前綴感知路由:考量快取狀態的請求分配
閱讀順序
LLM Inference Infrastructure
在 I-02 篇中,我們看到 PagedAttention 讓不同的請求能在同一個模型副本(model replica)上共用物理 KV 快取區塊。兩個使用相同系統提示詞(system prompt)的請求可以指向相同的物理區塊,不需要儲存重複的副本。這個共用機制確實有效——但前提是兩個請求必須落在同一個副本上。
一旦它們落在不同的副本上,共用區塊就不存在了。每個副本只能各自從零開始計算相同的 key-value 向量。I-02 介紹的分頁式記憶體管理在這種情況下完全派不上用場,因為它能帶來的優化根本觸發不了。
這篇要談的,就是什麼因素決定了請求會不會落在同一個副本上——也就是路由層(routing layer)。我們會說明為什麼傳統服務中表現良好的路由策略,套用到 LLM 推論時反而會浪費大量運算,以及更有效的策略怎麼運作。
傳統路由如何運作
如果你建置或維運過 Web 服務,對負載平衡(load balancing)應該不陌生。多個服務副本跑在一個路由器後面,由路由器決定每個進來的請求交給哪個副本處理。最常見的策略有三種。
輪詢(round-robin) 按固定的循環順序把每個請求送到下一個副本。副本 1、副本 2、副本 3、副本 1、副本 2、副本 3。做法簡單、可預測,而且能確保每個副本在一段時間內收到大致相同數量的請求。
最少負載(least-loaded) 把每個請求送到佇列最短的副本。如果副本 2 的佇列中有三個請求而副本 3 只有一個,下一個請求就送到副本 3。相較於輪詢,這種方式更能適應不均勻的處理時間。
Power-of-Two-Choices(隨機二選一) 隨機挑兩個副本,比較它們的佇列長度,然後路由到較空閒的那個。這樣既避免了逐一檢查每個副本的開銷,又能達到接近最佳的負載分布。
這三種策略有一個共同的基本假設:請求是無狀態的。任何副本處理任何請求的效果都一樣好,沒有哪個副本在運算上對特定請求具有優勢。路由器根本不在乎某個副本的記憶體裡目前存放著什麼資料,它只關心公平性和佇列深度。
對於傳統的模型服務——影像分類、文字分類、推薦模型——這個假設是成立的。推論就是一次前向傳播:資料進去、預測出來,呼叫之間不保留任何狀態。把一張貓的照片路由到副本 1 或副本 3,產生的運算量和成本完全相同。
但 LLM 推論不一樣。
浪費的運算問題
回顧 I-00 篇,每個 LLM 請求都以預填充(prefill)階段開始:模型在一次前向傳播中處理整個輸入,為每個輸入 token 計算注意力的 key 和 value 向量,並儲存在 KV 快取中。預填充受運算量限制,成本隨輸入長度而增長。再回顧 I-02 篇,那些 KV 快取條目背後是大量的運算。一旦儲存在 GPU 記憶體中,後續共享相同前綴(prefix)的請求就可以直接重用,完全跳過已快取部分的預填充。
那麼,傳統路由碰上多輪對話時會發生什麼?
