 GPU 記憶體中最大的變動消耗來源。舉個例子:一個典型的 70 億參數模型,用半精度(FP16)服務的話,模型權重大約佔 14 GB。而單一請求的 KV 快取就可能吃掉數百 MB,而且隨序列長度線性增長。50 個請求一起跑,KV 快取的總量輕輕鬆鬆就超過模型本身的大小了。
更棘手的是不可預測性。請求進來的時候,推論引擎知道輸入有多長,卻不知道輸出要跑多長。一個飯店空房查詢可能只生成 100 個 token,也可能生成 500 個——取決於有多少間飯店符合條件。引擎必須在不知道輸出長度的情況下,替 KV 快取分配記憶體。
於是就出現了一個分配決策的難題,而 2023 年以前的系統在這方面處理得相當粗糙。
舊系統怎麼浪費記憶體
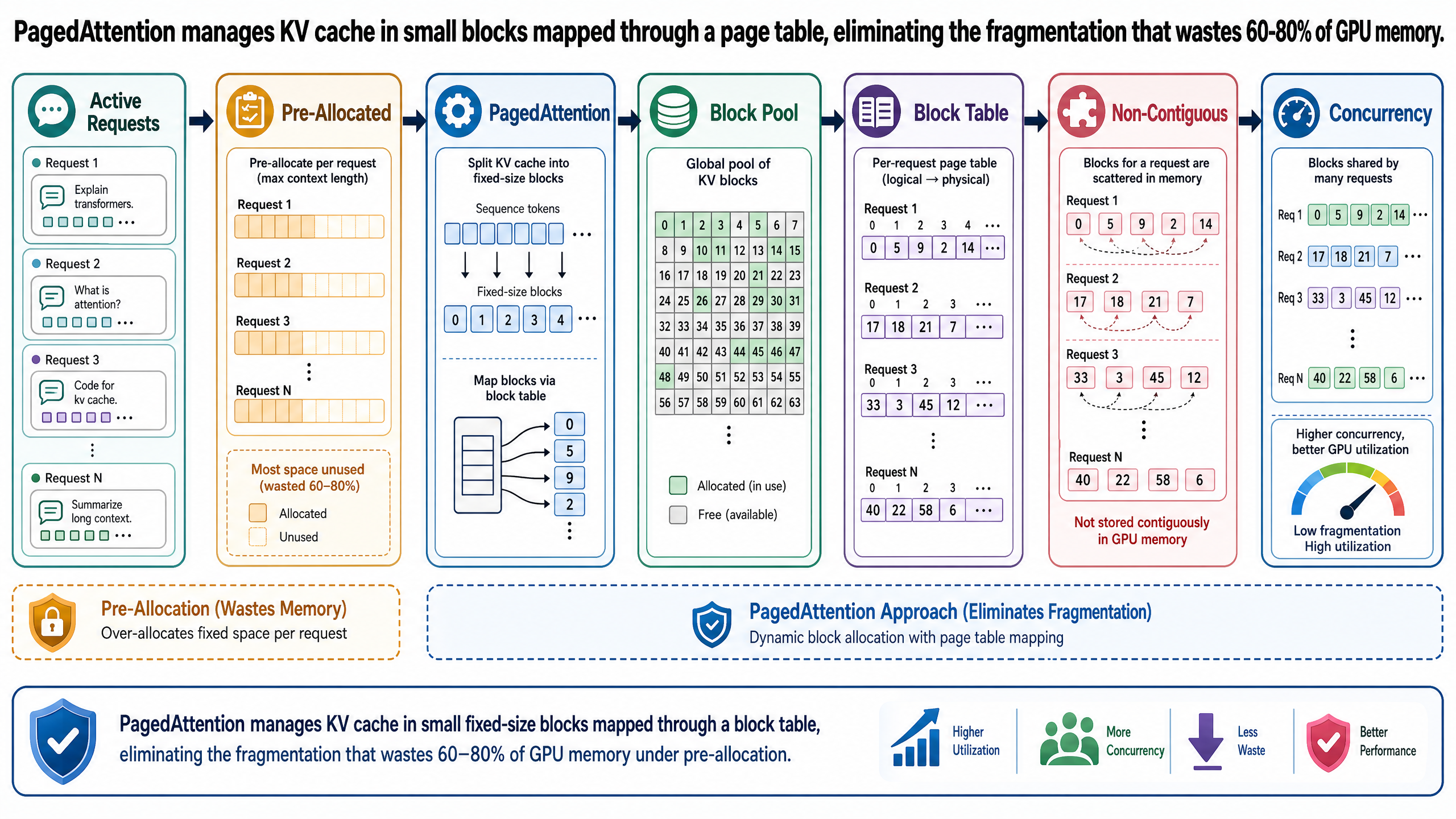
在 PagedAttention 出現之前,推論引擎用最直覺的方式管理 KV 快取記憶體:請求一進來,就預先配一整塊連續的 GPU 記憶體,大到能容納最大可能的序列長度。如果模型上限是 2,048 個 token,那就直接預留 2,048 個 token 的 KV 快取空間,不管這個請求實際上會用到多少。
這種做法帶來三種浪費。
內部碎片化。 一個請求拿到了 2,048 個 token 的空間,結果只用了 400 個。剩下的 1,648 個 token 槽位在整個請求生命週期中都是「佔著不用」——已經分配出去了,別的請求拿不到,但裡面其實什麼有用的資料都沒有。
外部碎片化。 不同請求的生命週期長短不一。有的很快就跑完,有的要跑很久。當短命的請求完成並釋放記憶體,留下來的空隙散落在 GPU 記憶體各處。就算把這些零散的空閒空間加起來夠放一個新請求,卻可能找不到任何一塊夠大的連續區域來放下一個 2,048 token 的分配。記憶體是有,但用不了。
過度預留(over-reservation)。 因為系統猜不到輸出會有多長,只好按最壞情況來配。一個最終只生成 200 個 token 的請求,拿到的記憶體跟一個要生成 2,000 個 token 的請求一模一樣。多出來的部分就這樣被鎖住了,別的請求碰不到,純粹是浪費。
這三種問題疊加起來,影響非常嚴重。Kwon et al. 在 2023 年提出 PagedAttention 的論文中指出,舊系統因為這三種機制浪費了 60-80% 的 KV 快取記憶體。真正存放有用資料的,只佔已分配 KV 快取記憶體的 20-38%,其餘全浪費在碎片化和過度預留上了(Kwon et al., "Efficient Memory Management for Large Language Model Serving with PagedAttention," SOSP 2023)。
換成具體數字來看:一張有 40 GB 可用於 KV 快取的 GPU,真正派上用場的可能只有 8-15 GB。剩下的 25-32 GB 雖然已經分配出去了,卻全被浪費掉。
虛擬記憶體類比
這個問題——動態分配、可變生命週期、不可預測的大小、碎片化——其實不是什麼新鮮事。通用作業系統幾十年前就用虛擬記憶體(virtual memory)和分頁(paging)技術解決過了。
