連續批次處理:用一張 GPU 服務大量請求
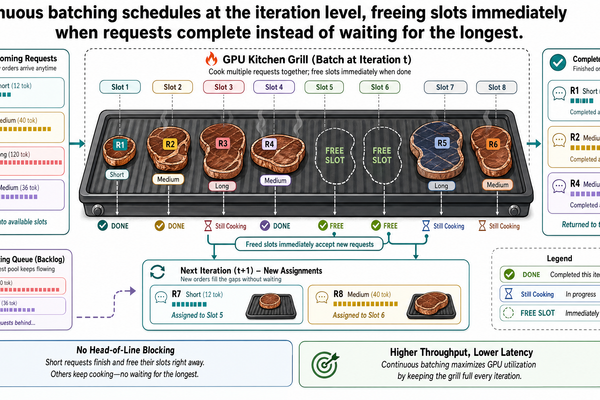
I-00 追蹤了單一請求通過推論流程的完整路徑:預填充(prefill)以平行方式處理所有輸入 token,解碼(decode)逐一生成輸出 token,而 KV 快取(key-value cache)隨著每一步不斷增長。在那篇文章的結尾,我們注意到還有 49 個其他代理人幾乎同時提交了查詢。這個觀察不是隨口帶過——它直接指向推論服務的核心運作問題。
Huang Tzu Lin
2 posts
I-00 追蹤了單一請求通過推論流程的完整路徑:預填充(prefill)以平行方式處理所有輸入 token,解碼(decode)逐一生成輸出 token,而 KV 快取(key-value cache)隨著每一步不斷增長。在那篇文章的結尾,我們注意到還有 49 個其他代理人幾乎同時提交了查詢。這個觀察不是隨口帶過——它直接指向推論服務的核心運作問題。
Post I-00 traced a single request through the inference pipeline: prefill processed all input tokens in parallel, decode generated output tokens one at a time, and the KV cache grew with every step. At the end of that trace, we noted that 49 other agents were submitting queries at roughly the sam...