一位旅遊顧問在一次對話中發送了五則訊息,為一趟京都團體旅行逐步確認飯店預訂。每則訊息都包含完整的對話歷史:系統提示詞、所有先前的問答,再加上新的查詢和檢索到的資料。輸入從第一輪的 400 個 token 增長到第五輪的 1,700 個。
如果用輪詢路由分散到五個副本,每一輪都會落在不同的副本上。第一輪送到副本 A、第二輪送到副本 B、第三輪送到副本 C,依此類推。每個副本都得從頭處理完整的輸入,因為它手上沒有先前輪次的 KV 快取——那些快取留在別的副本上,根本存取不到。
第二輪預填充了 700 個 token,全部從零開始算。但其中 400 個 token 跟副本 A 在第一輪算過的完全一樣。第五輪預填充了 1,700 個 token,同樣全部從零開始,儘管其中 1,400 個 token 在第四輪已經由另一個副本算過了。
五輪的總預填充量:5,200 個 token,全部從零開始。
如果每一輪都路由到同一個副本,該副本就會保留每一輪的 KV 快取。第二輪只需要預填充 300 個新 token——也就是新的問題和模型上一輪的回應(這些延伸了前綴)。第五輪同樣只需要 300 個新 token。總預填充量降到 1,700 個 token,減少了 67%。
以大約每秒 10,000 個 token 的預填充速率來估算,光是第五輪就省下約 140 毫秒的 TTFT。對於互動式的小助理來說,140 毫秒足以決定使用者感受到的是「即時回應」還是「有點遲鈍」。
這就是任何多輪 LLM 應用放在無狀態負載平衡器後面時的預設行為。路由器對每個請求中最昂貴的運算完全無感,把每一輪都當成跟前一輪毫無關係的獨立請求。
哪些前綴是共用的
運算浪費的問題,只要請求之間共享相同的開頭就會出現。在正式環境的工作負載中,最常見的模式有兩種。
多輪對話。 對話中的每一輪都包含完整的對話歷史作為前綴:系統提示詞,加上所有先前的問答。前綴隨著每一輪不斷增長。只要所有輪次都路由到同一個副本,每一輪就只需要預填充新增的 token。這就是前面範例展示的模式。聊天機器人、客服小助理、有持續會話的程式碼助手——全都會產生這種模式。
共用系統提示詞。 同一個應用程式的許多使用者會共享一個相同的系統提示詞。假設有 50 位旅遊顧問使用 OptiVerse 小助理,他們發送的請求全都以相同的 200 個 token 系統提示詞開頭。如果這些請求被聚集到已經持有系統提示詞 KV 快取的副本上,每個請求就能省下 200 個 token 的預填充。反過來用輪詢的話,請求被分散到各處,完全不考慮快取狀態——某個副本明明已經算好了系統提示詞的快取,後續請求卻被送到別的副本去,這些運算成果就白費了。
