Reliable LLM Pipelines and Control Logic
Reading order
Building AI Systems
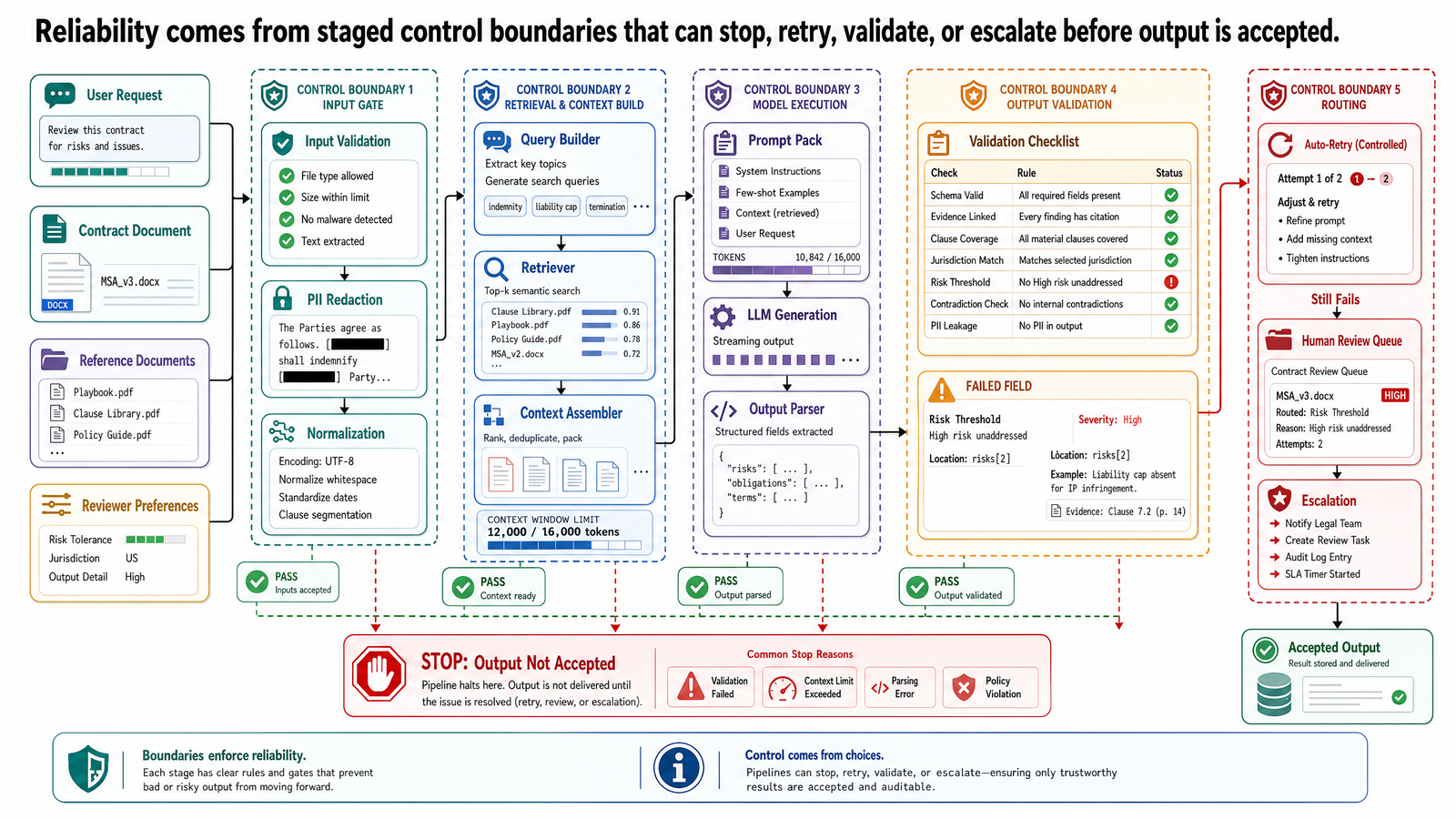
Table of Contents
- A Reliable Pipeline Has Stages and Decision Boundaries
- 1. Ingestion
- 2. Extraction
- 3. Normalization
- 4. Validation
- 5. Comparison and Synthesis
- 6. Final Formatting and Delivery
- Why Prompt-Only Orchestration Breaks Down
- Control Logic Is the Reliability Layer
- Structured Outputs Help, but They Do Not Eliminate Validation
- Tool Schemas and Handoff Boundaries Need To Be Explicit
- Deterministic Steps Usually Win More Often Than Teams Expect
- Running Example: A Contract-Ingestion Workflow
- Common Operational Failure Modes
- Practical Design Guidance
- What This Post Is Not
- The Bridge to Retrieval and Grounding
- Source Notes
Useful AI systems usually fail for ordinary software reasons before they fail for exotic model reasons. A prototype looks impressive when a single prompt produces a plausible answer, but production systems do not consume plausibility. They consume records, decisions, and actions that need to be routed, validated, retried, stored, or rejected.
