Prefix-Aware Routing: Cache-Conscious Request Distribution
Reading order
LLM Inference Infrastructure
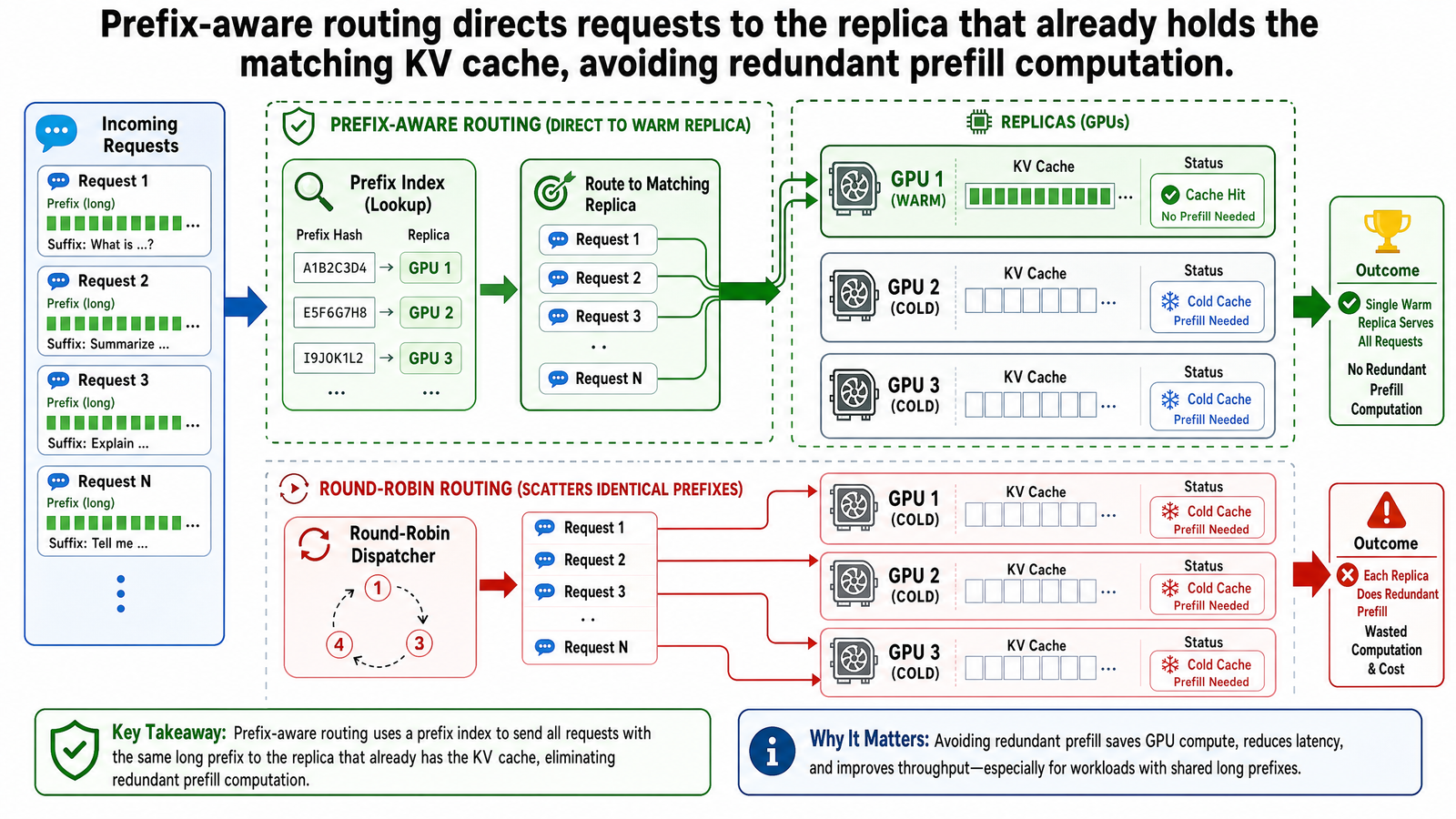
Table of Contents
- How Traditional Routing Works
- The Wasted Computation Problem
- What Prefixes Are Shared
- Prefix-Aware Routing: How It Works
- Implementations: How Production Systems Do It
- SGLang RadixAttention
- vLLM Automatic Prefix Caching (APC)
- Ray Serve PrefixCacheAffinityRouter
- Running Example: 5-Turn Conversation
- Round-robin routing (each turn hits a different replica)
- Prefix-aware routing (all turns hit the same replica)
- Trade-offs and Limitations
- What This Post Is Not
- Source Notes
In Post I-02, we saw that PagedAttention enables different requests to share physical KV cache blocks on the same replica. Two requests with the same system prompt can point to the same physical blocks rather than storing duplicate copies. That sharing mechanism is real and it works -- but only if both requests land on the same replica.
