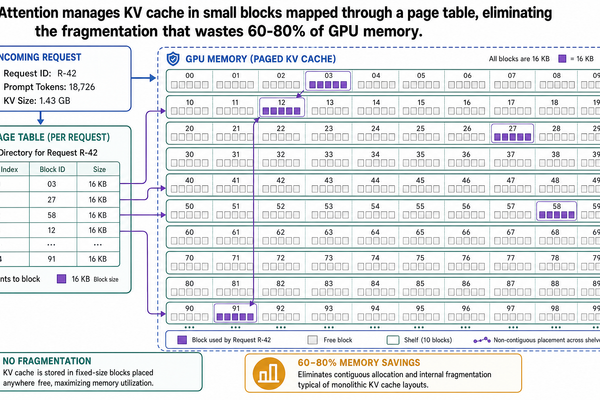
分頁式 KV 快取:LLM 推論服務的 GPU 記憶體管理
在 I-00 篇中,我們走過了一次 API 呼叫從頭到尾通過推論管線的完整流程,也認識了 KV 快取(key-value cache)——一種用來儲存注意力機制中 key-value 向量的資料結構,讓模型不必在每個解碼步驟重複計算這些向量。KV 快取會隨著每個生成的 token 不斷增長,而且在整個請求期間都必須留在 GPU 記憶體裡。到了 I-01 篇,我們又認識了連續批次處理(continuous batching):它在迭代層級進行排程,不再傻等批次中最慢的請求跑完,因此能讓更多請求同時保持運作。
Huang Tzu Lin