可靠的 LLM 流程與控制邏輯
閱讀順序
Building AI Systems
有用的 AI 系統往往還沒遇到什麼奇特的模型問題,就先因為普通的軟體原因出狀況了。原型階段看起來很厲害——一個提示就能產生看似合理的答案。但正式系統面對的不是合理性,而是一筆筆需要路由、驗證(validation)、重試、儲存或拒絕的記錄、決策和動作。
這篇接續第一篇的結尾。一旦你接受有用的 AI 產品是複合式系統(compound system),接下來的問題就是:這些系統要怎麼建才會可靠?假設一個 LLM 系統必須從飯店合約中擷取欄位、正規化貨幣和日期、判斷空房條件是否滿足,然後產生一份其他軟體或人員會信任的比較表。核心的設計問題不是「怎麼寫出更好的提示?」而是「有哪些階段、每個階段允許什麼操作、哪些檢查決定接下來怎麼走?」
這就是控制邏輯(control logic)的角色。在可靠的 LLM 應用裡,模型是更大工作流程中的一個組件。工作流程決定何時呼叫模型、模型接收什麼輸入、輸出必須符合什麼形狀、哪些驗證器必須通過、何時重試、何時停止,以及何時交給人工處理或送入例外佇列。可靠性就是從這種分解來的。
這篇會讓這個架構變得具體。我們用一個貫穿全文的例子來說明:OptiVerse Travel 旅遊 Copilot 為一家中型旅行社接收飯店合作夥伴合約、擷取季節性費率表、正規化貨幣和日期、根據要求的日期驗證無障礙房間的空房狀況,然後產生一份格式化的比較表。關鍵要點很簡單:比較表的可信度取決於產生它的流程(pipeline)。
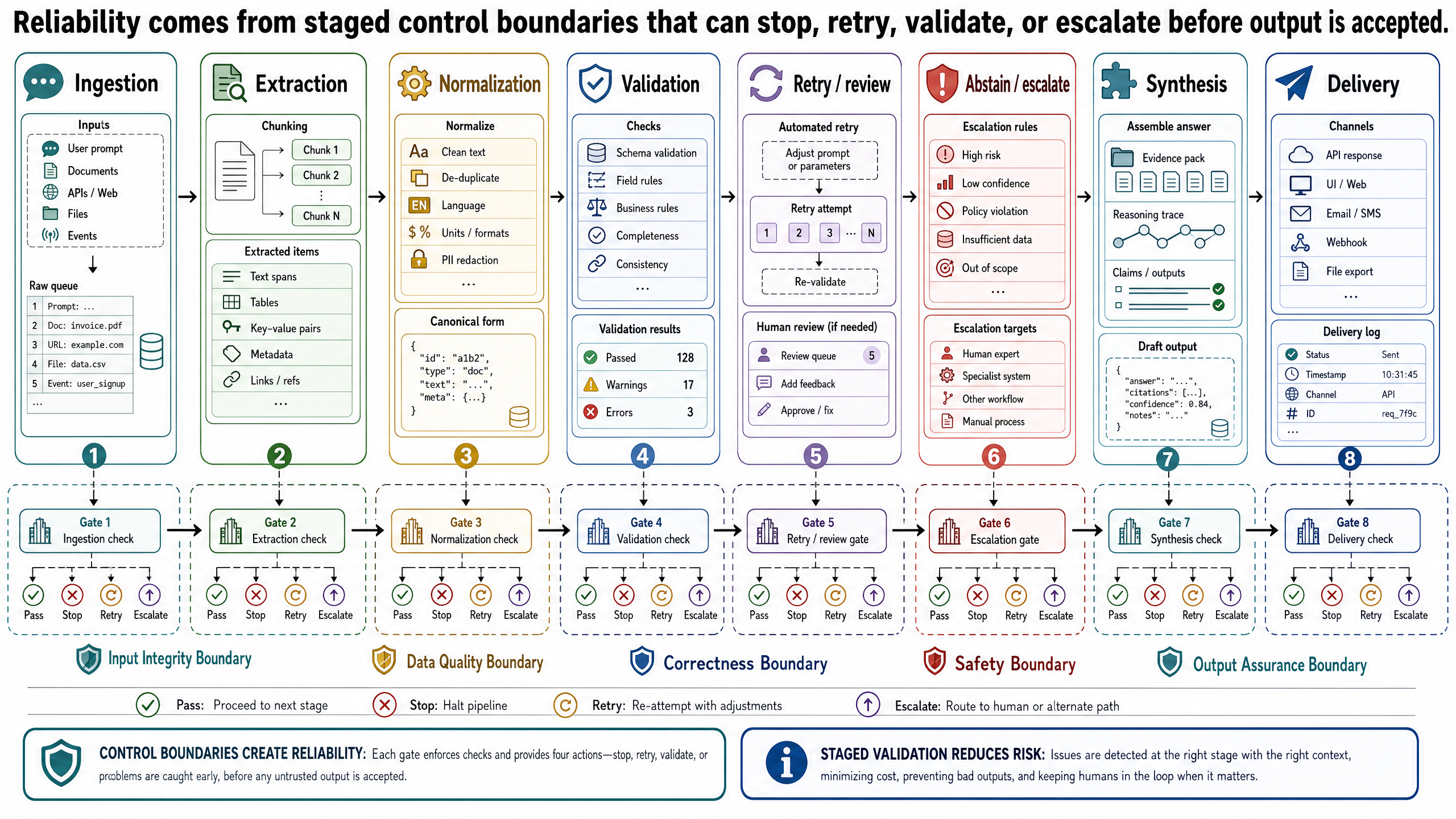
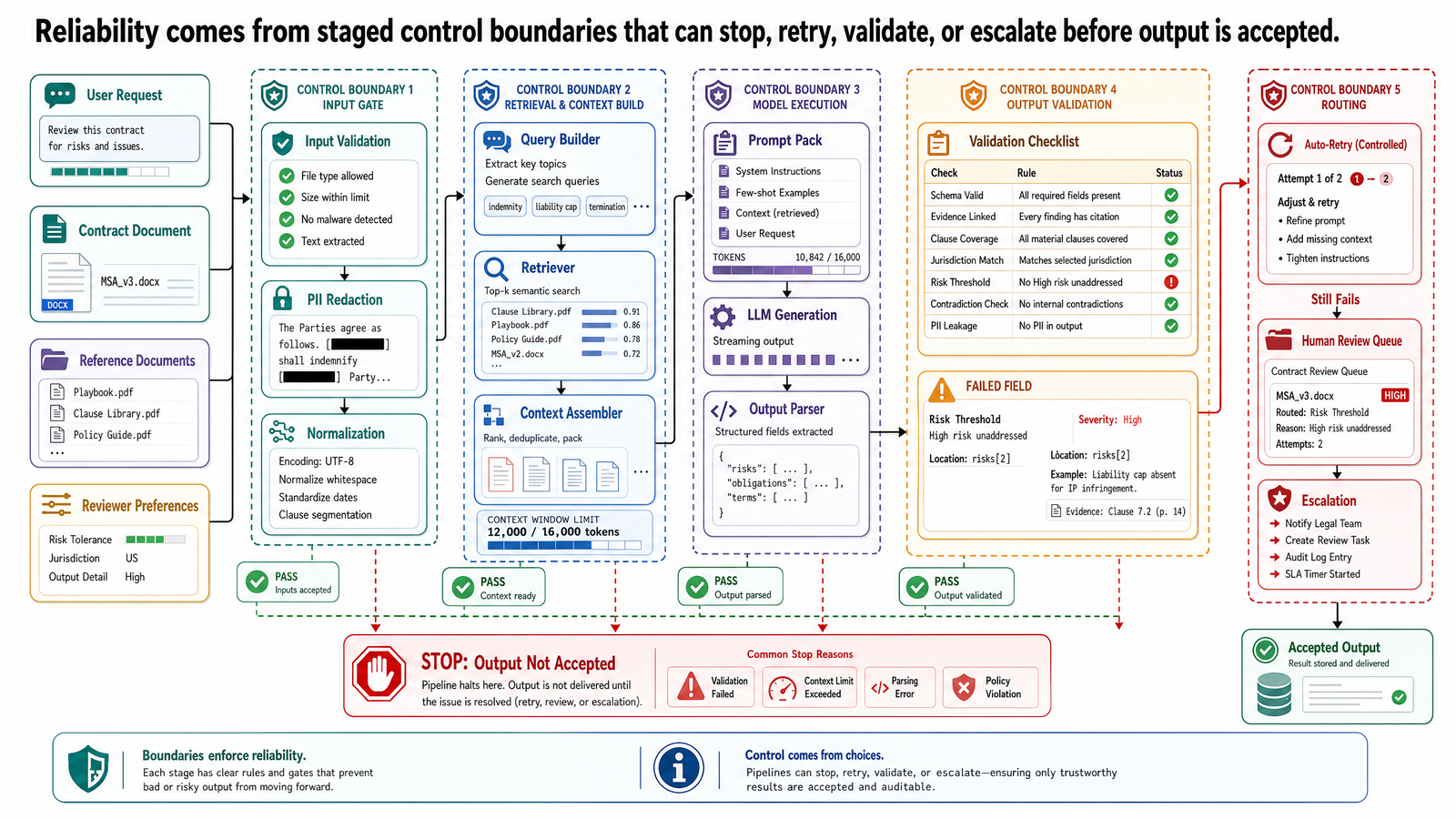
可靠的流程具有階段和決策邊界