If they land on different replicas, the shared blocks never exist. Each replica computes the same key-value vectors from scratch. The paged memory management that I-02 described so carefully becomes irrelevant, because the optimization it enables was never triggered.
This post is about what determines whether those requests land on the same replica: the routing layer. Specifically, it is about why the routing strategies that work well for traditional services waste significant computation when applied to LLM inference, and what a better strategy looks like.
How Traditional Routing Works
If you have built or operated a web service, you are familiar with load balancing. Multiple replicas of a service run behind a router, and the router decides which replica handles each incoming request. Three strategies dominate.
Round-robin sends each request to the next replica in a fixed cyclic order. Replica 1, Replica 2, Replica 3, Replica 1, Replica 2, Replica 3. It is simple, predictable, and ensures that each replica receives roughly the same number of requests over time.
Least-loaded sends each request to the replica with the shortest queue. If Replica 2 has three requests in its queue and Replica 3 has one, the next request goes to Replica 3. This adapts to uneven processing times better than round-robin.
Power-of-two-choices picks two replicas at random, compares their queue lengths, and routes to the less busy one. It avoids the overhead of checking every replica while still achieving near-optimal load distribution.
All three strategies share a fundamental assumption: requests are stateless. Any replica can handle any request equally well because no replica has a computational advantage over another for any particular request. The router does not care what data a replica already holds in memory. It cares about fairness and queue depth.
For traditional model serving -- image classification, text classification, recommendation models -- this assumption holds. Inference is a single forward pass: data in, prediction out, no per-request state persists between calls. Routing a cat photo to Replica 1 or Replica 3 produces the same computation at the same cost.
LLM inference is different.
The Wasted Computation Problem
Recall from I-00 that every LLM request begins with a prefill phase: the model processes the entire input in a single forward pass, computing attention key and value vectors for every input token and storing them in the KV cache. Prefill is compute-bound and its cost scales with input length. Recall from I-02 that those KV cache entries represent significant computational work. Once stored in GPU memory, they can be reused for subsequent requests that share the same prefix, skipping prefill for the cached portion entirely.
Now consider what happens when traditional routing meets multi-turn conversation.
A travel agent sends five messages in a conversation, refining a hotel booking for a group trip to Kyoto. Each message includes the full conversation history: system prompt, all previous questions and responses, and the new query with retrieved data. The input grows from 400 tokens on the first turn to 1,700 on the fifth.
With round-robin routing across five replicas, each turn hits a different replica. Turn 1 goes to Replica A, Turn 2 to Replica B, Turn 3 to Replica C, and so on. Each replica processes the full input from scratch because it has no KV cache from the previous turns -- that cache exists on a different replica, inaccessible.
Turn 2 prefills 700 tokens from zero. But 400 of those tokens are identical to what Replica A already computed during Turn 1. Turn 5 prefills 1,700 tokens from zero, even though 1,400 of those tokens were already computed by a different replica during Turn 4.
The total prefill across all five turns: 5,200 tokens, all computed from scratch.
If every turn had been routed to the same replica, that replica would have retained the KV cache from each turn. Turn 2 would need to prefill only the 300 new tokens -- the new question and the model's response from Turn 1 that extended the prefix. Turn 5 would need only 300 new tokens. The total prefill drops to 1,700 tokens: a 67% reduction.
At a prefill rate of roughly 10,000 tokens per second, the fifth turn alone saves approximately 140 milliseconds of TTFT. For an interactive copilot, 140 milliseconds is the difference between a response that feels instant and one that feels sluggish.