This post starts where Post 1 ended. Once you accept that useful AI products are compound systems, the next question is how those systems are structured for reliability. If an LLM system must extract fields from a hotel contract, normalize currencies and dates, decide whether availability constraints are satisfied, and generate a comparison sheet that other software or people will trust, then the main design question is not "How do we write a better prompt?" It is "What are the stages, what is allowed to happen at each stage, and what checks decide what happens next?"
This is where control logic enters. In a reliable LLM application, the model is one component inside a larger workflow. The workflow decides when the model is called, what inputs it receives, what shape the output must follow, what validators must pass, when to retry, when to stop, and when to hand off to a human or an exception queue. Reliability comes from that decomposition.
This post makes that architecture concrete. We will use a running example of an OptiVerse Travel copilot for a mid-size travel agency ingesting a hotel partner contract, extracting the seasonal rate table, normalizing currencies and dates, validating accessible room availability against requested dates, and then producing a formatted comparison sheet. The key point is simple: the comparison sheet is only as trustworthy as the pipeline that produced it.
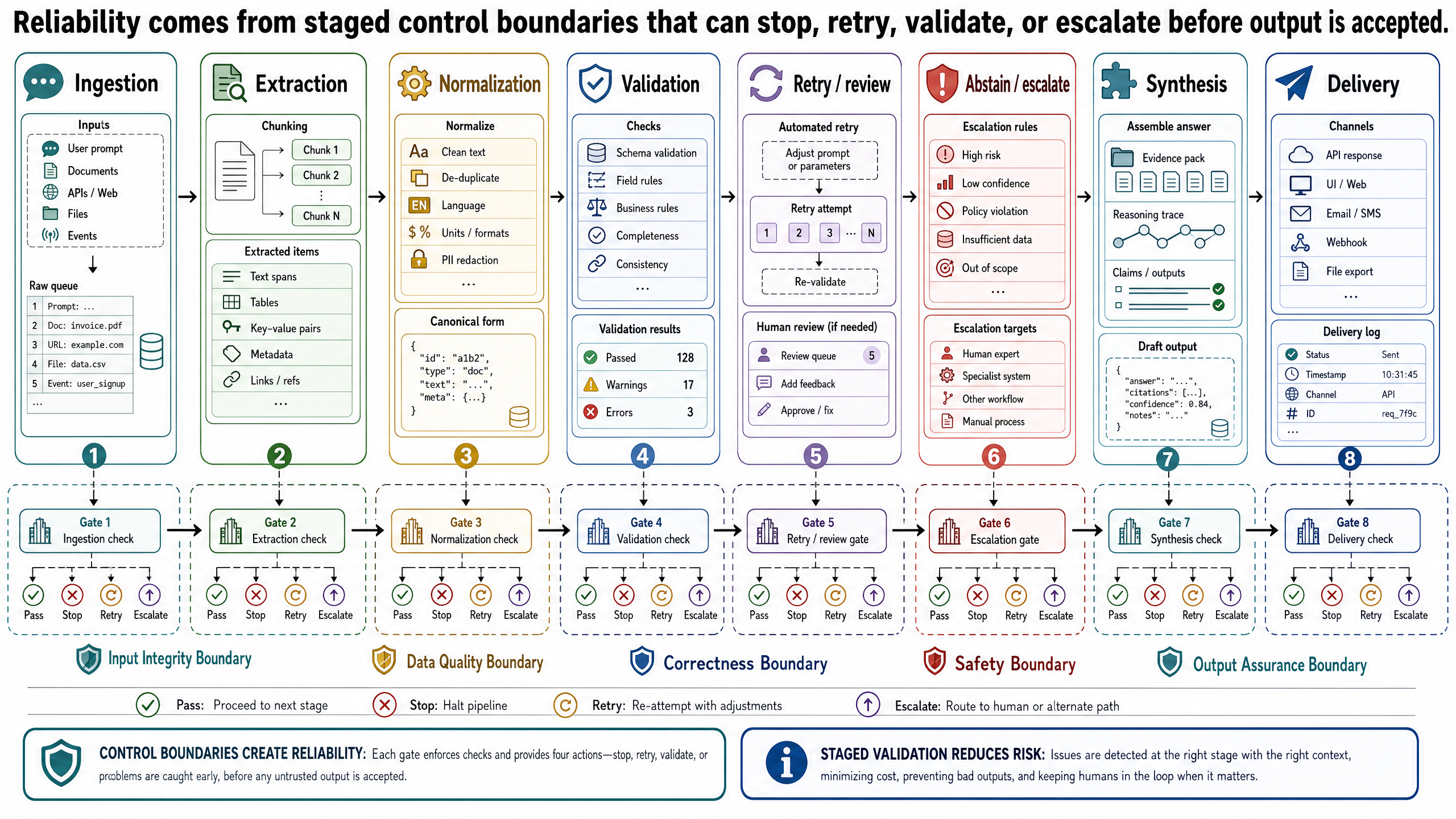
A Reliable Pipeline Has Stages and Decision Boundaries
The easiest way to make control logic concrete is to define the pipeline stages and the decision boundaries between them. For the OptiVerse Travel copilot, consider the task: ingest hotel partner contract KYO-H12 and produce a rate-and-availability comparison for a 10-day accessible Japan trip (booking reference JPN-2026-0417).
That task can be decomposed into six stages.
1. Ingestion
The system receives the contract PDF and basic metadata such as source, upload time, and document identifier. At this stage, the goal is not understanding. The goal is making the document available to later stages in a controlled way.
Typical outputs:
document ID (e.g., KYO-H12)
source metadata (partner name, contract effective dates)
file type and checksum
processing status
Decision boundary:
If the file is unreadable, duplicated, or missing required metadata, stop here and route to an exception path. Do not continue into extraction with a broken input package.