要讓控制邏輯變得具體,最簡單的方式就是定義流程的階段以及階段之間的決策邊界。以 OptiVerse Travel 旅遊 Copilot 為例,考慮這個任務:接收飯店合作夥伴合約 KYO-H12,並為訂單參考 JPN-2026-0417 產生一份費率與空房比較表——一趟在櫻花季期間為四口之家(含一位輪椅使用者)規劃的十天無障礙日本行程,預算為 13,000 至 15,000 美元。
這個任務可以分解為六個階段。
1. Ingestion
系統接收合約 PDF 和基本元資料,例如來源、上傳時間和文件識別碼。這個階段的目標不是理解內容,而是用受控的方式讓文件可供後續階段使用。
典型輸出:
文件 ID(例如 KYO-H12)
來源元資料(合作夥伴名稱、合約生效日期)
檔案類型和校驗碼
處理狀態
決策邊界:
如果檔案無法讀取、重複,或缺少必要的元資料,就在此停止並導向例外路徑。不要帶著有問題的輸入繼續進入擷取階段。
2. Extraction
系統從合約中擷取季節性費率表、房型描述、無障礙註記、餐食方案選項和取消條款。有些可以用確定性解析器完成;如果版面不規則、或擷取目標本身是語義性的,就可能需要模型協助。
典型輸出:
原始擷取的文字區塊
候選表格(費率表格、房間庫存)
條款參照(例如 Clause 4.3——含無障礙房間配額的季節性費率表)
候選欄位,例如房型、每晚費率、季節日期範圍、餐食方案包含項目和無障礙房間數量
決策邊界:
系統需檢查擷取結果是否達到任務所需的最低佐證門檻。如果合約中找不到可用的費率表,或無障礙區段缺失,工作流程不應默默繼續,當作記錄是完整的。
3. Normalization
原始擷取結果還不能直接拿來用。費率可能用不同貨幣表示,日期範圍的格式可能不一致,房型標籤在不同合作夥伴合約中可能用不同的別名。正規化就是把擷取的值轉換成系統其餘部分預期的標準形式。
典型輸出:
正規化的貨幣(所有費率按參考匯率轉換為美元)
標準日期格式(ISO 8601)