This is the default behavior of any multi-turn LLM application served behind a stateless load balancer. The router is oblivious to the most expensive per-request computation and treats every turn as if it has no relationship to the one before it.
What Prefixes Are Shared
The wasted computation problem appears wherever requests share a common beginning. Two patterns dominate in production workloads.
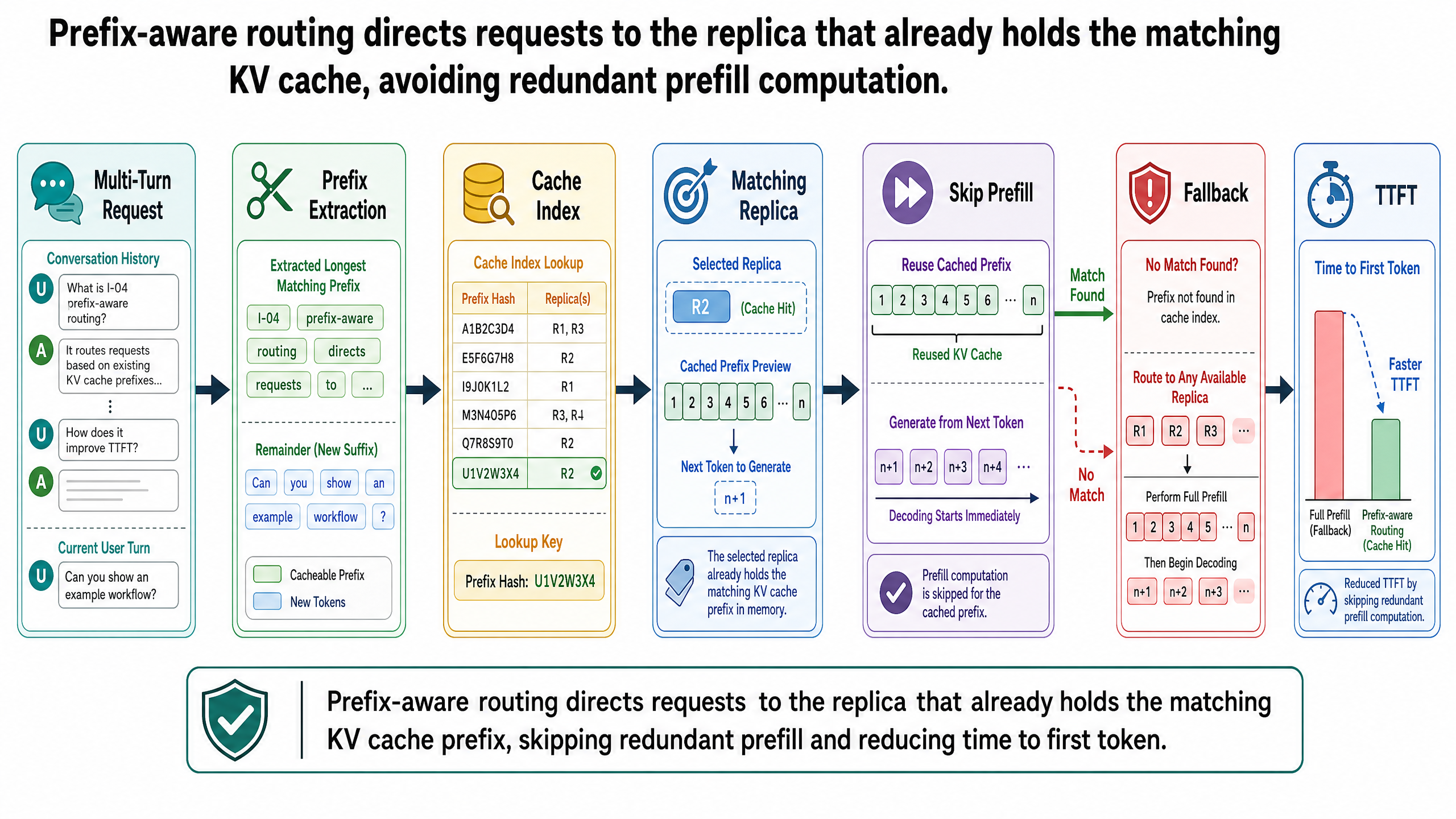
Multi-turn conversations. Each turn in a conversation includes the full conversation history as its prefix: the system prompt, plus all previous questions and responses. The prefix grows with every turn. If all turns route to the same replica, only the new tokens in each turn require prefill. This is the pattern the running example illustrates. Chatbots, customer support copilots, coding assistants with ongoing sessions -- all generate this pattern.