2. Extraction
The system extracts the seasonal rate table, room-type descriptions, accessibility annotations, meal-plan options, and cancellation terms from the contract. Some of this may be done with deterministic parsers; some may require model assistance if the layout is irregular or the extraction target is semantically defined.
Typical outputs:
raw extracted text blocks
table candidates (rate grids, room inventories)
clause references (e.g., Clause 4.3 — seasonal rate table with accessible room allocation)
candidate fields such as room types, nightly rates, seasonal date ranges, meal-plan inclusions, and accessible room counts
Decision boundary:
The system checks whether extraction produced the minimum evidence needed for the task. If the contract has no recoverable rate table or the accessibility sections are missing, the workflow should not silently continue as if the record were complete.
3. Normalization
Raw extractions are not yet system-ready. Rates may appear in different currencies. Date ranges may use inconsistent formats. Room-type labels may use aliases that differ across partner contracts. Normalization converts extracted values into the canonical forms the rest of the system expects.
Typical outputs:
normalized currency (all rates converted to USD at a reference exchange rate)
canonical date format (ISO 8601)
standardized room-type names
explicit nulls for unresolved fields
Decision boundary:
Normalization must be able to say "unresolved" rather than force a guess. If the contract states one rate in a footnote and another in the main table body, that is not a formatting issue. It is a conflict the system needs to surface.
4. Validation
Validation checks whether the normalized record is acceptable for downstream use. This is where schema constraints, confidence thresholds, and business rules work together.
Typical checks:
required fields exist (room type, nightly rate, seasonal dates, accessibility flag)
numeric ranges are plausible (a nightly rate of $5 or $50,000 should trigger review)
currencies match the canonical schema
provenance links point back to a source clause, table cell, or contract section
contradictory values are flagged (e.g., accessible room listed as available but count is zero)
Decision boundary:
Only validated records proceed to comparison. Records that fail validation go to retry, repair, or human review depending on the failure type.