標準化的房型名稱
未解析欄位的明確空值
決策邊界:
正規化必須能回報「未解析」,而不是強行猜測。如果合約在腳註列了一個費率、在主表格又列了另一個費率,那不是格式問題——那是系統需要浮上來的衝突。
4. Validation
驗證是檢查正規化後的記錄能否被下游使用。這是 schema 約束、信心門檻和商業規則共同發揮作用的環節。
典型檢查:
必填欄位存在(房型、每晚費率、季節日期、無障礙標記)
數值範圍合理(每晚費率 5 美元或 50,000 美元應觸發審查)
貨幣符合標準 schema
來源追溯連結指向特定的來源條款、表格儲存格或合約區段
矛盾值被標記(例如無障礙房間列為可用但數量為零)
決策邊界:
只有通過驗證的記錄才能進入比較階段。未通過的記錄根據失敗類型被導向重試、修復或人工審查。
5. Comparison and Synthesis
到了這一步才要求模型做它擅長的事:從清理過、經過驗證的佐證包中,撰寫一份簡潔的費率與空房比較。負責綜合的模型不應被迫去處理流程已經偵測到的上游模糊問題。
典型輸出:
跨房型和季節的費率比較表,匹配所請求的旅行日期
所請求十天期間的無障礙房間空房聲明
對照 13,000 至 15,000 美元家庭預算的預算契合度評估
回溯至擷取佐證包的參照
決策邊界:
如果模型無法在不捏造空房或定價假設的前提下產生比較,系統應選擇拒答,或產生帶有明確缺口的部分答案。
6. Final Formatting and Delivery
最後階段是為結果的目的地做準備:客服人員儀表板、客戶提案或訂房系統。格式化不是裝飾——這是系統決定哪些元資料、警告和佐證連結要隨輸出一起送出的環節。
典型輸出:
渲染後的比較表
連結的佐證(合約條款、費率表來源)
處理日誌
最終狀態
決策邊界:
如果輸出通道要求來源追溯或核准狀態,交付步驟就必須強制執行,不能假設上游已經處理好了。