Shared system prompts. Many users of the same application share an identical system prompt. The 50 travel agents using the OptiVerse copilot all send requests beginning with the same 200-token system prompt. If these requests cluster on replicas that already have the system prompt KV cache, those 200 tokens of prefill are saved per request. With round-robin, requests scatter without regard to cache state, and replicas that computed the system prompt cache see their work wasted when subsequent requests go elsewhere.
These two patterns often compound. A shared system prompt creates a common prefix across users; multi-turn conversations create growing prefixes within each user's session. In production workloads -- chatbots, coding assistants, enterprise copilots -- prefix overlap rates routinely reach 40-80% of input tokens. The opportunity: if the routing layer knows what each replica has cached, it can avoid redundant prefill by directing requests to the replica that already holds the matching prefix.
Prefix-Aware Routing: How It Works
The core mechanism is straightforward. The router maintains an index of which prefixes are cached on which replicas. When a new request arrives, the router extracts the request's token prefix, queries the index for the replica with the longest matching cached prefix, and routes the request there. If no replica has a match, the router falls back to a traditional strategy like least-loaded.
The routing decision is no longer about fairness or queue depth alone. It incorporates KV cache state as a first-class routing signal.
Think of it as sorting mail by ZIP code. Traditional routing is like handing each letter to the next available mail carrier, regardless of the letter's destination. The carrier may or may not know the route. Prefix-aware routing is like giving the Kyoto letters to the carrier who already knows the Kyoto neighborhoods. That carrier does not need to look up the map again -- the map is already in their head. The map is the KV cache. The ZIP code is the prefix.
Implementations: How Production Systems Do It
Three production systems implement prefix-aware routing, each at a different layer of the serving stack.
SGLang RadixAttention
SGLang, introduced by Zheng et al. (NeurIPS 2024), takes the most architecturally distinctive approach. It maintains all cached KV entries in a radix tree -- a compact prefix tree where each edge can represent a multi-token sequence rather than a single token.
When a request arrives, the runtime walks the tree from the root, matching the request's token prefix against existing edges. If the request shares its first 1,400 tokens with a previously processed request, the tree walk matches those 1,400 tokens and stops at the point where the new request diverges. The KV cache blocks for the matched portion are reused directly. Only the unmatched suffix -- the new tokens -- goes through prefill.
The radix tree is the router's map of which neighborhoods have already been learned. The system prompt forms the root edge, shared by every branch. Each user's conversation history branches from there, growing deeper with each turn. Two users sharing the same system prompt branch from the same root edge; each user's conversation extends into its own subtree.
When GPU memory is full, LRU eviction removes the leaf nodes that have not been accessed recently, freeing blocks for new entries. The frontend sends full prompts; the runtime handles prefix matching, reuse, caching, and eviction automatically.
The results are substantial. SGLang achieves up to 5x throughput improvement over baseline serving systems, with up to 6.4x on workloads with high prefix variation. The TTFT reductions when prefix cache hits occur track the arithmetic directly: every cached token is a token of prefill skipped.
vLLM Automatic Prefix Caching (APC)
vLLM takes a different structural approach to the same problem. Instead of a tree, vLLM uses hash-based block matching. Each KV cache block is identified by a hash that depends on two things: the block's own token content and the hashes of all preceding blocks. This creates a Merkle tree-like chain where each block's identity encodes its entire prefix history.
When a new request arrives, vLLM pre-computes the block hashes for the request's input and checks each hash against its cache of existing blocks. Matching blocks are reused; only the unmatched blocks require prefill computation. The approach is automatic: APC is enabled by default in vLLM and works transparently without changes to the request format.
The hash-based approach trades tree traversal for O(1) lookups per block. In practice, the sequential hash chaining achieves the same effect as RadixAttention's tree walk for contiguous prefixes.