如果你沒修過作業系統這門課,這裡用三段話快速說明核心概念。
當一個程式在你的電腦上執行的時候,它看到的是一大塊連續的記憶體——一段私有的位址空間。程式可以從位址 0 讀取、寫入位址 1,000、跳到位址 50,000,在它看來記憶體就是一段連續的空間。
但實際上,作業系統早就把實體 RAM 切成了一個個固定大小的小單元,叫做分頁(通常每頁 4 KB)。程式所看到的那段連續位址空間其實是一種假象——虛擬位址 0 的資料,可能實際上存在 RAM 位置 80,000;虛擬位址 4,096 的資料,可能跑到 RAM 位置 12,000 去了。實體位置是分散的、不連續的,哪裡有空閒分頁就從哪裡拿。
關鍵角色是分頁表(page table):一種查詢結構,負責把每個虛擬分頁映射到它在 RAM 中的實體位置。程式說「我要位址 5,000 的資料」,作業系統查分頁表,發現對應的虛擬分頁落在實體分頁 312,就從那裡把資料拿出來。程式完全不知道這些,它看到的是連續記憶體,轉譯的工作全由作業系統處理。這就消除了碎片化問題,因為分頁可以塞在任何地方,不需要連續的實體區域。
PagedAttention 做的事情,就是把這個概念搬到 GPU 記憶體中的 KV 快取管理上。
PagedAttention:怎麼運作的
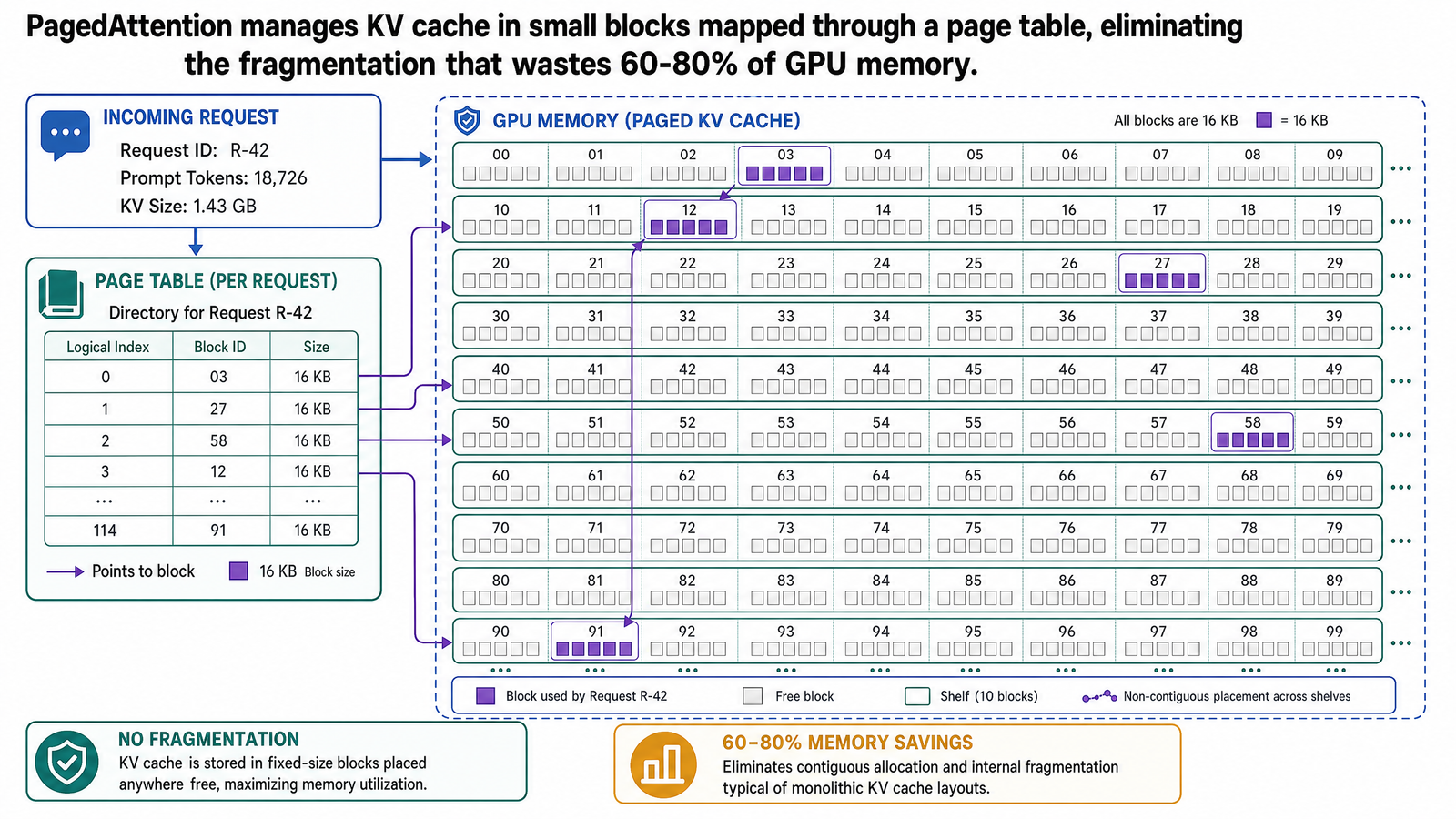
PagedAttention 不再替每個請求配一大塊連續記憶體,而是把 KV 快取切成固定大小的區塊(block)。每個區塊存放固定數量 token 的 key-value 向量——實務上通常是每區塊 16 個 token。
實體區塊(physical block)不會預先綁定給任何請求,而是放在一個全域的空閒區塊池裡,供所有活躍請求共用。哪個請求需要更多 KV 快取空間,就從池子裡拿一個區塊;請求結束了,區塊立刻歸還池子。
這裡最關鍵的創新是:一個請求的各個區塊不需要在 GPU 記憶體中連續排列。一個請求可能把前 16 個 token 放在實體區塊 7、接下來 16 個 token 放在實體區塊 3、再下一批放在實體區塊 12。這些區塊散落在 GPU 記憶體各處,哪裡有空閒區塊就從哪裡拿。
而模型對這些完全不知情。從注意力機制的角度看,KV 快取就是一段連續的 key-value 向量序列。模型所看到的世界跟資料實際所在位置之間的對應關係,靠的是一種叫做區塊表(block table)的結構來處理。
區塊表與非連續分配
每個請求都有自己的區塊表。它是一個小型的查詢結構——你可以把它想成 GPU 版的作業系統分頁表——負責把邏輯區塊(logical block)映射到實體區塊(physical block)。
邏輯區塊是模型所看到的那一面:一段連續的 KV 快取序列。邏輯區塊 0 放的是 token 0-15 的 key-value 向量,邏輯區塊 1 放 token 16-31,邏輯區塊 2 放 token 32-47。模型在計算注意力的時候,就好像它們是整齊排列的。