為何「僅靠提示」的編排會瓦解
僅靠提示的編排是一種常見的壞習慣——把越來越多的工作流程責任壓進單一模型呼叫裡,而不是圍繞模型設計明確的階段。聽起來很高效:讓模型一次讀完合約、擷取費率、正規化貨幣、判斷房間空房是否充足、需要時呼叫工具,然後寫出比較。
Demo 可以過關,但對系統來說是脆弱的。
問題不只在於模型有時會產生幻覺。更深層的問題在於,下游需求通常比自然語言嚴格得多。解析器預期欄位要存在。路由步驟預期收到有限幾種狀態之一。驗證器預期貨幣已經被正規化為單一標準。審查佇列預期有信心度和來源追溯元資料。合規或稽核流程預期系統能展示費率或空房數字的來源。僅靠提示的編排把所有這些邊界都模糊掉了。
一旦邊界模糊了,失敗就更難察覺、更難控制。模型可能回傳看起來有效的 JSON,但貨幣轉換是錯的。它可能產生一個看似合理的房型標籤,卻不符合旅行社的標準命名。它可能漏掉必填欄位,然後用流暢的文字來補。它可能把擷取和解讀耦合得太緊,讓系統根本分不清錯誤來自合約解析、正規化還是綜合。
簡單來說,更強的提示不等於更好的架構。提示品質很重要,但取代不了明確的工作流程設計。當任務涉及多種轉換、而且各有不同的正確性標準時,更安全的做法是把這些轉換分開,逐一檢查。
控制邏輯是可靠性層
控制邏輯就是一組規則,決定系統接下來該做什麼。在傳統軟體流程中,這些規則直接寫在程式碼裡。在 LLM 系統中,有些決策可能仍然是確定性的,有些可能交給模型,但應用程式仍然掌握工作流程的主導權。
這種主導權很重要。使用了工具不代表控制邏輯就從應用程式消失了。模型可以提議工具呼叫,或為工具呼叫產生結構化資料,但應用程式決定哪些工具被暴露、引數必須符合什麼 schema、引數是否可接受、工具結果是否該觸發另一步驟,以及結果缺失或不一致時該怎麼處理。
實務上,控制邏輯回答的是這些問題:
合約是否已被充分解析以繼續?