這兩種模式經常疊加出現。共用系統提示詞在不同使用者之間創造了共同前綴;多輪對話則在每個使用者的會話中創造出不斷增長的前綴。在正式環境的工作負載中——聊天機器人、程式碼助手、企業小助理——前綴重疊率(prefix overlap rate)通常可以達到輸入 token 的 40-80%。這裡的關鍵是:只要路由層能掌握每個副本的快取狀態,就能把請求導向已經持有匹配前綴的副本,從而避免冗餘的預填充。
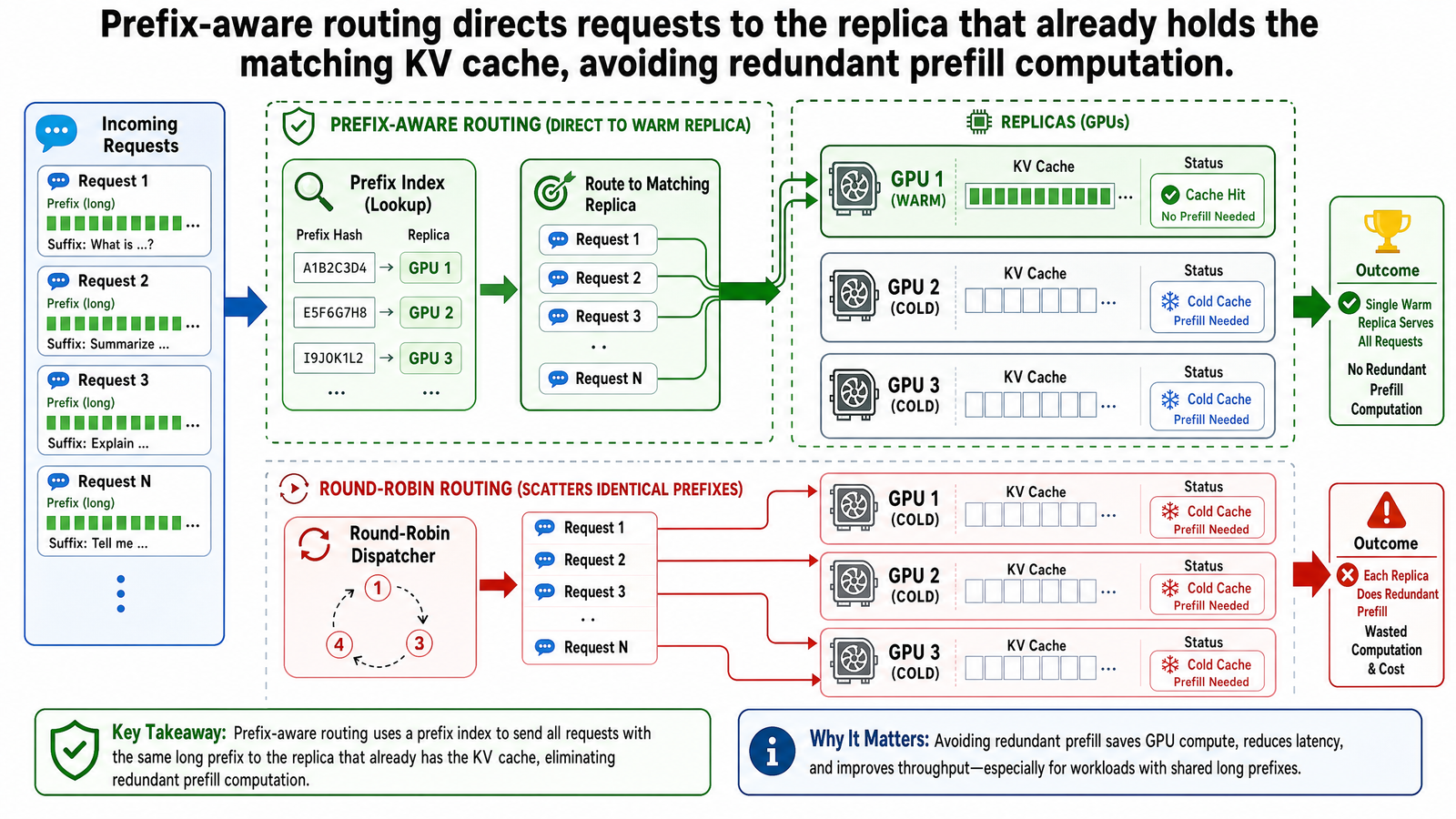
前綴感知路由:如何運作
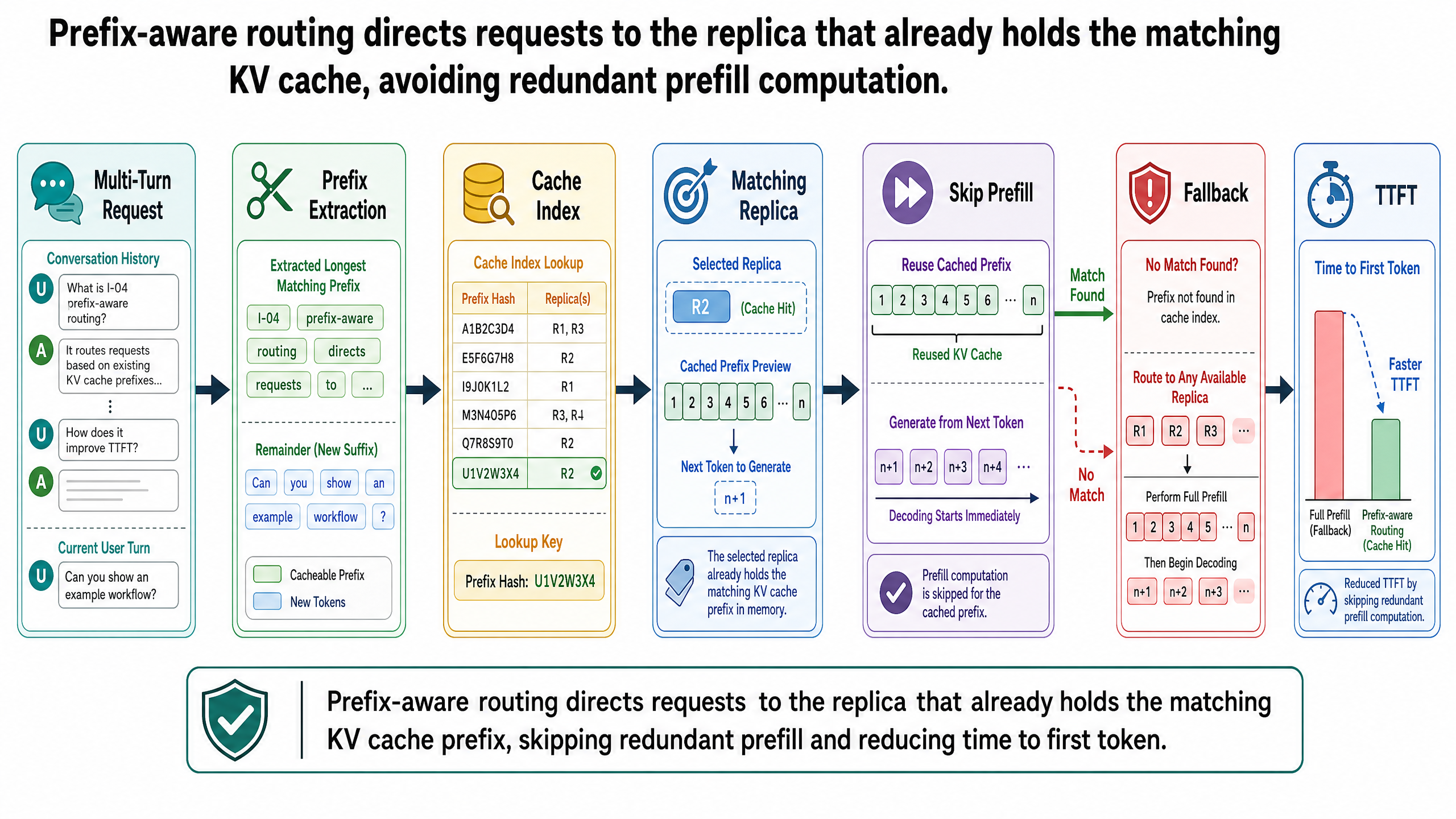
核心機制其實相當直觀。路由器維護一份索引,記錄哪些前綴被快取在哪些副本上。當新請求進來時,路由器提取該請求的 token 前綴、在索引中查詢持有最長匹配快取前綴的副本,然後把請求送過去。如果沒有任何副本有匹配項,路由器就退回到傳統策略,例如最少負載。
換句話說,路由決策不再只看公平性或佇列深度,而是把 KV 快取狀態當成首要的路由依據。
打個比方,可以把它想成按郵遞區號分類郵件。傳統路由就像把每封信交給下一位空閒的郵差,不管信要送到哪裡——那位郵差可能熟悉那條路線,也可能完全不熟。前綴感知路由(prefix-aware routing)則是把京都的信件交給那位已經跑慣京都街區的郵差。他不需要再查地圖,因為路線已經在他腦中了。這裡的路線圖就是 KV 快取,郵遞區號就是前綴。
實作:正式系統怎麼做的
目前有三個正式系統實作了前綴感知路由,各自在服務堆疊的不同層次切入。
SGLang RadixAttention
SGLang 由 Zheng et al. 提出("SGLang: Efficient Execution of Structured Language Model Programs," NeurIPS 2024),採用了架構上最獨特的方式。它把所有已快取的 KV 條目維護在一棵基數樹(radix tree)中——這是一種緊湊的前綴樹,每條邊可以表示多個 token 的序列,而不只是單一 token。
請求進來時,執行環境從樹根開始走訪,將請求的 token 前綴與現有邊進行匹配。假如該請求與先前處理過的請求共享前 1,400 個 token,樹的走訪就會匹配那 1,400 個 token,然後在新請求分歧的位置停下。匹配部分的 KV 快取區塊直接拿來重用,只有未匹配的後綴——也就是新的 token——才需要經過預填充。
沿用前面郵差的比喻:基數樹就是路由器的「已探索街區地圖」。系統提示詞構成根邊,每個分支都共用它。每個使用者的對話歷史從那裡分岔出來,隨著每一輪越長越深。兩個共享相同系統提示詞的使用者從同一條根邊分支出來;各自的對話則延伸成自己的子樹。
GPU 記憶體用盡時,LRU 驅逐會移除最久未被存取的葉節點,釋放區塊給新條目。前端只管送出完整的提示,執行環境自動處理前綴匹配、重用、快取和驅逐。