實體區塊則是資料在 GPU 記憶體中的真實位置,可以散落在任何地方。區塊表負責記錄這層映射:邏輯區塊 0 對應到實體區塊 7,邏輯區塊 1 對應到實體區塊 3,邏輯區塊 2 對應到實體區塊 12。
每筆區塊表條目還會記錄該實體區塊中已經填了多少位置。假設一個請求已生成 41 個 token(區塊大小為 16),區塊表會長這樣:
邏輯區塊 — 實體區塊 — 已填入位置
0 — 7 — 16 / 16
1 — 3 — 16 / 16
2 — 12 — 9 / 16
當模型生成第 42 個 token 時,它的 key-value 向量會被寫進實體區塊 12 的第 10 個位置。等到第 48 個 token 把這個區塊填滿後,系統就從空閒池拿一個新的實體區塊,用新的區塊表條目把它串起來。請求結束時,這三個實體區塊統統歸還池中。
注意力核心(attention kernel)已經改寫過,能支援這種間接存取方式。它不再一口氣讀取一整段連續的記憶體,而是逐區塊去撈 KV 向量,每次都查一下區塊表拿到實體位置。這種查詢帶來的額外開銷跟注意力運算本身比起來微乎其微——但省回來的記憶體卻非常可觀。
還有一個附帶的能力值得提一下。因為區塊表本質上就是一層映射,多個請求可以共享相同的實體區塊。比方說,兩個請求用了相同的系統提示詞,那它們的提示詞 KV 快取就可以指向同一批實體區塊,不用各存一份。這種共享靠引用計數和寫入時複製(copy-on-write)來實現:共享的區塊只有在某個請求需要修改它的時候才會被複製出一份新的。這個機制在 I-04 篇有更完整的討論,那裡的前綴感知路由(prefix-aware routing)會把這種共享做得更系統化。
這裡跟應用系列的交會點。 在應用系列第七篇中,KV 快取是以應用層的概念出場的——提示詞快取(prompt caching)和快取增強生成(cache-augmented generation)是開發者可以直接使用的功能,拿來降低成本和延遲。本文談的是另一回事:KV 快取在推論引擎內部的 GPU 記憶體中是怎麼被管理的。第七篇站在 API 邊界之上,講的是開發者能掌控的東西;本文站在 API 邊界之下,講的是推論引擎在幕後做的事。兩篇都提到「KV 快取」,但它們操作在堆疊的不同層面。
實際範例:50 位小助理使用者,改造前後
回到 I-00 和 I-01 中的場景:50 位旅遊顧問同時在線。每位顧問送出一個飯店空房查詢,裡面包含系統提示詞(200 個 token)、檢索到的飯店上下文(400-800 個 token)和使用者查詢(25 個 token)——加起來大約 625 到 1,025 個輸入 token。輸出長度則看符合條件的飯店有多少,從 100 到 500 個 token 不等。每個請求的總序列長度落在 725 到 1,525 個 token 之間,模型上限是 2,048。
PagedAttention 之前
每個請求一進來就被配了一整塊 2,048 token 的連續 KV 快取。拿一個典型請求來看:625 個輸入 token 加 200 個輸出 token——實際用到 825 個 token。