5. Comparison and Synthesis
Now the model is asked to do what it is good at: compose a concise rate-and-availability comparison from a cleaned and validated evidence packet. The synthesis model should not be forced to recover from upstream ambiguity that the pipeline already detected.
Typical outputs:
rate comparison table across room types and seasons matching the requested travel dates
accessible room availability statement for the requested 10-day window
budget fit assessment against the $13K–$15K family budget
references back to the extracted evidence packet
Decision boundary:
If the model cannot produce the comparison without inventing unsupported assumptions about availability or pricing, the system should abstain or produce a partial answer with explicit gaps.
6. Final Formatting and Delivery
The final stage prepares the result for its destination: agent dashboard, client proposal, or booking system. Formatting is not cosmetic. It is where the system decides what metadata, warnings, and evidence links travel with the output.
Typical outputs:
rendered comparison sheet
linked evidence (contract clauses, rate table sources)
processing log
final status
Decision boundary:
If the output channel requires provenance or approval status, the delivery step must enforce that requirement instead of assuming it was handled upstream.
Why Prompt-Only Orchestration Breaks Down
Prompt-only orchestration is the habit of pushing more workflow responsibility into one model call instead of designing explicit stages around the model. It often sounds efficient: ask the model to read the contract, extract the rates, normalize currencies, decide whether the room availability is sufficient, call tools if needed, and write the comparison in one pass.
That can work for a demo. It is fragile for a system.
The failure is not just that models sometimes hallucinate. The deeper issue is that downstream requirements are usually sharper than natural language. A parser expects a field to exist. A routing step expects one of a small set of statuses. A validator expects currencies to be normalized into one standard. A review queue expects confidence and provenance metadata. A compliance or audit process expects the system to show where a rate or availability figure came from. Prompt-only orchestration blurs those boundaries.
Once boundaries blur, failures become harder to see and harder to contain. A model may return valid-looking JSON with the wrong currency conversion. It may produce a plausible room-type label that does not match the agency's canonical naming system. It may omit a required field and compensate with fluent prose. It may combine extraction and interpretation so tightly that the system cannot tell whether the error came from contract parsing, normalization, or synthesis.
This is why stronger prompting is not the same thing as better architecture. Prompt quality matters, but it does not replace explicit workflow design. When the task has multiple transformations with different correctness criteria, the safer pattern is to separate those transformations and check each one.
Control Logic Is the Reliability Layer
Control logic is the set of rules that decides what happens next in the system. In a traditional software pipeline, those rules are written directly in code. In an LLM system, some decisions may still be deterministic and some may be delegated to a model, but the application still owns the workflow.
That ownership matters. Tool use does not remove control logic from the application. A model can propose a tool call or produce structured data for one, but the application decides which tools are exposed, what schema the arguments must follow, whether the arguments are acceptable, whether the tool result should trigger another step, and what happens when the result is missing or inconsistent.
In practice, control logic answers questions like these:
Has the contract been parsed well enough to continue?
Which extraction path should run for this document layout?
Are the required fields present?
Did currency normalization succeed without ambiguity?
Is the record safe to pass into a comparison step?
Should the system retry, abstain, or route to human review?
These are normal systems questions. The model helps answer some of them, but it does not erase them.
Structured Outputs Help, but They Do Not Eliminate Validation
Many teams improve reliability by requiring the model to return structured output that conforms to a schema. This is a good pattern. It narrows the output shape, makes downstream parsing more robust, and forces the application to define what fields it actually needs.
But schema adherence is not the same thing as correctness.
A model can produce a schema-valid record that is still semantically wrong. It can fill a required field with the wrong value. It can confuse two nearby rate entries. It can assign the right type to the wrong room category. It can mark a field as complete when the evidence was weak or ambiguous.
This is why structured outputs and validators serve different purposes.
A schema answers: "Is the output in the right shape?"
A validator answers: "Is the output acceptable for this workflow?"
Those are not interchangeable questions.
Consider a record with fields for room_type, nightly_rate_usd, accessibility_flag, and source_clause. A schema can ensure that nightly_rate_usd is numeric and that source_clause is present. It cannot by itself determine whether the cited clause really supports the extracted rate, whether the currency was converted correctly, or whether the room-type label matches the agency's canonical naming system.