實際效果相當可觀。SGLang 相比基準服務系統達到高達 5 倍的吞吐量提升,在前綴變化率高的工作負載上甚至達到 6.4 倍。當前綴快取命中(cache hit)時,TTFT 的降低幅度直接對應省下的運算量:每個被快取的 token 就是一個跳過預填充的 token。
vLLM 自動前綴快取(APC)
vLLM 用不同的資料結構來解決同一個問題。它不靠樹,而是用基於雜湊的區塊匹配(hash-based block matching)。每個 KV 快取區塊由一個雜湊值來標識,這個雜湊值取決於兩個因素:區塊本身的 token 內容,以及所有前面區塊的雜湊值。這就形成一條類似 Merkle 樹的鏈,每個區塊的身分都編碼了它整個前綴歷史。
新請求進來時,vLLM 先計算該請求輸入的區塊雜湊值,然後逐一比對現有的快取區塊。匹配的區塊直接重用;只有未匹配的部分才需要預填充。整個過程是自動的:APC 在 vLLM 中預設就開著,不需要改請求格式就能透明運作。
從效能角度看,基於雜湊的方式以每區塊 O(1) 的查詢取代了樹的走訪。實務上,循序雜湊鏈對於連續前綴達成的效果與 RadixAttention 的樹走訪是一樣的。
Ray Serve PrefixCacheAffinityRouter
SGLang 和 vLLM 都在引擎層級運作——在單一推論引擎實例內,對應一組或少數幾組 GPU。Ray Serve 則在更上一層:叢集路由層級,負責把請求分配到多個推論引擎副本。
PrefixCacheAffinityRouter 實作了一套多層路由策略,直接處理快取親和性(cache affinity)和負載平衡之間的拉扯。路由器首先比較各副本的佇列長度,判斷負載是否均衡。如果負載最重和最輕的副本之間的差異低於可配置的閾值(imbalanced_threshold,預設為 10 個請求),路由器就用前綴樹去找前綴匹配最好的副本。一旦負載不均衡——佇列差異超過閾值——路由器就退回到最少負載路由,避免產生熱點。
第二個參數 match_rate_threshold(預設 0.1)設定了啟用前綴感知路由所需的最低前綴匹配品質。如果最佳匹配覆蓋的前綴不到 10%,路由器就判定為快取未命中(cache miss),改用基於負載的路由。
在 DeepSeek-R1-Distill-Qwen-32B 模型上的基準測試——部署在 8 台機器、64 個 GPU 上——顯示 TTFT 降低 60%,端到端吞吐量提升超過 40%。若工作負載具有長共用前綴,吞吐量提升甚至超過 2.5 倍。
值得注意的是這裡的分層架構。SGLang 和 vLLM 在單一引擎內優化前綴重用;Ray Serve 則優化請求該送到哪個引擎。在正式環境中,這些層級搭配運作:Ray Serve 把請求路由到最可能持有匹配前綴的副本,副本內部再由 SGLang 或 vLLM 處理區塊層級的快取匹配。