針對此文件版面,應走哪條擷取路徑?
必填欄位是否存在?
貨幣正規化是否在沒有歧義的情況下成功?
記錄是否安全到可以傳入比較步驟?
系統應重試、拒答,還是導向人工審查?
這些都是正常的系統問題。模型可以幫忙回答其中一些,但它們不會因此消失。
結構化輸出有幫助,但消除不了驗證的需要
許多團隊會透過要求模型回傳符合 schema 的結構化輸出來提升可靠性。這是好的做法。它限縮了輸出的形狀、讓下游解析更穩健,也迫使應用程式定義它到底需要哪些欄位。
不過,符合 schema 不等於內容正確。
模型可以產生一筆符合 schema 的記錄,但語義上完全是錯的。它可以用錯的值填入必填欄位。它可以混淆兩個相鄰的費率條目。它可以把正確的類型指派給錯誤的房間類別。它也可以在佐證薄弱或模糊時,把欄位標記為完整。
這就是為什麼結構化輸出和驗證器各有各的用途:
Schema 回答:「輸出的形狀對不對?」
驗證器回答:「這個輸出對於此工作流程是否可接受?」
這兩個問題不能互換。
舉個例子:一筆記錄有 room_type、nightly_rate_usd、accessibility_flag 和 source_clause 欄位。Schema 可以確保 nightly_rate_usd 是數值型、source_clause 存在。但光靠 schema 判斷不了引用的條款是否真的支持所擷取的費率、貨幣是否正確轉換,或房型標籤是否符合旅行社的標準命名。
正式環境中,驗證通常結合三個層次:
結構驗證檢查類型、必填欄位、列舉和形狀。
語義驗證檢查合理性、一致性和欄位之間的關係。
商業規則驗證檢查記錄對於組織實際流程是否可接受。
最後一層的重要性,往往超出原型階段的預期。旅行社的工作流程可能要求每筆擷取的費率都連結到特定的合約條款和日期範圍,而不只是連結到一段自由文字。那不是語言問題,是工作流程的契約。
工具 schema 和交接邊界需要明確
可靠的系統也依賴模型與應用程式其餘部分之間清楚的交接邊界。如果模型被允許呼叫工具,那工具介面就是可靠性的一部分。
好的工具 schema 做到兩件事:它限制模型能要求什麼,也讓應用程式端的契約變得可測試。如果模型可以呼叫 normalize_currency、lookup_room_type_alias 或 fetch_prior_bookings,每個工具都應暴露一個窄小的、具型別的介面,並具有明確的失敗行為。
舉例來說,貨幣正規化工具在應用程式需要精確轉換時,不應接受模糊的自由格式指令。它應該接受已定義的數值、來源貨幣和目標貨幣,然後回傳正規化的結果或明確的錯誤狀態。如果模型傳入格式錯誤的引數,應用程式應該拒絕這次呼叫,而不是猜測意圖。
這個邊界正是許多團隊開始意識到「模型可以呼叫工具」本身不算設計的地方。真正的設計在 schema、引數檢查、重試策略、降級路徑,以及判定工具失敗是可恢復還是終結的決策裡面。
同樣的邏輯也適用於階段之間的交接。每個階段都應產生一份輸出契約,讓下一階段可以直接檢視,不必回頭重新詮釋整段歷史。這能減少隱藏狀態,也讓失敗局部化。如果比較步驟必須讀一大段對話追蹤才能推斷正規化是否成功,系統就已經失去了重要的控制。
確定性步驟往往比團隊預期的更常勝出
讓模型負責每一個轉換很誘人,因為看起來比較靈活。但實務上,一旦問題釐清了,許多高價值的工作流程步驟用確定性方式處理反而更好。
適合用確定性邏輯的情況:
操作有明確的規則
可接受的輸出範圍很窄
錯誤易於定義
可重現性比靈活性更重要