Ray Serve PrefixCacheAffinityRouter
SGLang and vLLM operate at the engine level -- within a single inference engine instance on one or a small set of GPUs. Ray Serve operates one layer up: at the cluster routing level, distributing requests across multiple inference engine replicas.
The PrefixCacheAffinityRouter implements a multi-tier routing strategy that directly addresses the tension between cache affinity and load balance. The router first checks whether load is balanced across replicas by comparing queue lengths. If the difference between the most-loaded and least-loaded replica is below a configurable threshold (the imbalanced_threshold, default 10 requests), the router uses a prefix tree to find the replica with the best prefix match. If load is imbalanced -- the queue difference exceeds the threshold -- the router falls back to least-loaded routing to prevent hotspots.
A second parameter, the match_rate_threshold (default 0.1), sets the minimum prefix match quality required before prefix-aware routing is used. If the best match covers less than 10% of the request's prefix, the router treats it as effectively a miss and uses load-based routing instead.
Benchmarks on a DeepSeek-R1-Distill-Qwen-32B model deployed across 8 machines with 64 GPUs showed a 60% reduction in TTFT and more than 40% improvement in end-to-end throughput. For workloads with long, shared prefixes, throughput improvements exceeded 2.5x.
The layered architecture matters. SGLang and vLLM optimize prefix reuse within a single engine. Ray Serve optimizes which engine a request reaches. In production, these compose: Ray Serve routes to the replica most likely to hold the matching prefix, and within that replica, SGLang or vLLM handles block-level cache matching.
Running Example: 5-Turn Conversation
Return to the travel agent refining a Kyoto hotel booking. Here are the exact numbers for each turn.
Turn 1: System prompt (200 tokens) + "Show me wheelchair-accessible hotels in Kyoto under $200/night" (25 tokens) + retrieved hotel context (175 tokens) = 400 input tokens.
Turn 2: Previous context (400 tokens) + agent response (100 tokens) + "Which of those have onsen access?" (25 tokens) + retrieved amenity data (175 tokens) = 700 input tokens.
Turn 3: Previous context (700 tokens) + agent response (100 tokens) + "Compare the top 3 on cancellation policies" (25 tokens) + retrieved policy data (175 tokens) = 1,000 input tokens.
Turn 4: Previous context (1,000 tokens) + agent response (150 tokens) + "Book the second option for April 15-20" (25 tokens) + booking system context (225 tokens) = 1,400 input tokens.
Turn 5: Previous context (1,400 tokens) + agent response (100 tokens) + "Add airport transfer and confirm the total" (25 tokens) + transfer pricing data (175 tokens) = 1,700 input tokens.
Round-robin routing (each turn hits a different replica)
Turn — Total input tokens — Cached — Computed from scratch
1 — 400 — 0 — 400
2 — 700 — 0 — 700
3 — 1,000 — 0 — 1,000
4 — 1,400 — 0 — 1,400
5 — 1,700 — 0 — 1,700
Total — 5,200 — 0 — 5,200
Every turn is a cold start. The KV cache from each previous turn exists on a different replica, unreachable.
Prefix-aware routing (all turns hit the same replica)
Turn — Total input tokens — Cached (reused) — Computed from scratch
1 — 400 — 0 — 400
2 — 700 — 400 — 300
3 — 1,000 — 700 — 300
4 — 1,400 — 1,000 — 400
5 — 1,700 — 1,400 — 300
Total — 5,200 — 3,500 — 1,700
Prefill savings: 3,500 tokens, a 67% reduction. Each turn after the first reuses the full prefix from the previous turn and only prefills the new tokens -- the new user question, the model's previous response, and the new retrieved context.
The TTFT impact is concrete. At a prefill rate of approximately 10,000 tokens per second:
Turn 5 under round-robin: 1,700 tokens / 10,000 = 170 ms of prefill time
Turn 5 under prefix-aware routing: 300 tokens / 10,000 = 30 ms of prefill time
Savings on Turn 5 alone: ~140 ms
Across the full conversation, cumulative prefill time drops from roughly 520 ms to 170 ms.