實際範例:5 輪對話
回到那位旅遊顧問確認京都飯店預訂的場景,以下是每一輪的具體數字。
第一輪: 系統提示詞(200 個 token)+ 「幫我找京都每晚 200 美元以下、有無障礙設施的飯店」(25 個 token)+ 檢索到的飯店上下文(175 個 token)= 400 個輸入 token。
第二輪: 先前上下文(400 個 token)+ 助手回應(100 個 token)+ 「其中哪些有溫泉?」(25 個 token)+ 檢索到的設施資料(175 個 token)= 700 個輸入 token。
第三輪: 先前上下文(700 個 token)+ 助手回應(100 個 token)+ 「比較前三名的取消政策」(25 個 token)+ 檢索到的政策資料(175 個 token)= 1,000 個輸入 token。
第四輪: 先前上下文(1,000 個 token)+ 助手回應(150 個 token)+ 「預訂第二個選項,4 月 15 日到 20 日」(25 個 token)+ 訂房系統上下文(225 個 token)= 1,400 個輸入 token。
第五輪: 先前上下文(1,400 個 token)+ 助手回應(100 個 token)+ 「加上機場接送並確認總金額」(25 個 token)+ 接送定價資料(175 個 token)= 1,700 個輸入 token。
輪詢路由(每一輪落在不同的副本)
輪次 — 總輸入 token — 已快取 — 從零開始計算
1 — 400 — 0 — 400
2 — 700 — 0 — 700
3 — 1,000 — 0 — 1,000
4 — 1,400 — 0 — 1,400
5 — 1,700 — 0 — 1,700
合計 — 5,200 — 0 — 5,200
每一輪都是冷啟動。先前各輪的 KV 快取留在不同的副本上,根本碰不到。
前綴感知路由(所有輪次落在同一個副本)
輪次 — 總輸入 token — 已快取(重用) — 從零開始計算
1 — 400 — 0 — 400
2 — 700 — 400 — 300
3 — 1,000 — 700 — 300
4 — 1,400 — 1,000 — 400
5 — 1,700 — 1,400 — 300
合計 — 5,200 — 3,500 — 1,700
預填充節省量:3,500 個 token,減少 67%。第一輪之後的每一輪都重用了前一輪的完整前綴,只需要預填充新增的部分——新的使用者問題、模型上一輪的回應,以及新檢索到的上下文。
TTFT 的影響很明確。以大約每秒 10,000 個 token 的預填充速率來算:
輪詢下的第五輪:1,700 個 token / 10,000 = 170 毫秒的預填充時間
前綴感知路由下的第五輪:300 個 token / 10,000 = 30 毫秒的預填充時間