範例包括檔案類型路由、貨幣轉換、日期格式標準化、列舉映射、重複偵測、門檻檢查和目的地特定的格式化。
適合用模型導向邏輯的情況:
輸入混亂或結構薄弱
任務依賴語義解讀
可接受的輸出無法完全列舉
模型增加了壓縮或綜合的價值
範例包括從不規則的合約版面中擷取費率表、將腳註連結到周圍條款,或從經過驗證的佐證包起草可讀的比較。
這個區分不是意識形態問題,是實務操作的問題。過度使用模型會產生可避免的延遲、成本和失敗面。模型用得不夠則可能讓混亂的任務變得脆弱。可靠的架構會把每個步驟分配給最適合的機制。
實例演練:合約接收工作流程
為了讓架構更具體,假設 OptiVerse Travel 團隊上傳飯店合作夥伴合約 KYO-H12,準備訂單參考 JPN-2026-0417 的費率比較——一趟在櫻花季期間為四口之家(含一位輪椅使用者)規劃的十天無障礙日本行程,預算為 13,000 至 15,000 美元。
一個不可靠的版本可能把合約文字和一段冗長的指令直接送給模型:
「讀取此合約,擷取季節性費率和無障礙房間空房狀況,將貨幣轉換為美元,找出對所請求日期最相關的選項,並撰寫一份比較摘要。」
如果輸出看起來合理,原型就算過關了。但這個工作流程把太多決策集中在一個地方:
擷取是否遺漏了 Clause 4.3 中的相關費率表?
模型是否正確地將日圓轉換為美元?
它是否混淆了標準房配額和無障礙房配額?
它是否遺漏了禁止入住日期或最低住宿天數要求?
有人能檢視實際使用了什麼嗎?
更可靠的版本會讓各階段可檢視。
先由系統解析合約 PDF 並擷取候選表格、條款和區段。接著,針對一組有限的目標執行欄位擷取:房型、每晚費率、貨幣、季節日期範圍、無障礙房間數量、餐食方案選項和來源條款參照。然後正規化貨幣和日期格式。再來驗證必填欄位和一致性。只有在所有這些步驟完成之後,才要求模型用經過驗證的記錄作為來源包來產生比較表。
這個版本沒那麼炫,但更有用。如果一個費率條目缺少來源追溯,工作流程可以在比較之前就停下來。如果正規化發現貨幣或日期範圍有衝突,記錄可以被標記為待審查。如果比較步驟失敗了,結構化的擷取結果仍然可供檢視或重新處理。
這就是 LLM 流程中的可靠性:不是完美的輸出,而是有限的失敗和清晰的狀態。
常見的營運失敗模式
正式環境中的失敗通常來自各階段之間很普通的假設不匹配。
第一種常見失敗是格式錯誤的結構化輸出。即使模型被指示遵循 schema,應用程式仍然需要對不完整、截斷或被拒絕的生成結果做錯誤處理。
第二種是有效結構中的語義漂移。欄位可能存在、類型也正確,但代表的意思是錯的。這類錯誤特別容易被忽略,因為流程表面上看起來一切正常。
第三種是部分有效記錄造成的靜默損壞。如果系統在某個關鍵欄位正規化失敗時仍然讓比較繼續,最終答案可能讀起來很有信心,但佐證包其實不完整。
路由錯誤也值得注意。工作流程可能把低信心度的擷取送進正常的比較路徑,而不是導向修復佇列。這種控制邏輯的錯誤會讓人以為是模型出了問題,但真正的問題出在階段策略。
延遲暴增是另一個營運問題。如果應用程式對本來可以用確定性方式處理的任務反覆呼叫模型,成本和回應時間就會增加,但可靠性不會提升。
最後,例外處理往往設計不足。團隊定義了正常路徑,就以為罕見的失敗之後再補就好。但實務上,例外路徑從一開始就是架構的一部分。每個擷取流程遲早都會遇到讀不了的檔案、衝突的欄位、不支援的版面和模糊的合約語言。
實務設計指引
從可靠性目標開始,不是功能清單。先問:什麼東西必須夠正確,工作流程才有用?什麼樣的失敗是可以接受的?