In production, validation usually combines three layers:
Structural validation checks type, required fields, enums, and shape.
Semantic validation checks plausibility, consistency, and field relationships.
Business-rule validation checks whether the record is acceptable for the organization's actual process.
That last layer matters more than many prototype builders expect. A travel-agency workflow may require that every extracted rate be linked to a specific contract clause and date range, not just to free text. That is not a language problem. It is a workflow contract.
Tool Schemas and Handoff Boundaries Need To Be Explicit
Reliable systems also depend on explicit handoff boundaries between the model and the rest of the application. If the model is allowed to invoke tools, then the tool interface is part of the reliability story.
A good tool schema does two things. It constrains what the model is allowed to ask for, and it makes the application-side contract testable. If a model can call normalize_currency, lookup_room_type_alias, or fetch_prior_bookings, each tool should expose a narrow, typed interface with clear failure behavior.
For example, a currency-normalization tool should not accept vague free-form instructions if the application needs exact conversions. It should accept a defined value, source currency, and target currency, and it should return either a normalized result or an explicit error state. If the model passes malformed arguments, the application should reject the call rather than guess.
This boundary is where many teams discover that "the model can call tools" is not a design in itself. The design lives in the schemas, the argument checks, the retry policy, the fallback path, and the decision about whether a tool failure is recoverable or terminal.
The same logic applies to handoffs between stages. Each stage should produce an output contract that the next stage can inspect without reinterpreting the whole history. That reduces hidden state and makes failures local. If the comparison step has to infer whether normalization succeeded by reading a long conversational trace, the system has already lost important control.
Deterministic Steps Usually Win More Often Than Teams Expect
There is a temptation to make the model responsible for every transformation because it seems more flexible. In practice, many high-value workflow steps are better handled deterministically once the problem is understood.
Use deterministic logic when:
the operation has a clear rule
the acceptable outputs are narrow
errors are easy to define
reproducibility matters more than flexibility
Examples include file-type routing, currency conversion, date-format standardization, enum mapping, duplicate detection, threshold checks, and destination-specific formatting.
Use model-directed logic when:
the input is messy or weakly structured
the task depends on semantic interpretation
the acceptable outputs are not fully enumerable
the model adds compression or synthesis value
Examples include extracting rate tables from irregular contract layouts, linking footnotes to surrounding clauses, or drafting a readable comparison from a validated evidence packet.
This distinction is not ideological. It is operational. Overusing the model creates avoidable latency, cost, and failure surface. Underusing the model can make messy tasks brittle. A reliable architecture allocates each step to the mechanism that fits the step.
Running Example: A Contract-Ingestion Workflow
To make the architecture tangible, imagine the OptiVerse Travel team uploads hotel partner contract KYO-H12 to prepare a rate comparison for booking reference JPN-2026-0417 — a 10-day accessible Japan trip during cherry blossom season for a family of four with a wheelchair user, budgeted at $13K–$15K.
An unreliable version of the system might send the contract text and a long instruction to the model:
"Read this contract, extract the seasonal rates and accessible room availability, convert currencies to USD, identify the most relevant options for the requested dates, and write a comparison summary."
If the output looks reasonable, the prototype appears successful. But the workflow has hidden too many decisions in one place:
Did extraction miss the relevant rate table in Clause 4.3?
Did the model convert yen to dollars correctly?
Did it confuse a standard room allocation with an accessible room allocation?
Did it omit blackout dates or minimum-stay requirements?
Can anyone inspect what was actually used?
A more reliable version makes the stages inspectable.
First, the system parses the contract PDF and extracts candidate tables, clauses, and sections. Next, it runs field extraction for a bounded set of targets: room type, nightly rate, currency, seasonal date range, accessible room count, meal-plan options, and source clause references. Then it normalizes currencies and date formats. Then it validates required fields and consistency. Only after that does it ask the model to produce the comparison sheet, using the validated record as the source package.
This version is less magical and more useful. If a rate entry is missing provenance, the workflow can stop before comparison. If normalization finds conflicting currencies or date ranges, the record can be flagged for review. If the comparison step fails, the structured extraction still remains available for inspection or reprocessing.
That is what reliability looks like in an LLM pipeline: not perfect outputs, but bounded failure and legible state.
Common Operational Failure Modes
Production failures usually come from mundane mismatches between stage assumptions.