已分配: 2,048 個 token 槽位
已使用: 825 個 token 槽位
每個請求浪費: 1,223 個 token 槽位(60% 是內部碎片化加上過度預留)
50 個並行請求各要一塊 2,048 token 的連續分配,GPU 很快就撐不住了。實際上大概只能塞 8-12 個並行請求,其餘 38-42 位顧問只能排隊乾等,使用者那頭就盯著轉圈圈的載入畫面。
那 8-12 個請求陸續在不同時間跑完、釋放記憶體之後,外部碎片化就冒出來了。釋放的記憶體東一塊西一塊散落著,可能沒有任何一塊大到能放下新的 2,048 token 連續分配。GPU 上明明有空閒記憶體,卻因為碎片化而用不了。有效利用率:已分配 KV 快取記憶體的 20-38%。
PagedAttention 之後(區塊大小 = 16 個 token)
同樣的 825 token 請求,現在只佔 ceil(825 / 16) = 52 個區塊。每個區塊剛好放 16 個 token 的 KV 快取。
已分配: 52 個區塊(832 個 token 槽位)
已使用: 825 個 token 槽位
浪費: 最後一個區塊裡的 7 個 token 槽位(825 mod 16 = 9 個已填入,7 個空置)
每個請求的浪費: 不到 1%
區塊是一個一個配的,哪裡有空閒區塊就從哪裡拿。不需要連續分配,所以沒有外部碎片化;不用預留 2,048 個 token,所以沒有過度預留。唯一的浪費出在每個序列的最後一個區塊——每個請求最多浪費 15 個 token(block_size - 1)。
浪費幾乎歸零之後,GPU 就能塞下 40-50 個並行請求了。50 位旅遊顧問全部同時獲得服務,沒有人在排隊。同樣的硬體、同樣的模型、同樣的查詢——差別只在記憶體的管理方式。
容量提升大約 4-5 倍:從 8-12 個並行請求一口氣拉到 40-50 個,用的是完全相同的硬體。
對服務容量的影響
記憶體效率直接決定了服務容量。每一個從浪費中回收的實體區塊,就多一個能拿來服務真實使用者的區塊。這不是什麼抽象的最佳化——這是基礎設施團隊到底要買五張 GPU 還是買一張就夠的差別。
基於 PagedAttention 打造的 vLLM,用實際數據說明了這一點。跟那些已經用上連續批次處理的最佳化系統——特別是 FasterTransformer 和 Orca——相比,vLLM 在同樣的延遲水準下,吞吐量(throughput)提升了 2-4 倍。這個改進純粹來自記憶體管理,因為基準系統本身就已經有連續批次處理。如果拿 HuggingFace Transformers 的原始服務方式當對照(既沒有連續批次處理、也沒有分頁式記憶體管理),改進幅度最高可達 24 倍。不過這個較大的數字是兩項最佳化疊加的結果,應該理解為改進的上限,不是 PagedAttention 單獨的功勞。
對開發 AI 系統的工程師來說,這裡的重點是:記憶體管理不是次要的基礎設施細節,它就是並行 LLM 服務的首要瓶頸。兩個用相同模型、同一張 GPU 的推論引擎,光是 KV 快取記憶體的管理方式不一樣,並行使用者數量就能差到 4-5 倍。