Now scale this to the shared system prompt scenario. All 50 travel agents using the OptiVerse copilot send requests that begin with the same 200-token system prompt. With prefix-aware routing, requests cluster on replicas that already hold the system prompt KV cache. The first request to each replica primes the cache; every subsequent request to that replica skips 200 tokens of prefill. With 50 users across 5 replicas, that is 45 requests (9 per replica after the first) saving 200 tokens of prefill each -- 9,000 tokens of redundant computation avoided. With round-robin, users are scattered without regard to cache state, and many of those savings are lost.
The two patterns compound. When a conversation shares a system prompt with other users and shares conversation history across its own turns, prefix-aware routing captures both layers of reuse simultaneously.
Trade-offs and Limitations
Prefix-aware routing is not universally superior to traditional load balancing. The benefit depends on the workload, and the mechanism introduces trade-offs that production systems must manage.
Load imbalance. Optimizing for cache affinity can concentrate traffic on fewer replicas. If all requests with the same popular system prompt route to the same replica, that replica becomes a hotspot while others sit idle. This is the fundamental tension in prefix-aware routing: the cache-optimal decision (route to the replica with the matching prefix) can conflict with the load-optimal decision (route to the least-loaded replica). Production systems address this with hybrid strategies. Ray Serve's imbalanced_threshold explicitly trades off cache affinity for load balance when queue lengths diverge. The DualMap system formalizes this tension further, using a dual-hash-ring scheduling strategy with SLO-aware switching to achieve both cache affinity and load balance, improving effective request capacity by up to 2.25x under the same TTFT constraints.
Routing complexity. The router must maintain a prefix index -- a radix tree, hash table, or similar structure -- and query it for every incoming request. This adds latency to the routing decision itself. In practice, the overhead is typically sub-millisecond and far smaller than the prefill savings it enables. But it is additional infrastructure to build, maintain, and debug. For simple deployments with a single replica, the complexity adds nothing.
Workload dependency. Prefix-aware routing helps most when prefix overlap is high. Chatbots with shared system prompts, coding assistants with long conversation histories, and enterprise copilots with standardized prompts are ideal workloads. For batch inference over diverse, unrelated queries -- each with a unique prefix and no relationship to other requests -- traditional routing may be simpler and equally effective because there is no prefix to reuse. The llm-d project reports large gains for precise prefix-cache-aware scheduling in a benchmark built around shared-prefix workloads, including much faster repeated responses and roughly double throughput on identical hardware. But those numbers reflect workloads with high inherent prefix overlap. A workload without that characteristic would see much smaller gains.
Cache eviction pressure. GPU memory is finite, and all production implementations use eviction policies -- typically LRU -- to remove cached prefixes when memory is full. Under high traffic with many diverse prefixes, the eviction policy may remove cached entries before they can be reused. Cache hit rates drop, and the routing overhead provides no benefit. The symptom is a high eviction rate paired with a low cache hit rate -- the system is maintaining the index and making routing decisions, but the underlying cache is churning too fast to help.
Stale routing decisions. The router's prefix index may lag behind actual cache state on replicas. A cached prefix may be evicted between the routing decision and request arrival, causing an expected cache hit to become a miss. The request still processes correctly, just without the cache benefit. Prefix-aware routing is a best-effort optimization, not a guarantee -- but the expected value remains positive even when individual decisions are occasionally wrong.
Cold start after scaling. When a new replica is added through autoscaling, it has an empty KV cache. Prefix-aware routing will not route requests to it because there are no cached prefixes to match. Production systems handle this by falling back to least-loaded routing, which naturally directs traffic to the idle new replica.
The summary: prefix-aware routing is an optimization for high-prefix-overlap workloads, not a universal replacement for traditional load balancing. The best production systems treat it as a routing preference that can be overridden when load balance requires it.
What This Post Is Not
This post covered how the inference infrastructure routes requests to replicas based on KV cache prefix state: the problem with cache-blind routing, the sources of prefix overlap, the mechanism of prefix-aware routing, three production implementations, and the trade-offs involved.