光是第五輪就省下約 140 毫秒
整個對話的累計預填充時間從大約 520 毫秒降至大約 170 毫秒。
接著把場景擴展到共用系統提示詞的情境。全部 50 位旅遊顧問都使用 OptiVerse 小助理,發送的請求全以相同的 200 個 token 系統提示詞開頭。用前綴感知路由時,請求會聚集到已經持有系統提示詞 KV 快取的副本上。到達每個副本的第一個請求負責暖機,之後送到該副本的每個請求都跳過 200 個 token 的預填充。50 位使用者分佈在 5 個副本上,每個副本的第一個請求建立快取,之後的 9 個請求各省下 200 個 token。合計避免了 9,000 個 token 的冗餘運算。換成輪詢的話,使用者被隨意分散、不考慮快取狀態,這些節省大部分就浪費掉了。
兩種模式會疊加。當一個對話既和其他使用者共享系統提示詞,又在自己的各輪之間共享對話歷史時,前綴感知路由能同時捕捉到這兩層重用。
取捨與限制
前綴感知路由並非在所有情況下都優於傳統負載平衡。收益取決於工作負載特性,而且這個機制帶來了正式環境必須面對的取捨。
負載不平衡。 為了快取親和性而優化,可能會把流量集中到少數副本上。如果所有帶著同一個熱門系統提示詞的請求都路由到同一個副本,該副本就會變成熱點,其他副本反而閒置。這是前綴感知路由的根本張力:對快取最有利的決策(路由到持有匹配前綴的副本)往往和對負載最有利的決策(路由到最閒的副本)互相衝突。正式系統透過混合策略來處理這個問題。Ray Serve 的 imbalanced_threshold 會在佇列長度分歧時明確犧牲快取親和性來換取負載平衡。DualMap 系統則更進一步把這個張力形式化,使用雙雜湊環排程策略(dual-hash-ring scheduling strategy)搭配 SLO 感知切換,在相同的 TTFT 約束下將有效請求容量提升高達 2.25 倍。
路由複雜度。 路由器必須維護一份前綴索引——基數樹、雜湊表之類的結構——並對每個進來的請求做查詢。這會為路由決策本身增加些許延遲。實務上,這個開銷通常在亞毫秒級,遠小於它帶來的預填充節省。但這畢竟是需要建構、維護和除錯的額外基礎設施。對於只有單一副本的簡單部署來說,這些複雜度不會帶來任何好處。
工作負載依賴性。 前綴感知路由在前綴重疊率高時收益最大。具有共用系統提示詞的聊天機器人、具有長對話歷史的程式碼助手、使用標準化提示的企業小助理,都屬於理想的工作負載。至於內容多樣、彼此無關的批次推論——每個請求的前綴都是獨特的,跟其他請求沒有交集——傳統路由可能更簡單也同樣有效,因為根本沒有前綴可以重用。llm-d 專案在以共用前綴為核心的基準測試中,展示了精確前綴快取感知排程的顯著收益,包括重複請求回應大幅加快,並在相同硬體上達到約兩倍吞吐量。不過要注意,這些數字反映的是本身就具有高前綴重疊率的工作負載。不具備這個特性的工作負載,收益會小得多。