這也是為什麼「加記憶體不就好了」這種直覺會誤導人。一張 80 GB 的 GPU 跑預分配式 KV 快取時,真正放了有用資料的可能只有 16-30 GB。不解決碎片化就硬加記憶體,只是多了更多記憶體拿來浪費而已。真正的關鍵是分配策略,不是容量大小。
本文不涵蓋的內容
本文涵蓋了推論引擎如何管理 GPU 記憶體中的 KV 快取——碎片化問題、作業系統分頁類比,以及 PagedAttention 怎麼透過區塊式分配和區塊表來消除浪費。
以下幾個相關主題不在本文範圍內,會在系列的其他篇章中詳細討論。
應用層級的快取決策——什麼時候該用提示詞快取、快取增強生成還是混合檢索——這是應用系列第七篇的主題。那些屬於 API 邊界之上的開發者決策,而本文探討的是 API 邊界之下的機制。
跨請求的 KV 快取重用——當多個請求共用相同的系統提示詞,可以透過前綴感知路由來共享實體區塊——這是 I-04 篇的主題。PagedAttention 提供了共享的基礎機制(引用計數區塊、寫入時複製),但要把它做成系統化的運作方式,還需要 I-04 篇介紹的智慧路由。
預填充(prefill)與解碼的分離是 I-03 篇的主題。PagedAttention 解決了記憶體問題,但預填充和解碼仍然在同一張 GPU 上搶運算資源。一個長上下文的預填充可能卡住該 GPU 上所有的解碼步驟,導致每個活躍使用者的延遲飆升。分離做的事是把兩個階段部署到不同的硬體上——而這又帶出新的 KV 快取問題:預填充在 A 機器上跑、解碼在 B 機器上跑的時候,預填充算好的 KV 快取得傳過去。這部分的傳輸機制與成本,就是 I-03 篇要討論的。
當多個請求有共同的前綴——相同的系統提示詞、相同的少樣本範例、相同的檢索上下文——就有機會讓它們共享 KV 快取區塊,而不是各算各的、各存一份。這個機會本身,以及要抓住它所需要的路由架構,是 I-04 篇的主題。
記憶體問題解決了。接下來,是運算問題。
來源附註
本文引用以下主要來源與實務資料:
Kwon, W., Li, Z., Zhuang, S., Sheng, Y., Zheng, L., Yu, C. H., Gonzalez, J., Zhang, H., and Stoica, I. "Efficient Memory Management for Large Language Model Serving with PagedAttention." SOSP, 2023. PagedAttention 機制的主要來源,包括 60-80% 記憶體浪費的發現、不到 4% 浪費的結果、區塊表設計、虛擬記憶體類比、透過寫入時複製實現記憶體共享,以及吞吐量基準測試(相較 FasterTransformer/Orca 提升 2-4 倍)。arxiv.org/abs/2309.06180