按轉換類型分解任務。擷取、正規化、驗證、比較和交付通常有不同的錯誤模式,沒有充分理由不該合併。
為每個階段定義輸出契約。一個階段應該產生下一階段可以直接檢視的東西,包括失敗狀態。
對模型輸出使用 schema,但把它視為驗證的輸入而非最終保證。
保持工具介面窄小。如果一個工具在營運上很重要,就賦予它一個具型別的 schema、明確的錯誤行為和應用程式端的檢查。
及早設計例外路徑。決定何時重試、何時拒答、何時浮現不確定性,以及何時交由人工審查者處理。
衡量成本和延遲到底花在哪裡。可靠的系統通常是靠移除不必要的模型呼叫來改善,而不是靠增加更大的呼叫。
最重要的是,在交接中保留佐證。一份精心製作的比較表應始終可追溯回產生它的記錄。
本文不涵蓋的內容
本文不是在論證每個 AI 系統都該是一個剛性的確定性流程。有些任務確實需要更開放的模型控制,本系列後續文章會涵蓋檢索、記憶和代理迴圈。
本文也不是在論證結構化輸出就能單獨解決可靠性。它改善了一個邊界,但取代不了驗證、監控或工作流程設計。
核心觀點更窄也更務實:在你問系統需不需要 agent 之前,先問底層流程是否有清晰的階段、明確的 schema、驗證規則和受控的交接。如果沒有,增加自主性往往只會比增加能力更快地擴大失敗面。
通往檢索與基礎化的橋梁
一個結構良好的流程仍然有一個主要限制:它能用的資訊就只有它收到的佐證包。如果系統必須回答的問題涉及外部合作夥伴合約、內部訂房歷史、無障礙資料庫或先前客戶行程,那可靠性也取決於如何找到正確的佐證並把它附加到工作流程中。
這就是檢索登場的地方。下一篇文章從內部流程控制轉向基礎化(grounding):系統如何檢索正確的上下文、如何保留來源追溯,以及如何判斷該拒答而不是猜測。控制邏輯和驗證不會在那裡消失——反而變得更重要,因為檢索又多了一個階段,在這個階段裡,不好的輸入可能悄悄拉低最終答案的品質。
來源附註
本文參考以下主要與官方來源:
BAIR. "The Shift from Models to Compound AI Systems." 控制邏輯作為複合式 AI 系統核心設計選擇的參考。bair.berkeley.edu/blog/2024/02/18/compound-ai-systems
OpenAI. "Function calling." 工具呼叫作為模型輸出與應用程式端程式碼之間結構化互動的官方參考。developers.openai.com/api/docs/guides/function-calling
OpenAI. "Structured model outputs." 結構化輸出的官方參考;本文同時保留「schema 符合不代表語意正確」的限制。developers.openai.com/api/docs/guides/structured-outputs
National Institute of Standards and Technology. "Artificial Intelligence Risk Management Framework: Generative Artificial Intelligence Profile." 風險控制、評估、監控、來源脈絡與可信任部署語言的參考。nist.gov/publications/artificial-intelligence-risk-management-framework-generative-artificial-intelligence
Huang Tzu Lin
With over five years in autonomous robotics, there's a strong passion for incorporating cutting-edge technologies and innovative approaches. Dedicated to transforming the latest research and insights into practical applications, this journey pushes the limits of possibility.
相關文章
訂閱最新資訊
將最新技術洞察直接送到您的信箱。