快取驅逐壓力。 GPU 記憶體是有限的,所有正式實作都使用驅逐策略——通常是 LRU——在記憶體用盡時移除已快取的前綴。在高流量、前綴多樣的情況下,快取條目可能還來不及被重用就已經被驅逐了。這時快取命中率會下降,而路由開銷卻沒有帶來對應的收益。要判斷是否遇到這個問題,可以觀察一個典型症狀:高驅逐率搭配低快取命中率——系統花了力氣維護索引和做路由決策,但底層快取的更替速度太快,根本來不及發揮效益。
過時的路由決策。 路由器的前綴索引可能跟副本上的實際快取狀態有時間差。一個已快取的前綴可能在路由決策做完到請求實際抵達之間就被驅逐了,導致預期的快取命中變成未命中。請求本身還是會正確處理,只是享受不到快取帶來的好處。前綴感知路由本質上是一種盡力而為的優化,不是保證——不過即使個別決策偶爾失準,整體的統計收益仍然是正向的。
擴容後的冷啟動。 當新副本透過自動擴容加入時,它的 KV 快取是空的。前綴感知路由不會主動把請求送給它,因為沒有已快取的前綴可以匹配。正式系統的做法是退回到最少負載路由,讓流量自然導向閒置的新副本。
總結來說,前綴感知路由是專門針對高前綴重疊率工作負載的優化,而不是傳統負載平衡的通用替代品。設計最完善的正式系統把它當成一種路由偏好——在負載平衡有需要時,隨時可以被覆寫。
本文不涵蓋的範圍
本文涵蓋了推論基礎設施如何根據 KV 快取前綴狀態將請求路由到副本:快取盲目路由的問題、前綴重疊的來源、前綴感知路由的機制、三個正式實作,以及相關的取捨。
有幾個相關主題屬於其他文章的範疇,本文沒有涉及。應用層級的提示快取——供應商為明確標記的提示前綴快取 KV 狀態的開發者面向 API 功能——是主系列第 07 篇的主題。那屬於 API 邊界之上、由開發者控制的範疇。本文討論的則是 API 邊界之下、由推論基礎設施自動完成的部分。兩者是互補的。KV 快取記憶體管理(PagedAttention、區塊表)是 I-02 篇的主題,在這裡作為基礎前提。預填充池與解碼池之間的 KV 快取傳輸屬於分離式架構(disaggregated architecture),是 I-03 篇的主題。
到目前為止,在這個系列中,我們已經看過請求如何被批次處理(I-01)、KV 快取記憶體如何被管理(I-02)、預填充和解碼如何被分離(I-03),以及請求如何被路由以利用快取局部性(cache locality)(本文)。不過還有一個面向尚未觸及。到目前為止的討論都假設模型可以整齊地放入單一 GPU 或少數幾個副本中。那如果模型本身太大、沒辦法簡單複製呢?如果它使用混合專家架構(mixture-of-experts),模型的不同部分會對不同的輸入啟動,需要一種根本不同的分片和路由策略——不是在請求層級,而是在模型內部的 token 層級呢?