vLLM Project. "vLLM: Easy, Fast, and Cheap LLM Serving with PagedAttention." vLLM Blog, June 2023. SOSP 論文的配套部落格文章,提供易於理解的說明、圖表,以及相較 HuggingFace Transformers 提升 24 倍吞吐量的基準測試。blog.vllm.ai/2023/06/20/vllm.html
vLLM Documentation. "Paged Attention." 區塊表結構、區塊管理器和分配策略的技術文件。docs.vllm.ai/en/stable/design/paged_attention/
Raschka, Sebastian. "Understanding and Coding the KV Cache in LLMs from Scratch." June 2025. KV 快取概念、記憶體大小計算公式,以及從零開始的實作。作為 KV 快取記憶體規模的參考背景。magazine.sebastianraschka.com/p/coding-the-kv-cache-in-llms
Hugging Face. "Caching." Transformers documentation. KV 快取行為的框架級參考,以及快取將二次方成本降低為線性成本的說明。huggingface.co/docs/transformers/en/cache_explanation
Red Hat Developer. "How PagedAttention resolves memory waste of LLM systems." July 2025. 清楚拆解三種碎片化類型(內部碎片化、外部碎片化、過度預留)在 KV 快取分配情境中的說明。developers.redhat.com/articles/2025/07/24/how-pagedattention-resolves-memory-waste-llm-systems
NVIDIA. "Mastering LLM Techniques: Inference Optimization." NVIDIA Developer Blog. KV 快取的背景知識與推論最佳化全景。developer.nvidia.com/blog/mastering-llm-techniques-inference-optimization
Huang Tzu Lin
With over five years in autonomous robotics, there's a strong passion for incorporating cutting-edge technologies and innovative approaches. Dedicated to transforming the latest research and insights into practical applications, this journey pushes the limits of possibility.
相關文章
訂閱最新資訊
將最新技術洞察直接送到您的信箱。