One common failure is malformed structured output. Even when the model is instructed to follow a schema, the application still needs error handling for incomplete, truncated, or rejected generations.
Another is semantic drift inside valid structure. A field may be present and well typed but still represent the wrong thing. These errors are easy to miss because the pipeline appears healthy.
A third is silent corruption from partially valid records. If the system lets comparison proceed when one critical field failed normalization, the final answer may read as confident even though the evidence packet was incomplete.
Routing errors matter too. A workflow may send a low-confidence extraction to the normal comparison path instead of a repair queue. That kind of control-logic mistake can make a system look like it has a model problem when the real issue is stage policy.
Latency blowups are another operational failure. If the application calls the model repeatedly for tasks that could be deterministic, cost and response time increase without improving reliability.
Finally, exception handling is often underdesigned. Teams define the happy path and assume rare failures can be patched later. In practice, exception paths are part of the architecture from the beginning because every extraction pipeline eventually encounters unreadable files, conflicting fields, unsupported layouts, and ambiguous contract language.
Practical Design Guidance
Start with the reliability target, not the feature list. Ask what must be correct enough for the workflow to be useful and what kinds of failure are acceptable.
Decompose tasks by transformation type. Extraction, normalization, validation, comparison, and delivery usually have different error modes and should not be collapsed without a reason.
Define output contracts for every stage. A stage should produce something the next stage can inspect directly, including failure states.
Use schemas for model outputs, but treat them as input to validation rather than the final guarantee.
Keep tool interfaces narrow. If a tool matters operationally, give it a typed schema, explicit error behavior, and application-side checks.
Design exception paths early. Decide when to retry, when to abstain, when to surface uncertainty, and when to hand off to a human reviewer.
Measure where cost and latency actually go. Reliable systems often improve by removing unnecessary model calls, not by adding larger ones.
Most importantly, preserve evidence across handoffs. A polished comparison sheet should always be traceable back to the record that produced it.
What This Post Is Not
This is not an argument that every AI system should be a rigid deterministic pipeline. Some tasks do require more open-ended model control, and later posts in this series will cover retrieval, memory, and agent loops.
It is also not an argument that structured outputs solve reliability by themselves. They improve one boundary. They do not replace validation, monitoring, or workflow design.
The central point is narrower and more practical: before you ask whether your system needs an agent, ask whether the underlying pipeline has clear stages, explicit schemas, validation rules, and controlled handoffs. If it does not, adding more autonomy usually increases failure surface faster than it increases capability.
The Bridge to Retrieval and Grounding
A well-structured pipeline still has one major limitation: it can only be as informed as the evidence packet it receives. If the system must answer questions that depend on external partner contracts, internal booking histories, accessibility databases, or prior client itineraries, then reliability also depends on how the right evidence is found and attached to the workflow.
That is where retrieval enters. The next post moves from internal pipeline control to grounding: how a system retrieves the right context, preserves provenance, and knows when it should abstain instead of guessing. Control logic and validation do not disappear there. They become even more important, because retrieval adds another stage where bad inputs can quietly degrade the final answer.
Source Notes
This post draws on the following primary and official sources:
BAIR. "The Shift from Models to Compound AI Systems." Reference for control logic as a core design choice in compound AI systems. bair.berkeley.edu/blog/2024/02/18/compound-ai-systems
OpenAI. "Function calling." Official reference for tool calling as a structured interaction between model output and application-side code. developers.openai.com/api/docs/guides/function-calling
OpenAI. "Structured model outputs." Official reference for schema-constrained outputs; used here with the caveat that schema adherence does not guarantee semantic correctness. developers.openai.com/api/docs/guides/structured-outputs
National Institute of Standards and Technology. "Artificial Intelligence Risk Management Framework: Generative Artificial Intelligence Profile." Reference for risk controls, evaluation, monitoring, provenance, and trustworthy deployment framing. nist.gov/publications/artificial-intelligence-risk-management-framework-generative-artificial-intelligence
Huang Tzu Lin
With over five years in autonomous robotics, there's a strong passion for incorporating cutting-edge technologies and innovative approaches. Dedicated to transforming the latest research and insights into practical applications, this journey pushes the limits of possibility.
Related Posts
Stay Updated
Get the latest technical insights delivered to your inbox.