那就是 I-05 篇的主題:混合專家模型的專家並行服務。
資料來源
本文依據以下主要文獻和實務來源:
Zheng, L., Yin, L., Xie, Z., et al. "SGLang: Efficient Execution of Structured Language Model Programs." NeurIPS, 2024. RadixAttention 機制、基數樹結構、LRU 驅逐策略和吞吐量基準測試(高達 5-6.4 倍提升)的主要來源。arxiv.org/abs/2312.07104
LMSYS. "Fast and Expressive LLM Inference with RadixAttention and SGLang." January 2024. 附帶易懂視覺範例的配套部落格文章,涵蓋基數樹運作和跨多輪對話、少樣本學習與結構化生成的前綴重用模式。lmsys.org/blog/2024-01-17-sglang/
Kwon, W., Li, Z., Zhuang, S., et al. "Efficient Memory Management for Large Language Model Serving with PagedAttention." SOSP, 2023. 透過寫入時複製和引用計數實現區塊層級 KV 快取共用的基礎。作為 I-02 篇的前提知識引用。arxiv.org/abs/2309.06180
vLLM. "Automatic Prefix Caching." vLLM 基於雜湊的前綴快取機制官方文件,包括類似 Merkle 樹的區塊雜湊鏈和自動重用匹配前綴區塊。docs.vllm.ai/en/stable/design/prefix_caching/
Ray Serve. "Prefix-aware routing." PrefixCacheAffinityRouter 官方文件,包括多層路由策略、
imbalanced_threshold和match_rate_threshold配置參數,以及退回行為。docs.ray.io/en/latest/serve/llm/user-guides/prefix-aware-routing.html
Anyscale. "Ray Serve: Reduce LLM Inference Latency by 60% with Custom Request Routing." 基準測試部落格文章,報告在 DeepSeek-R1-Distill-Qwen-32B 模型、8 台機器(64 個 GPU)上 TTFT 降低 60%、吞吐量提升超過 40%,前綴密集型工作負載吞吐量提升超過 2.5 倍。anyscale.com/blog/ray-serve-faster-first-token-custom-routing
DualMap. "Enabling Both Cache Affinity and Load Balancing for Distributed LLM Serving." ICLR, 2026. 使用雙雜湊環排程策略和 SLO 感知切換,形式化快取親和性與負載平衡之間的張力。在 TTFT 約束下有效容量提升高達 2.25 倍。arxiv.org/abs/2602.06502
llm-d project. "KV-Cache Wins You Can See: From Prefix Caching in vLLM to Distributed Scheduling with llm-d." Kubernetes 原生前綴感知路由框架。報告精確前綴快取感知排程的基準收益,包括在共用前綴的 Qwen/Qwen-32B 設定中,重複回應快 57 倍,吞吐量約為兩倍。llm-d.ai/blog/kvcache-wins-you-can-see
NVIDIA. "Mastering LLM Techniques: Inference Optimization." NVIDIA Developer Blog. 通用推論優化背景,包括預填充/解碼區分和 KV 快取角色。developer.nvidia.com/blog/mastering-llm-techniques-inference-optimization
Huang Tzu Lin
With over five years in autonomous robotics, there's a strong passion for incorporating cutting-edge technologies and innovative approaches. Dedicated to transforming the latest research and insights into practical applications, this journey pushes the limits of possibility.
相關文章
訂閱最新資訊
將最新技術洞察直接送到您的信箱。