It did not cover several related topics that belong elsewhere. Application-level prompt caching -- the developer-facing API feature where providers cache KV state for explicitly marked prompt prefixes -- is the subject of Main Post 07. That is above the API boundary: what the developer controls. This post operates below it: what the inference infrastructure does automatically. The two are complementary. KV cache memory management (PagedAttention, block tables) is the subject of I-02, assumed here as a foundation. KV cache transfer between prefill and decode pools in disaggregated architectures is the subject of I-03.
So far in this track, we have optimized how requests are batched (I-01), how KV cache memory is managed (I-02), how prefill and decode are separated (I-03), and how requests are routed to exploit cache locality (this post). But there is one more dimension. Everything so far has assumed that the model fits neatly on a single GPU or a small set of replicas. What if the model itself is too large for simple replication? What if it uses a mixture-of-experts architecture where different parts of the model activate for different inputs, requiring a fundamentally different sharding and routing strategy -- not at the request level, but at the token level within the model itself?
That is the subject of Post I-05: expert-parallel serving for mixture-of-experts models.
Source Notes
This post draws on the following primary and practitioner sources:
Zheng, L., Yin, L., Xie, Z., et al. "SGLang: Efficient Execution of Structured Language Model Programs." NeurIPS, 2024. Primary source for the RadixAttention mechanism, radix tree structure for KV cache management, LRU eviction policy, and throughput benchmarks (up to 5x-6.4x improvement). arxiv.org/abs/2312.07104
LMSYS. "Fast and Expressive LLM Inference with RadixAttention and SGLang." January 2024. Companion blog post with accessible visual examples of radix tree operations and prefix reuse patterns across multi-turn chat, few-shot learning, and structured generation. lmsys.org/blog/2024-01-17-sglang/
Kwon, W., Li, Z., Zhuang, S., et al. "Efficient Memory Management for Large Language Model Serving with PagedAttention." SOSP, 2023. Foundation for block-level KV cache sharing via copy-on-write and reference counting. Referenced as prerequisite from I-02. arxiv.org/abs/2309.06180
vLLM. "Automatic Prefix Caching." Official documentation of vLLM's hash-based prefix caching mechanism, including Merkle tree-like block hash chaining and automatic reuse of matching prefix blocks. docs.vllm.ai/en/stable/design/prefix_caching/
Ray Serve. "Prefix-aware routing." Official documentation of the PrefixCacheAffinityRouter, including multi-tier routing strategy,
imbalanced_thresholdandmatch_rate_thresholdconfiguration parameters, and fallback behavior. docs.ray.io/en/latest/serve/llm/user-guides/prefix-aware-routing.html
Anyscale. "Ray Serve: Reduce LLM Inference Latency by 60% with Custom Request Routing." Benchmark blog post reporting 60% TTFT reduction and >40% throughput improvement on DeepSeek-R1-Distill-Qwen-32B across 8 machines (64 GPUs), with >2.5x throughput for prefix-heavy workloads. anyscale.com/blog/ray-serve-faster-first-token-custom-routing
DualMap. "Enabling Both Cache Affinity and Load Balancing for Distributed LLM Serving." ICLR, 2026. Formalizes the cache-affinity versus load-balance tension using a dual-hash-ring scheduling strategy with SLO-aware switching. Up to 2.25x effective capacity improvement under TTFT constraints. arxiv.org/abs/2602.06502
llm-d project. "KV-Cache Wins You Can See: From Prefix Caching in vLLM to Distributed Scheduling with llm-d." Kubernetes-native prefix-aware routing framework. Reports benchmark gains for precise prefix-cache-aware scheduling, including 57x faster repeated responses and roughly double throughput in a shared-prefix Qwen/Qwen-32B setup. llm-d.ai/blog/kvcache-wins-you-can-see
NVIDIA. "Mastering LLM Techniques: Inference Optimization." NVIDIA Developer Blog. General inference optimization context including prefill/decode distinction and KV cache role. developer.nvidia.com/blog/mastering-llm-techniques-inference-optimization
Huang Tzu Lin
With over five years in autonomous robotics, there's a strong passion for incorporating cutting-edge technologies and innovative approaches. Dedicated to transforming the latest research and insights into practical applications, this journey pushes the limits of possibility.
Related Posts
Stay Updated
Get the latest technical insights delivered to your inbox.